
Many organizations are turning to Snowflake to store their enterprise data, as the company has expanded its ecosystem of data science and machine learning initiatives. Snowflake offers many connectors and drivers for various frameworks to get data out of their cloud warehouse. For machine learning workloads, the most attractive of these options is the Snowflake Connector for Python. Snowflake added some new additions to the Python API in late 2019 that improved performance when fetching query results from Snowflake using Pandas DataFrames. In their blog post just a few months later, internal tests showed a 10x improvement if you download directly into a Pandas DataFrame using the new Python client APIs.
In this article, we’re going to show you how to use this new functionality.
Install the Snowflake Connector Python Package
pip install snowflake-connector-python[pandas]
The snowflake connector needs some parameters supplied so it can connect to your data. Snowflake user, password, warehouse, and account all need to be supplied. In our code examples you will see these params given as **connection_info for brevity. Below is a very simple example of using the connector. This uses the fetch_pandas_all() function, which retrieves all the rows from a SELECT query and returns them in a pandas dataframe. To be clear, this does not replace the pandas read_sql() method, as it only supports SELECT statements.
import snowflake.connector as snow
ctx = snow.connect(**connection_info)
query = "SELECT * FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.CUSTOMER"
cur = ctx.cursor()
cur.execute(query)
df = cur.fetch_pandas_all()
This example works fine for smaller datasets, specifically those that fit into memory. This gets tricky when that data is too large for a single pandas dataframe to hold. This is where the power of Dask comes in. Dask is a distributed framework that natively scales Python. Since Python already dominates data science and machine learning technologies, Dask is a natural transition and extends much of what developers already know. If you are used to working with pandas dataframes or numpy arrays, the APIs will seem almost identical because Dask sets out to mimic the larger Python ecosystem of popular tools. Dask also has a distributed dataframe that is made up of many pandas dataframes, which can hold data across a Dask cluster on many workers, and on disk if needed. For a deeper look into Dask dataframes and how amazing they are, check out their docs.
Luckily for us, the Snowflake Connector for Python supports distributed frameworks as well. Using the get_result_batches() method, which returns a list of ResultBatch objects that store the function to retrieve a specific subset of the result, we can use Dask workers to split the query and distribute the processing in parallel. Each worker will read its own slice of the data into a pandas dataframe, and all those dataframes, wherever they reside in the cluster, will constitute the Dask dataframe. We then supply this list of Dask delayed objects to a Dask dataframe using the from_delayed() function. An important note on Dask delayed functions: these are lazy functions and defer execution to a task graph, which is how the Dask scheduler can exploit opportunities to parallelize the workload. To designate a function as a Dask delayed function, you simply use the @delayed annotation.
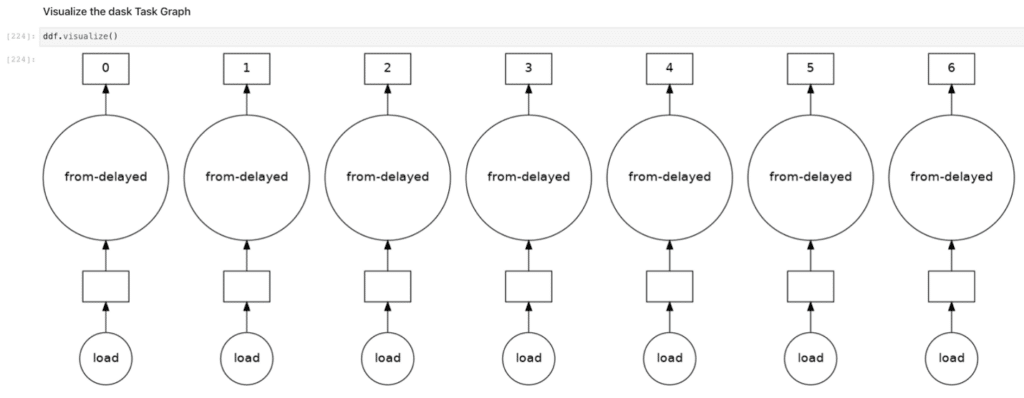
Below is some code that demonstrates how to use Dask to read big data from Snowflake in a distributed and parallel fashion. We will assume you already have a Dask cluster setup and access to Snowflake.
