AI Infrastructure Ecosystem of 2022
With hundreds of AI/ML infrastructure tools on the market, how do you make sense of it all?
Which parts of the stack are mature? How do you know where to invest your precious time and resources to get the best results for your rapidly growing team of data engineers and data scientists?
Our first annual AI Infrastructure Ecosystem report answers these questions and more. It gives team leads, technical executives and architects the keys they need to build or expand your infrastructure by providing a comprehensive and clear overview of the entire AI/ML infrastructure landscape.
Get it now. FREE.

Report Preview
Check Out the First Section Below
Agents, LLMs and the New Wave of Smart Apps
When you hear the word Agent, you might think of 007 or Jason Bourne. They can fight crime with one hand, down a Martini with the other, and always look stylish doing it.
But since the release of ChatGPT, we've seen an explosion of a new kind of agent. AI Agents are intelligent programs that can interact autonomously or semi-autonomously with their environment.
Actually, the definition of Agents is still evolving at the moment. The traditional definition is any autonomous software that tries to achieve its goals, whether in the digital world or physical world or both. It's got sensors that "see" and "hear" and "sense" its environment. It's got "actuators," a fancy word for the tools it uses to interact with the world, whether that's an LLM using an API the way we use our hands and fingers, or whether it's a robotic gripper picking up trash or a self-driving car sensing the environment with LIDAR.
But Large Language Models (LLMs) like ChatGPT and GPT-4, based on the ultra-popular Transformer architecture, changed what is possible with Agent capabilities. For the first time they give us little "brains" that are capable of a wide range of tasks from planning and reasoning, to answering questions and making decisions that were impossible with earlier models.
LLMs have a number of well known flaws, such as hallucinations, which essentially boils down to making things up, to ingesting the biases of the dataset it was trained on, all the way to an LLM having confidence in wrong answers because of a lack of grounding. Grounding means that the model can't link the text it's generating to real world knowledge. It may not know for a fact that the world is round and so occasionally hallucinates that it's flat.
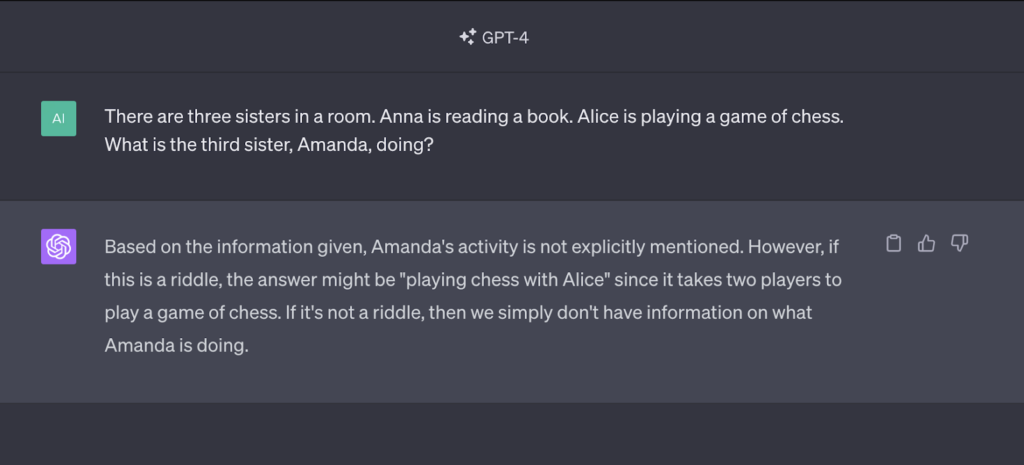
But despite all these imperfections LLMs remain very powerful tools. We asked GPT-4 a logic teaser question and it gave us the right answer out of the gate, something smaller LLMs struggle with badly and that no hand written code could deal with on its own without knowing the question in advance.
A recent report from Andreessen Horowitz on emerging LLM stacks sees Agents as purely autonomous pieces of software. That means they can plan and make decisions totally independent of human intervention.
