
At a rapid pace, many machine learning techniques have moved from proof of concepts to powering crucial pieces of technology that people rely on daily. In attempts to capture this newly unlocked value, many teams have found themselves caught up in the fervor of productionizing machine learning in their product without the right tools to do so successfully.
The truth is, we are in the early innings of defining what the right tooling suite will look like for building, deploying, and iterating on machine learning models. In this piece we will talk about the only 3 ML tools you need to make your team successful in applying machine learning in your product.
Let’s Learn from the Past
Before we jump into our ML stack recommendations, let’s turn our attention quickly to how the tooling that the software engineering industry has settled on. One key observation is there isn’t one solution that is used to build, deploy, and monitor your code in production.
In other words, an end-to-end tooling platform doesn’t exist. Instead, there’s a set of tools, focused on specific parts of the software engineering lifecycle.

To streamline the creation of software, tools had to be created to track issues, manage version history, oversee builds, and provide monitoring and alerts when something went wrong in production.
Although not every tool clearly fits into one of these buckets, each of these tooling categories represents a distinct friction point in the process of creating software, which necessitated the creation of tools.
I Thought This Was About Machine Learning?
Just as with the process of developing software, the process of developing machine learned models has a broad set of categories that align with what it takes to research, build, deploy, and monitor a model.
In this piece we will be focusing on the essential ML tooling categories that have emerged in the process of solving some of the biggest hurdles in applying machine learning outside of the lab.
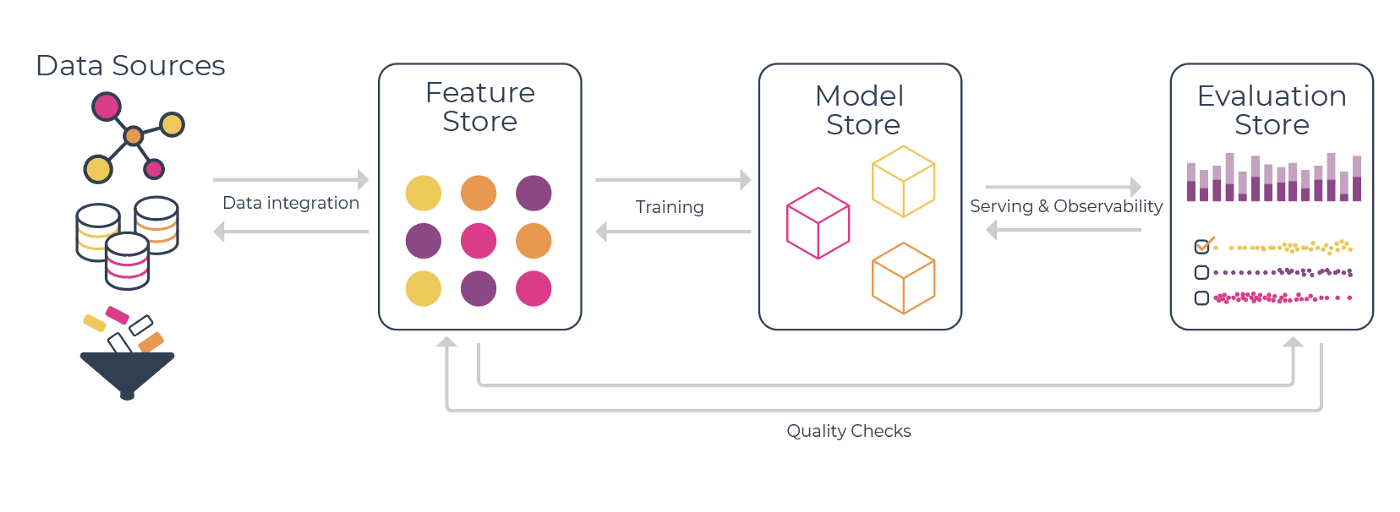
To create an effective machine learning toolbox, you really just need these 3 fundamental tools:
- Feature Store: to handle offline and online feature transformations
- Model Store: to serve as central model registry and track experiments
- Evaluation Store: to monitor and improve model performance
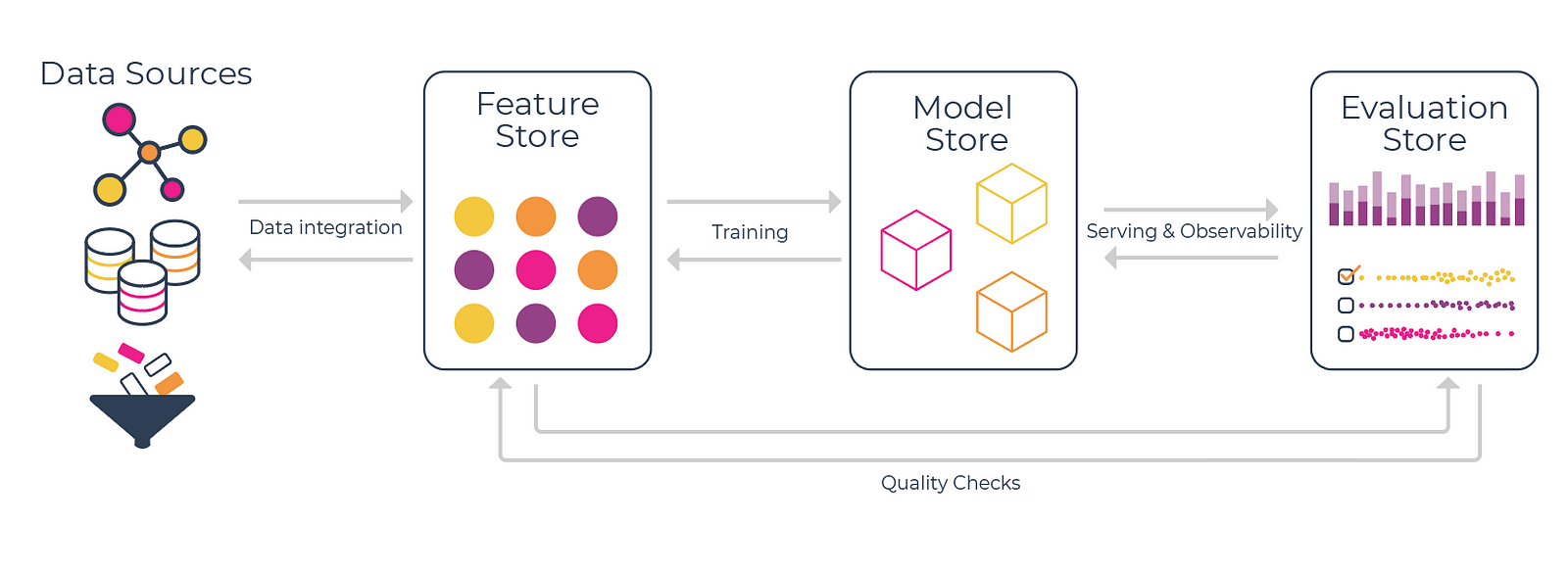
Feature Store
To start, let’s take a dive into the feature store. To define what a feature store is, let’s start with what a feature store should enable for your team.
What Should a Feature Store Enable:
- Serve as the central source for feature transformations
- Allow for the same feature transformations to be used in both offline training and online serving
- Enable team members to share their transformations for experimentation
- Provide a strong versioning for feature transformation code
Outside of how a feature store should empower your team, here is a list of must-have features that can help you decide which feature store works best for you and your team.
Things Your Feature Store Should Have:
- Integration with your Data Stores/Lakes
- A fast way to serve feature transformations for online deployment of your model
- Quick and easy deployment of feature transformation code into production
- Integration with your Evaluation Store to enable data and feature quality checks
Recommendation:
Model Store
