
Deploying ML at scale remains a huge challenge. A key reason: the current technology stack is aimed at streamlining the logistics of ML processes, but misses the importance of model quality.
Machine Learning (ML) increasingly drives business-critical applications like credit decisions, hiring, drug discovery, predictive maintenance, and supply chain management. As ML enters new domains, the underlying technology needs are also evolving rapidly. The ability to transition models developed by data scientists into production-grade systems – in an efficient and scalable manner – has emerged as a fundamental necessity.
Productionizing ML models is complex, and MLOps practitioners have rightly looked to software engineering processes as a blueprint, seeking to adapt traditional DevOps thinking to the particular needs of ML. This has led to the emergence of an explosion of tools to streamline and automate various parts of the ML lifecycle. Collectively, this vibrant, evolving and sometimes confusing set of tools constitutes the MLOps technology stack.
Making sense of the evolving MLOps stack
While MLOps first started off with the problem of taking models from notebooks into production at scale, it has now become a collection of tools that help with things that data scientists generally don’t like to do or worry about. A wide variety of companies, tools, and open-source projects have emerged, in areas like data labeling, model and data versioning, experiment tracking, scaled-out training, and model execution.
One way to organize the seemingly disparate set of tools is to ask two questions: 1) What problem is being solved? 2) Where in the life cycle of a model is it being solved? The picture below maps the various tools in the market along these dimensions: the stage of the lifecycle (data, training, or post-deployment) and whether or not the tool is part of the compute layer or the system of record layer.
Figure 1: Typical MLOps Technology Stack Today
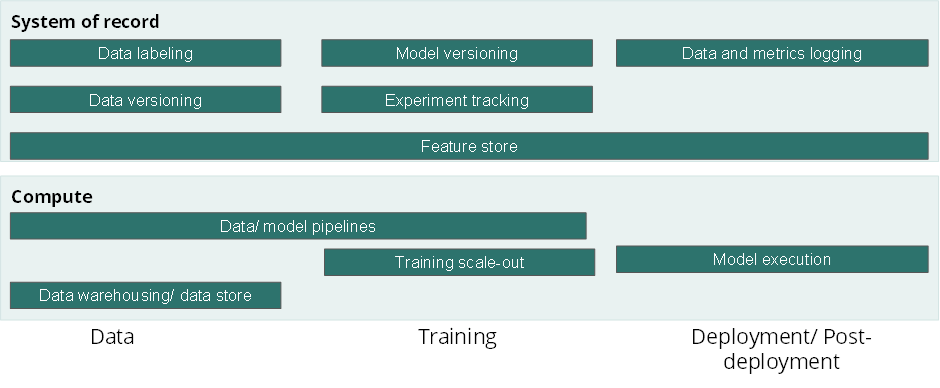
Most ML stacks today focus on “compute” and “system of record” layers across the data, training, and deployment/post-deployment phases. There’s a critical layer missing.
The missing MLOps layer: model quality
Unfortunately, for most organizations, the “influx of innovation” in MLOps has not yet translated into large-scale, real-life adoption of ML. A key reason has been that most MLOps tools so far have focused almost exclusively on the logistics of operations, on creating automated workflows to streamline the process of moving ML models from development to robust production environments.
This type of process automation is necessary, but not sufficient. It increases throughput and repeatability of the ML lifecycle but does little to ensure model quality. If we draw an analogy to software development, ML Ops today is where software engineering was a few decades ago: very few tools for testing, debugging and meaningful monitoring.
This is the missing quality layer in the MLOps stack. Without it, data scientists build ad-hoc tests; spend significant amounts of time trying to figure out what really happened when a model goes wrong at any part of the life cycle; and end up using trial-and-error methods to mitigate identified issues. Organizations can end up with highly automated “assembly-lines” that retrain and productionize ML models at pace, but with little sense of the quality of those models, and their ability to survive messy, real-life situations during their lifetime.
None of this will come as a surprise to the ML community. And yet, the strategy for building high quality models is often limited to hope and prayer. Why is that? Two reasons:
- First, industry thinking on the definition of ML quality – and how to test/ monitor/ debug for it – is still in its early stages. Traditionally, the focus has been on the predictive accuracy of models using test/ OOT data. More recently, other symptoms of poor model quality, such as unjust bias, have received interest from regulators and practitioners. However, as we have argued in a separate blog, a holistic approach is needed to cover the full set of factors that contribute to ML quality, including transparency, justifiability/ conceptual soundness, stability, reliability, security, privacy and, of course, the underlying data quality.
- Second, compared to traditional software, ML systems are characterized by greater uncertainty, as models make predictions based on patterns learnt from potentially incorrect, incomplete, or unrepresentative real-world data. The ML lifecycle also involves more iterations and greater interdependencies between stages – for example, the detection of poor performance in one segment may necessitate incremental data sourcing and/or re-sampling further back in the cycle.