At the AI Infrastructure Alliance (AIIA), we define Agents a bit differently. We see them as both semi-autonomous software with humans making some of the decisions, aka humans in the loop, as well as fully autonomous systems too. We also think it's essential that people understand that an Agent is not usually a singular, self contained piece of software, such as the LLM itself. We hear the word Agent and it calls to mind a complete entity that is self contained, mostly because we anthropomorphize them and think of them as human, since people are the only benchmark we have for true intelligence.
Usually Agents are a system of interconnected software pieces. The HuggingGPT paper from a Microsoft Research team outlines a common and practical approach to modern agents, where an LLM uses other models, like an image diffuser, such as Stable Diffusion XL, or a coding model like WizardCoder, to do more advanced tasks. It may also use APIs the way we use our hands and legs. It uses those tools as an extension to control outside software or interact with the world. To do that an LLM might train on its own API knowledge as part of its dataset or a fine-tuned dataset or it might use another external model explicitly trained on APIs, like Gorilla.
At the AIIA, we see Agents and any software system that interacts with the physical or digital world and that can make decisions that were usually only in the realm of human cognition in the past.
- We call semi-autonomous agents: Centaurs. These are intelligent software with a human in the loop.
- Agents are fully autonomous or almost fully autonomous pieces of software that can plan and make complex decisions without human intervention.
We can think of a Centaur as a "Agents on rails", a precursor to fully autonomous Agents. Centaurs can accomplish complex tasks as long as they're well defined with clear guardrails and as long as someone is checking their work or intervening at various steps along the way.
Agents that are fully autonomous and can do their job with no human intervention.
A good example of the levels of autonomy in agentic systems comes from the world of self-driving cars and is beautifully laid out in the book AI 2041 by Kai-Fu Lee and Chen Quifan. Autonomous systems are classified by the Society of Automotive Engineers as Level 0 (L0) to Level 5 (L5):
- L0 (zero automation) means the person does all the driving but the AI watches the road and alerts the driver to potential problems such as following another car too closely.
- L1 (hands on) means the AI can do a specific task, like steering, as long as the driver is paying close attention.
- L2 (hands off) is where the AI can do multiple tasks like braking, steering, accelerating and turning, but the system still expects the human to supervise and take over when needed.
- L3 (eyes off) is when an AI can take over all aspects of driving but still needs the human to be ready to take over if something goes wrong or the AI makes a mistake.
- L4 (mind off) is where the AI can take over driving completely for an entire trip, but only on well defined roads and in well developed environments that AI understands very well, like highways and city streets that have been extensively mapped and surveyed in high definition
- L5 (steering wheel optional) means that no human is required at all, for any roads or environment and you don't need to have a way for humans to take over, hence the "steering wheel" optional.
We can think of L0 to L3 as nothing but an extra option on a new car, like air conditioning or leather seats or cruise control. They still need humans at the wheel. These are Centaurs in that they need humans in the loop, like most Agents today. Most people would be very reluctant to let an Agent compose an email to their boss or their mother without reading it before sending it.
But by the time we get to L4, the intelligence behind the car starts to feel like a true intelligence with a mind of its own and it will have a massive impact on society. L4 cars or buses might be public transport that take very specific public routes confidently, while an L5 car or truck might do deliveries at all hours of the day or be a robot taxi like Uber that can take you anywhere.
Since the release of GPT 3 and GPT 4 we've seen a number of attempts to build fully autonomous L5 style Agents for the digital world, such as BabyAGI and AutoGPT, as well as a slew of others. Programmers have looked to leverage LLMs to take actions like planning complex software requirements, booking plane tickets based on user requests, picking out presents for a birthday party or planning out company hiring plans.
Unfortunately, they mostly don't work yet for long term planning, reasoning and execution of complex tasks. We imagine AI systems that can come up with a comprehensive marketing plan for a new product, write and create the website, craft all the outreach messages, get the list of people to reach out to and then send the emails to get new customers. We are not there yet but that doesn't mean they won't at some point. With so many traditional programmers getting into machine learning and applying ideas that data scientists and data engineers wouldn't think of because it's outside their domain knowledge, we're seeing improvements constantly in these systems and fully autonomous Agents could be a ubiquitous facet of all our lives in the near future or over the next decade.
