by Galileo | Sep 6, 2022 | Uncategorized
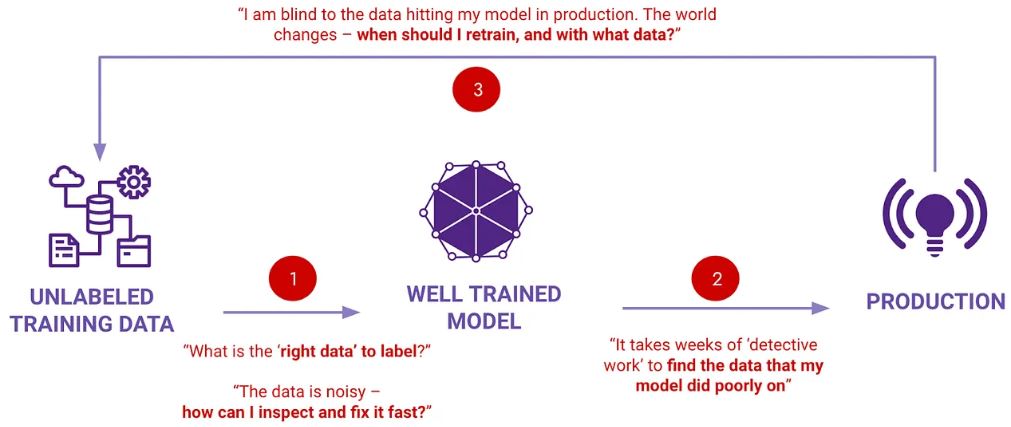
In this article, founder and CEO of Galileo Vikram Chatterji discusses the problems with ML data blindspots and introduces ML Data Intelligence that helps an ML team holistically understand and improve the health of the data powering ML across the organization. As a...

by YData | Sep 2, 2022 | Uncategorized
I’m not going to list Pandas, NumPy, Scikit-learn, Matplotlib, Seaborn, TensorFlow, PyTorch, etc. You probably know about these already. There is nothing wrong with these libraries; they’re already the bare minimum essential for data science using python. And the...

by Iguazio | Aug 31, 2022 | Uncategorized
Many organizations are turning to Snowflake to store their enterprise data, as the company has expanded its ecosystem of data science and machine learning initiatives. Snowflake offers many connectors and drivers for various frameworks to get data out of their cloud...

by DataTalks | Aug 29, 2022 | Uncategorized
An overview of what DevOps and MLOps have in common and what are their differences (if any). About ten years ago, the community realized that there was a barrier between the delivery and operations teams. On the one hand, there was the development team, which was...

by Modzy | Aug 26, 2022 | Uncategorized
Data drift occurs when a model sees production data that differs from its training data. If a model is asked to make a prediction based upon drifted data, the model is unlikely to achieve its reported performance. This phenomenon happens because during training, a...
by Aporia | Aug 24, 2022 | Uncategorized
We’ve all been there. You’ve spent months working on your ML model: testing various feature combinations, different model architectures, and fine-tuning the hyperparameters until finally, your model is ready! Maybe a few more optimizations to further improve the...
Recent Comments