
by YData | Apr 13, 2022 | Uncategorized
Photo by v2osk on Unsplash In classification a central problem is how to effectively learn from discrete data formats (categorical or ordinal features). Most datasets present us with this problem so I guess it is fair to say that almost all data scientists have...

by Iguazio | Apr 11, 2022 | Uncategorized
In a world of turbulent, unpredictable change, we humans are always learning to cope with the unexpected. Hopefully, your machine learning business applications do this every moment, by adapting to fresh data. In a previous post, we discussed the impact of...

by Superb AI | Apr 8, 2022 | Uncategorized
Computer vision applications, in specific, and machine learning applications, in general, rely heavily on data to train the models. In production systems, input data is fed into the model to make inferences. These production systems then use the inference outputs as...
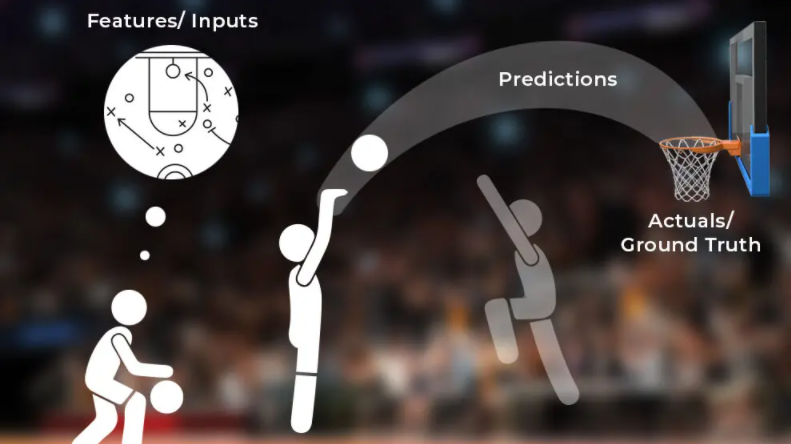
by Arize AI | Apr 6, 2022 | Uncategorized
In the latest edition of “The Slice,” a blog series from Arize that explains the essence of ML concepts in a digestible question-and-answer format, we dive into different types of drift – including concept drift vs data drift. When data science and engineering teams...

by Modzy | Apr 4, 2022 | Uncategorized
Learn how a novel approach to explainability based on adversarial machine learning can be used to explain the predictions of deep neural networks, powered by a single GPU Tesla V 100-SXM2 to produce better results faster than LIME and SHAP. This talk covers our...

by Superb AI | Apr 1, 2022 | Uncategorized
Introduction In computer vision and machine learning operations, data labeling is an essential part of the overall workflow. For reference, data labeling is the process by which raw images, video, or audio files are identified and annotated individually for machine...
Recent Comments