ARTICLES


Best Practices In ML Observability for Customer Lifetime Value (LTV) Models
The age-old saying still holds: the customer is always right, but some are more right than others (that’s the saying, right?). While there are many metrics to estimate the value of a customer within any organization, customer lifetime value (LTV) is an important one...

How to be more confident making data model changes
For the better part of this year, we’ve been conducting interviews with data teams to help us better understand their data reliability needs, and one issue we keep hearing is about confidence. Here are a couple of points that often come up: Data teams want to be...

Debugging Python-Based Microservices Running on a Remote Kubernetes Cluster
At Modzy we’ve developed a microservices based model operations platform that accelerates the deployment, integration, and governance of production-ready AI. Modzy is built on top of Kubernetes, which we selected for its scheduling, scalability, fault tolerance, and...
Building your MLOps roadmap
As more companies wade into the AI waters and begin taking the first steps to operationalize models, they reach the point where they need to do machine learning at scale. This means scaling up your model operations. And it’s what MLOps is all about. But how do you...
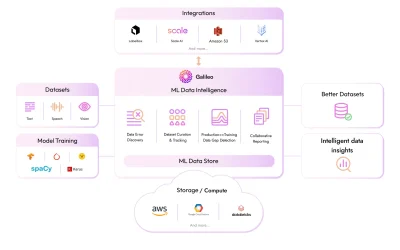
Introducing ML Data Intelligence For Unstructured Data
“The data I work with is always clean, error free, with no hidden biases” said no one that has ever worked on training and productionizing ML models. Uncovering data errors is messy, ad-hoc and as one of our customers put it, ‘soul-sucking but critical work to build...

The MLOps Stack is Missing A Layer
Deploying ML at scale remains a huge challenge. A key reason: the current technology stack is aimed at streamlining the logistics of ML processes, but misses the importance of model quality. Machine Learning (ML) increasingly drives business-critical applications...

Test your data quality in minutes with PipeRider
tl;dr If you missed out on PipeRider’s initial release, then now is a great time to take it for a spin. Data reliability just got even more reliable with better dbt integration, data assertion recommendations, and reporting enhancements. PipeRider is open-source and...
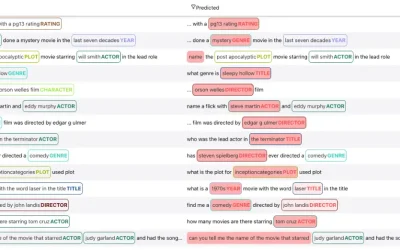
Improving Your ML Datasets, Part 2: NER
In our first post, we dug into 20 Newsgroups, a standard dataset for text classification. We uncovered numerous errors and garbage samples, cleaned about 6.5% of the dataset, and improved validation by 7.24 point F1-score. In this blog, we look at a new task: Named...

A Data Scientist’s Guide to Identify and Resolve Data Quality Issues: Doing this early for your next project will save you weeks of effort and stress
If you've worked in the AI industry with real-world data, you’d understand the pain. No matter how streamlined the data collection process is, the data we’re about to model is always messy. According to IBM, the 80/20 Rule holds for data science as well. 80% of a data...
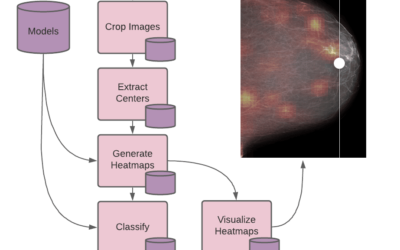
Scaling Breast Cancer Detection with Pachyderm
Introduction Breast cancer is a horrible disease that affects millions worldwide. In the US and other high-income countries, advances in medicine and increased awareness have significantly improved the survival rate of breast cancer to 80% or higher. However, in many...
Connect with Us
Follow US