Not surprisingly, it has been easier to focus MLOps efforts to date on the simpler problem of automating the mechanical process steps involved in building and deploying a model. There are good reasons for this: there are well-established precedents in place from the world of traditional software engineering, and outcomes are easily measurable – e.g., time taken to move from one stage in the lifecycle to the next.
So what does a more effective MLOps stack look like?
A more complete and effective version of the MLOps tech stack would have a “system of intelligence” layer at the top, dedicated to ensuring ML quality throughout the lifecycle.
Figure 2: Assuring ML Quality throughout the lifecycle
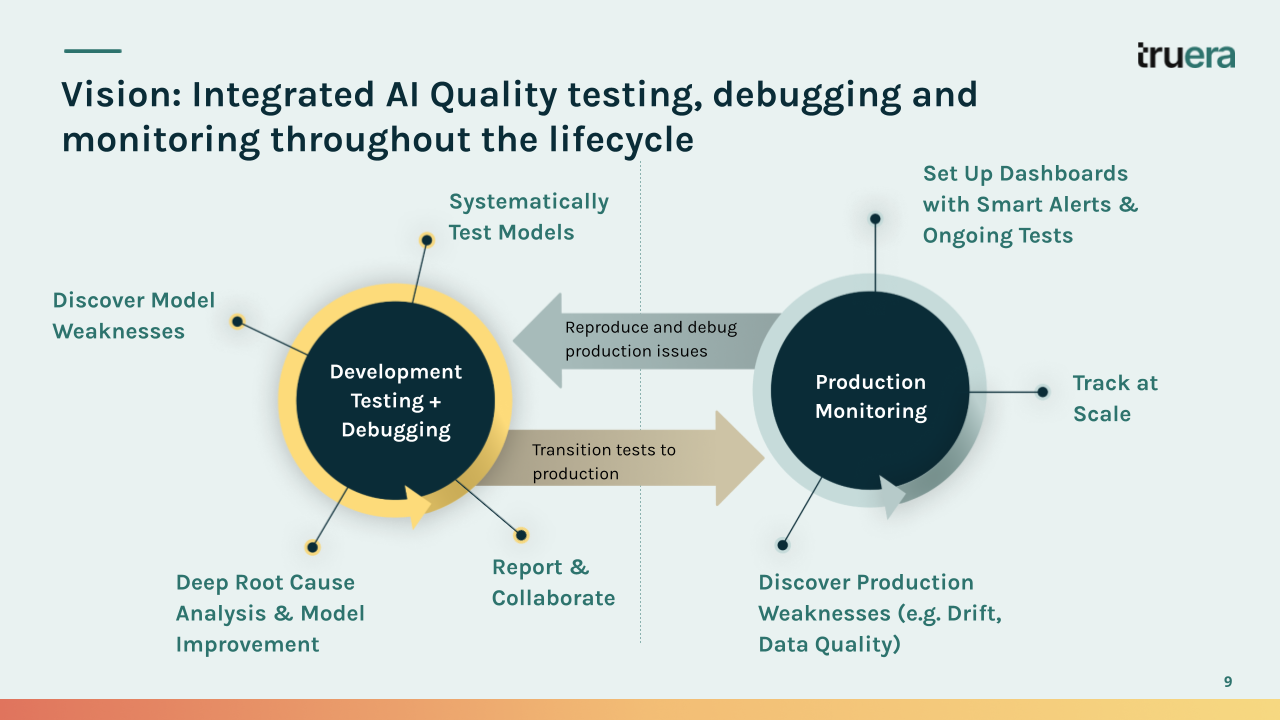
A system of intelligence layer allows teams to manage and improve ML quality in both the development and production parts of the model lifecycle.
Organizations that build with an ML Quality first approach can achieve greater predictability in their efforts to productionize models that are effective, reliable, and stable. Data scientists can follow a more streamlined development workflow for building, evaluating, and refining models. Teams with operational responsibility for the models in production will have the tools to keep an eye on changes in the model’s behavior and accuracy over time. Behavior and accuracy are both underpinned by holistic ML quality tests, extensive root cause analysis, and rapid debugging capabilities.
***
To enable large-scale positive impact in real-life use cases, MLOps must focus as much on model quality as they do process efficiency. The more serious the financial and human cost of incorrect predictions – e.g., if the outputs from an ML model can result in denying someone a job, insurance coverage, a mortgage or social security benefits – the higher the bar is for the quality of that model. The good news is that the MLOps stack is evolving to meet this challenge, and solutions that fit this quality layer are being increasingly deployed.
Authors: Shameek Kundu, Head of Financial Services and Chief Strategy Officer of TruEra and Shayak Sen, CTO and Co-Founder of TruEra
This post was originally published in Analytics Magazine.
This blog has been republished by AIIA. To view the original article, please click here: https://truera.com/the-mlops-stack-is-missing-a-layer/
Recent Comments