In the latest edition of “The Slice,” a blog series from Arize that explains the essence of ML concepts in a digestible question-and-answer format, we dive into different types of drift – including concept drift vs data drift.
When data science and engineering teams take a machine learning model from research to production, it is impossible to tell how it will perform in the real world. Teams are in the dark on whether their models will perform as expected in training or if the model’s performance will start to degrade in response to changing environments. As machine learning (ML) models become increasingly complex, it is imperative for ML teams to utilize state-of-the-art ML observability tools in order to troubleshoot, triage and resolve issues in production environments. Without an ML observability platform in place, it is very difficult to diagnose production issues that are causing a negative impact on your model’s performance, especially if that model doesn’t get ground truths back for a set period of time. In this blog, we investigate the root causes of data and model drift in order to mitigate the impact of future performance degradations.
Let’s imagine you are a machine learning engineer at a large cable and internet service provider and it is your job to write an algorithm to predict how many customers will churn next month. In order to create this, you will need to train a regression model that will take in user and product features and predict a score (or likelihood) that a customer will terminate service. If you run this model today, you will have prediction scores for the next month as well as a decision on whether or not the customer will churn based on a score threshold (likelihood > 70% gives label = ‘churn’) but you will not have the ground truth of whether the customer actually churned until the end of the month.
So what can you do in the meantime – and what can potentially happen in that month? Let’s investigate…
During the next 30 days, you are unable to have a clear and complete understanding of how your model is performing since you cannot compute success metrics until the results come back at the end of the month. However, you are not without tools to use as a proxy for performance. In addition to monitoring your data quality, you can also gain insights by monitoring for drift.
What Does Drift Mean In the Context Of ML Observability?
Drift is calculated by comparing two distributions over time. These distributions can be from training, validation or even production data. We quantify drift by measuring the distance between various distributions. When these distributions start to diverge, it results in various forms of drift. Ultimately, when models drift due to changes in the environment it is likely to indicate a degradation of a model’s prediction power over time. While this blog does not discuss how drift is calculated, those interested can consult Arize’s paper on Using Statistical Distances for Machine Learning for a deeper dive on the topic.
What Is Model Drift?
Model drift refers to a change in what the model is predicting today versus what it has predicted in the past, or a drift in the model’s predictions. For example, maybe this month your churn model starts to predict a higher churn of your customers than last month (without changing the model offline). While model drift specifically refers to a drift in the predictions, model drift or model decay generally also refers to when your model gets worse at making correct predictions from new or incoming values when compared to its prediction power pre-production.

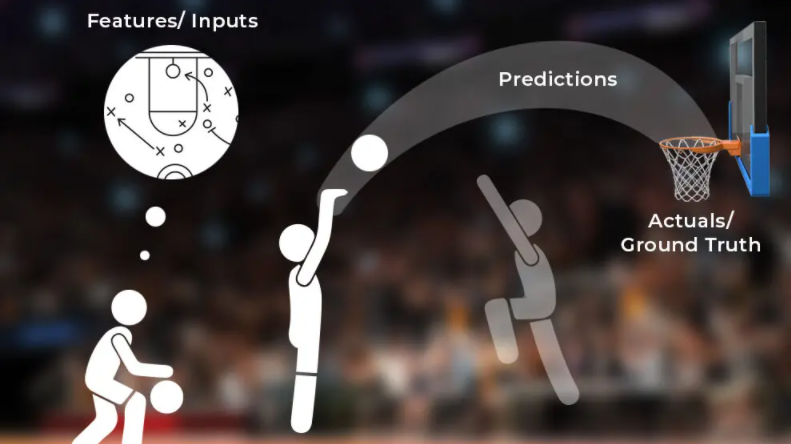
Here is a fun way of visualizing this; let’s imagine a basketball court where:
- A basketball player is the model, with their own neural network working to predict how to score.
- Shots represent the predictions.
- When players line up a shot, they are pulling information from all the variables in order to make the best prediction possible. These variables – like angle, position, offensive schemas, defensive position and speed – represent the features/inputs.
- Lastly, the hoop represents the actuals or the ground truth.

Model drift (drift in the predictions), then, would be the trajectories overshooting their target, like how our churn model might overshoot the monthly churn prediction of customers. In other words, model drift turns three pointers into balls that sail over the backboard.
Some ways to combat model drift include retraining a model with additional data or replacing the model, but the first method to resolve model drift is to diagnose the cause and type of drift. Since there are several categories of drift, it’s worth diving into each.

Concept Drift
- Definition: Concept drift is the shift in the statistical properties of the target/dependent variable(s), i.e a drift in the actuals. Specifically, the drift of current ground truths from previous ground truths from a prior time window or training dataset.
- Real-world example: Your churn model could start to drift if a global pandemic makes it more difficult for customers to pay for service. Therefore your model may drastically underestimate churn.
- Basketball metaphor: The ball misses because the hoop, which represents actuals, moves. While this is uncommon in basketball, one could imagine a scenario where an earthquake at a Golden State Warriors game causes the hoop to move after a player takes a shot. Alternatively, perhaps an overzealous defender mistimes a rebound and hangs on the rim to avoid landing on another player’s back – causing the shot to brick since the rim is temporarily bent downward (technically, this would be goaltending and points would be awarded to the offense by default in this scenario; if only this were true for actual concept drift!).

Data Drift / Feature Drift / Covariate Drift / Input Drift
- Definition: Data drift, feature drift, covariate drift and input drift all refer to a shift in the statistical properties of the independent variable(s), i.e. a drift in the feature distributions and the correlations between variables. This drift can result in data changes due to seasonality, consumer preferences, the addition of new products or other factors.
- Example: Returning to the churn model, data drift might occur if users decide to cut back on their cable subscriptions due to a new popular show on a channel that the company’s service does not carry.
- Basketball metaphor: The ball boy, who also mops sweat off the floor between plays, doesn’t show up for work and the floor is slick for the entirety of the game. A player who has never played on a slippery surface now has to make his shots with a new and unknown input in the form of a slippery floor (and ball) against erratic defenders. Since the features changed, the player’s field goal percentage takes a dive.

Upstream Drift
- Definition: Upstream or operational data drift refers to drift caused by changes in the data pipeline, this might result in a spike in missing values or changes in a feature’s cardinality.
- Example: Your churn model could start to drift if the user feature “last_months_bill” amount starts to be recorded in Euros (EUR) instead of the usual American Dollars (USD).
- Basketball metaphor: A basketball player subs into the game, gets an inbound pass and takes an open shot – with a soccer ball? The shot does not go as expected.
Now that we understand the various forms of drift, it’s important to understand how to track this in your models. So let’s revisit the question: “what can you do in the meantime while we wait for actuals?” We now know that we must troubleshoot the various forms of drift and resolve accordingly in order to optimize our model performance, mitigate the impact of future performance degradations and ultimately improve the business KPIs and reduce customer churn.
In practice, this often follows a four-step process:
- Issue Detected: What alerts and monitors are triggered?
- Check Model Drift: Are the predictions drifting?
- Check Concept, Feature, Concept and Upstream Drift: Are there underlying changes in ground truth, inputs, or the data pipeline?
- Begin Resolution: How can the data be fixed through targeted upsampling to improve model performance? Does the model need to be retrained?
See “Take My Drift Away” for a deep dive on how to measure and fix drift in your machine learning models.
Arize is an ML observability platform that helps ML teams better manage model performance, monitor drift and ultimately troubleshoot and resolve issues in production. If you would like to test Arize for monitoring drift in your use cases, please request a trial here.
This blog has been republished by AIIA. To view the original article, please click HERE.
Recent Comments