
by Galileo | Nov 28, 2022 | Uncategorized
In our first post, we dug into 20 Newsgroups, a standard dataset for text classification. We uncovered numerous errors and garbage samples, cleaned about 6.5% of the dataset, and improved validation by 7.24 point F1-score. In this blog, we look at a new task: Named...

by Galileo | Oct 24, 2022 | Uncategorized
In this article, co-founder and CTO of Galileo Atindriyo Sanyal gives a fascinating overview of the ‘ML data intelligence’ evolution and shares a few insights on why the organizations that obsess on their ML data quality will quickly greatly outperform those that...
by Galileo | Sep 6, 2022 | Uncategorized
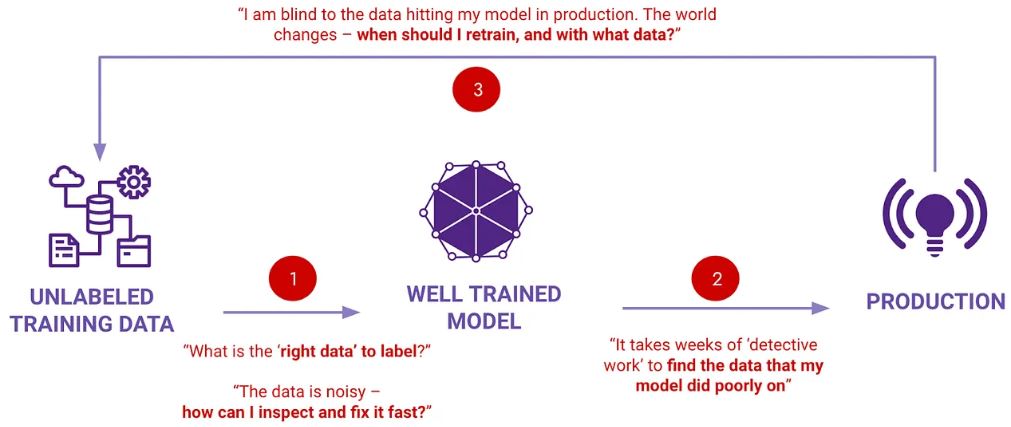
In this article, founder and CEO of Galileo Vikram Chatterji discusses the problems with ML data blindspots and introduces ML Data Intelligence that helps an ML team holistically understand and improve the health of the data powering ML across the organization. As a...
Recent Comments