Many of these fully autonomous projects sparked tremendous public interest. AutoGPT racked up GitHub stars faster than almost any project in history but we can no longer take GitHub stars as a true measure of software prowess. The tremendous public interest in AI, which is often driven by sci-fi novels and Hollywood blockbusters and not by the actual reality of the current state of the technology. That outside interest sometimes drives brand new projects to the Github star stratosphere, only to see actual developer interest in those projects crumble soon after. That happens when cognitive dissonance sets in and the software doesn't end up matching people's expectations of a super-intelligent software avatar, like the AI in the fantastic movie Her.
Still, some of those projects continue to attract ardent followers who continue to add new capabilities, such as with BabyAGI. Not only that but reasoning and planning for Agents continues to evolve with software and research projects that incorporate new techniques to help the LLMs think better, such as Chain of Thought prompting, or giving them a history that they can recall with projects like the Generative Simulacra from a team out of Stanford, which "extends a large language model to store a complete record of the agent's experiences using natural language, synthesize those memories over time into higher-level reflections, and retrieve them dynamically to plan behavior."
Despite all these techniques they still struggle with going off the rails and hallucinating and making major mistakes in their thinking, especially as the time horizon for independent decision making increases. Short term, on-the-rails reasoning is often sound but the longer the agents have to act and make decisions on their own the larger their chance of breaking down.
Even with all these limitations and caveats, Agents have gotten more powerful. Why have Agents suddenly gotten much more powerful? The answer is simple. ChatGPT was a watershed moment in computing and AI history that shocked outsiders and insiders alike.
Suddenly, we had a system that delivered realistic and free flowing conversations on any subject at any time. That's a radical departure from the past where chatbots were brittle and not even vaguely human. The first chatbot, ELIZA, was created in the 1960s at MIT. We've had Clippy, the famous paperclip in Microsoft Office products in the late 90s and early 2000s that was notorious for being slow and virtually useless for answering any questions at all. We've had Alexa and Siri which can do things like play songs or answer questions by doing lookups in a database. But none of them really worked all that well.
ChatGPT and GPT-4 just feel different.
That's because all these bots of the past were often brittle rule based systems. They were glorified scripts that triggered based on what you said or wrote. They couldn't adapt to you or your tone or writing style. They had no real context about the larger conversation you'd had with them. They felt static and unintelligent. Nobody would mistake them for humans.
The architecture of GPT-4 is a secret, though we know its based on transformers. We'd had speculation that it's a massive transformer with a trillion parameters of that it's not a big model at all but 8 smaller models, known as a Mixture of Experts (MoE), which leverages a suite of smaller expert models to do different tasks. Whatever the actual architecture of the model is, which we will only know when its architecture is officially made public, it's a model that's more powerful and capable than any other model on the market and it remains the high water mark as of the time of this writing. Even with models like Meta's open source marvel Llama 2 that came out a year later can't seem to replicate its performance, though they approach it.
That said, it's only a matter of time before other teams create a more powerful model. By the time you read this the arms race to create ever more powerful models by open source teams like Eleuther AI and Meta's AI research division, or by any of the proprietary companies piling up GPUs to build their own models, like Google, Anthropic, Cohere, Inflection, Aleph Alpha, Mistral and Adept may already have produced that model.
With more powerful software brains powering today's Agents, we have much more powerful systems at hand. They're the engine that drive Centaurs and Agents to much more useful capabilities. Unlike the relatively limited capabilities of enterprise Robotic Process Automation (RPA) of the past, that were typically limited to well defined processes and structured data, we have Agents and AI driven applications that can work in the unstructured world of websites, documents and software APIs. These Agents can summarize websites with ease, understand what's going on the text, offer an opinion, act as language tutors and research assistants and much, much more.
It's really only the beginning. ChatGPT was the starting point but not the end game. Since GPT, we've had a surge of capable open source models. Hugging Face tracks them with an open suite of tests on a leaderboard for open source models. It seems like every week a new open source model takes the crown. We've seen Meta's LLaMA and Llama 2, along with Vicuna, Orca, Falcon, not to mention specialized models like Gorilla that specializes in working with APIs.