import snowflake.connector as snow
import numpy as np
from dask.distributed import Client
from dask.dataframe import from_delayed
from dask import delayed
@delayed
def load(batch):
try:
print("BATCHING")
df_ = batch.to_pandas()
return df_
except Exception as e:
print(f"Failed on {batch} for {e}")
pass
def load_delayed(connection_info, query):
# Assume you have a DASK cluster up and running
client = Client()
# Connect to Snowflake and execute our query
conn = snow.connect(**connection_info)
cur = conn.cursor()
cur.execute(query)
# Our result set is partitioned into a list of ResultBatch objects
batches = cur.get_result_batches()
# Now we can iterate over this ResultBatch list, load each partition of the data into a pandas dataframe using a DASK delayed function, and append all of those delayed objects to our empty dfs list
dfs = []
for batch in batches:
if batch.rowcount > 0:
df = load(batch)
dfs.append(df)
# This list of delayed objects is supplied to the DASK from_delayed function, which creates a DASK dataframe from all of the objects. This dataframe is distributed
ddf = from_delayed(dfs)
# Save the DASK dataframe to the cluster, triggering the delayed functions to execute
ddf.persist()
return ddf
Now that we have our functions defined, we can create our Dask dataframe. Here is an example using some sample data from the Snowflake sample database.
ddf = load_delayed(connection_info=connection_info,
query="SELECT * FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF100.CUSTOMER LIMIT 30000")
Dask gives us some tools that we can use to verify our workloads in the cluster. When the Dask distributed scheduler starts, the link to the dashboard will be displayed if you are running in Jupyter. You can also get the link from the object client.dashboard_link. Below we see some screenshots from the Dask dashboard of our distributed fetch and how the workload was split up among Dask workers.
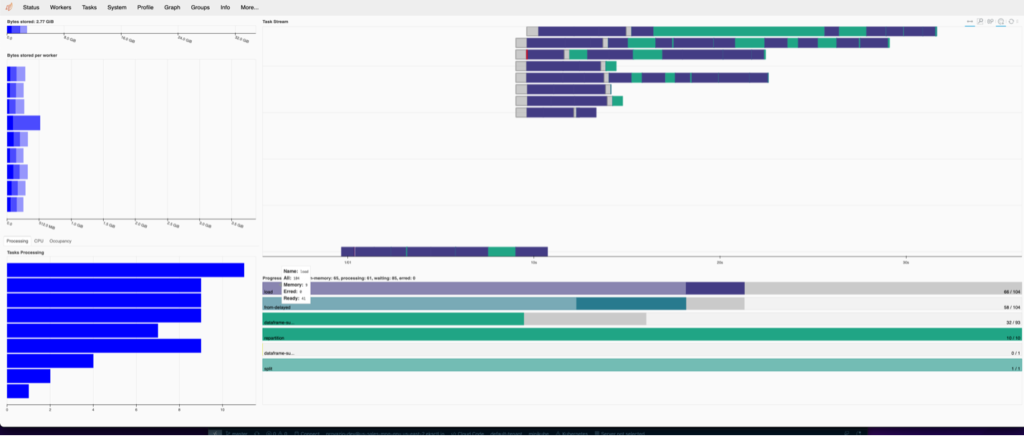