Venture capital is pouring into foundation model companies so they can spin up massive supercomputers of GPUs. OpenAI attracted over 10B USD in investments and recently Inflection AI announced 1.3B USD in funding to create a 22,000 strong Nvidia H100 cluster to train their latest models. With all that capital, OpenAI will not remain the only game in town. At the AIIA we expect a massive flurry of capable models to power the intelligence apps of today and tomorrow.
Agents offer a potentially new kind of software that's beyond the capabilities of traditional hand coded software written by expert programmers. The power of these LLMs and the middleware that's rising up around them makes it possible for very small teams to build highly capable AI driven applications with one to ten people. It's an extension of the WhatsApp effect, where a small team of 50 developers was able to reach 300M people with their application because they were able to leverage an ever increasing stack of sophisticated pre-baked software to build their platform, everything from ready-made UIs to secure encryption libraries.
The power of LLMs, along with a suite of models that do a particular task very well, like SAM (Segment Anything Model), Stable Diffusion, Gen1 and Gen 2, coupled with a new generation of middleware is making it possible for even smaller teams to reach a wider audience. The bar to building great software has lowered again and history shows that whenever that happens we see a flurry of new applications.
It's also possible to build smaller, more focused apps now, like a bot that can ingest a series of legal documents and answer questions about what jurisdictions a company might face lawsuits in, an app that can research a massive amount of companies and tell you which ones are good for your marketing team to contact, or an app that can ingest news articles, write summaries of them and create a newsletter. Stacking these agents together holds the potential of creating intelligent microservices that can deliver new kinds of functionality.
With state of the art LLMs behind the scenes that are broadly capable and able to power agents whose sensory input from keystrokes, web pages, code, external models and knowledge repositories, we now have Agents that can do things we only saw in the movies, like automatically upscale photos and add detail to them that was hidden or missing, reason about what is on a web page or in a PDF document and make complex decisions. An old writer's trope in every detective show is where the cops find some grainy VHS footage and their computer team ‘enhances' that footage to get the next big clue in the case. That was basically impossible but now we have systems that are a lot like the Bladerunner scene where Detective Deckard, played by Harrison Ford, takes an old photo, puts it into an analysis machine, talks to the machine and tells it what to do, and the machine enhances the photo to bring out hidden spots.
We've gone from only robotics researchers and data scientists building Agents, to traditional programmers building Agents to do complex tasks that were impossible only a short time again with hand written code and heuristics.
But despite all these amazing new capabilities none of this is without its challenges. LLMs are non-deterministic systems and they don't always behave or act in a way that's predictable. A traditional hand written piece of software can only fail in so many ways. If we have a subroutine that logs a user into a website there are only so many ways it can go wrong. But LLMs and other models can produce wildly unpredictable results from task to task. A diffusion model like Stable Diffusion XL might excel at creating photorealistic portraits but fail miserably at making a cartoon style painting of a cute robot. Even worse, because these systems are so open ended, there is no real way to test all of the possibilities that someone might use them for on a given day. One user might ask the LLM simple questions about how to make a good dinner for their wife, while another might try to trick it into revealing security information, while still another might ask it to do complex math.
Wrangling these systems to create useful software is an ongoing challenge. So lets dive in and look at the promises and perils of LLMs, Generative AI and Agents for both small business and enterprises. We'll start with the new emerging stack that's enabling people to create these applications and then move on to challenges every company or person looking to adopt or build these systems will face.
Key Charts

We’ve discovered that the teams surveyed often faced their biggest challenges with collecting the data they need along with cleaning, QAing and transforming that data, which falls squarely on the shoulders of data engineers.

That’s reflected in the composition of teams as well. Most companies surveyed employed more data engineers than data scientists. It’s also reflected in where teams are spending the most time and money.

Only 26% of teams we surveyed were very satisfied with their current AI/ML infrastructure. 55% percent were only somewhat satisfied, while 17% were somewhat unsatisfied, and 3% were very unsatisfied. In other words, most teams see a lot of room for improvement.
Get it Now!
And start planning for the future, today.