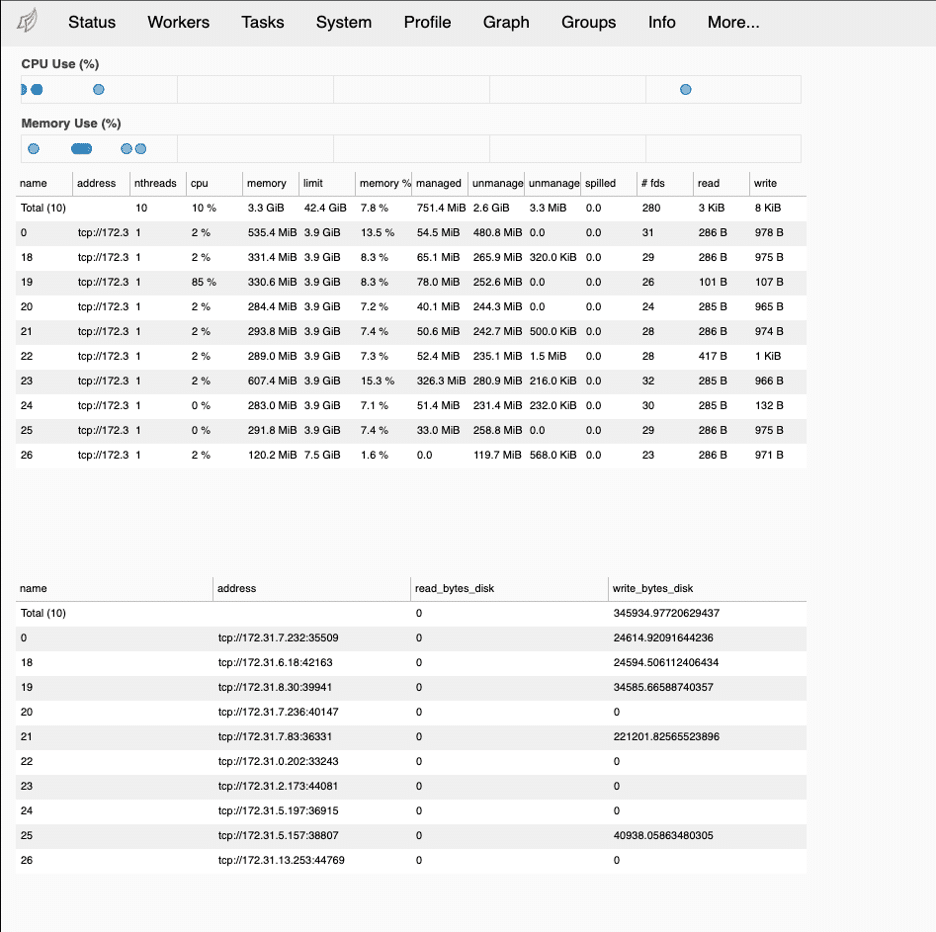
One thing to be aware of is the data types from Snowflake and how they convert when written to a Dask (and underlying Pandas) dataframes. For convenience we provided a table below that is accurate to date, but it’s always a good idea to check the docs on whatever version of the Snowflake Connector for Python you are using for accurate data mappings.
| Snowflake Data Type | Pandas Data Type |
| FIXED NUMERIC type (scale = 0) except DECIMAL | (u) int {8, 16, 32, 64} or float64 (for NULL) |
| FIXED NUMERIC type (scale > 0) except DECIMAL | float64 |
| FIXED NUMERIC type DECIMAL | decimal |
| VARCHAR | str |
| BINARY | str |
| VARIANT | str |
| DATE | object (with datetime.date objects) |
| TIME | pandas.Timestamp (np.datetime64[ns]) |
| TIMESTAMP_NTZ, TIMESTAMP_LTZ, TIMESTAMP_TZ | pandas.Timestamp (np.datetime64[ns]) |
In this blog we showed how to use the Snowflake Connector for Python to fetch results from Snowflake directly into Pandas DataFrames, and in the case of much larger queries, distributed Dask dataframes. We like the Python connector and its use with Dask because it builds on skillsets that data scientists and ML engineers already have (Python, Pandas, NumPy) and utilizes APIs they should be familiar with. While there are other options available (like Spark) we see Dask as a perfect fit for use in ML workloads, and especially for feature engineering pipelines.
In a future blog, we’ll discuss how to ingest data into the MLRun feature store with Dask and Snowflake. In the meantime, feel free to ask questions and get in touch with us on the MLOps Live Slack community.
For more information on distributed fetches using Python, check out this page from the Snowflake documentation.
This blog has been republished by AIIA. To view the original article, please click here: https://www.iguazio.com/blog/using-snowflake-and-dask-for-large-scale-ml-workloads/
Recent Comments