Now that you have a feature store that stores your feature transformations, you need a tool that catalogues and tracks the history of your team’s model creation. This is where the Model Store comes into play.
What Should a Model Store Enable:
- Serve as a central repository of all models and model versions
- Allow for reproducibility of every model version
- Track lineage of models history
Outside of these core functions, there are a number of model store features that you will likely find really helpful in building and deploying your models.
Things Your Model Store Should Have:
- Should be able to track referenced datasets for every version of the model, git commits, artifact of the model (pickle file)
- Should give latest version of any model to be served e.g (v2.1)
- Maintain consistent lineage to roll back versions if needed
- Integrate with your Evaluation Store to track evaluations for every version of model to pinpoint model regressions
- Integrate with your serving infrastructure to facilitate model deployment and rollbacks
Recommendation:
Evaluation Store
Now that you have your models tracked and stored in your model store, you need to be able to select a model to ship and monitor how it’s performing in production. This is where the Evaluation Store can help.
What Should a Evaluation Store Enable:
- Surface up performance metrics in aggregate (or slice) for any model, in any environment — production, validation, training
- Monitor and identify drift, data quality issues, or anomalous performance degradations using baselines
- Enable teams to connect changes in performance to why they occurred
- Provide a platform to help deliver models continuously with high quality and feedback loops for improvement — compare production to training
- Provide an experimentation platform to A/B test model versions
Turning our attention now to the must-have features for an evaluation store, here are a couple of things that make a particular evaluation store worth considering.
Things Your Evaluation Store Should Have:
- Store the models evaluations: inputs, SHAP values and outputs for every model version, across environments: production, validation and training
- Automated monitoring to easily surface up issues — based on a baseline derived from the evaluation store
- Flexible dashboard creation for any type of performance analysis — DataDog for ML
- Integrate with your feature store to track feature drift
- Integrate with your model store to have a historical record of model performance for each model version
Recommendation:
Additional Tools That Might be Right for You
Data Annotation Platform:
Let’s take a step back and say you have just collected your data, which may or may not have ground truth labels. Modern statistical machine learning models often require lots of training data to perform well, and the ability to annotate enough data with ground truth labels to make your model effective can be quite the challenge.
Not to fear, Data Annotation Platforms distribute batches of your data to a distributed set of graders, each of which will label your data according to the instructions that you provide.
Recommendation:
Model Serving Platforms:
In many cases where machine learning is applied, you are going to need some form of serving platform to be able to deploy your model to your users. Briefly here are some of the core features that a serving platform should provide your team.
What Should a Model Serving Platform Enable:
- Access Control around model serving, only a select group of people should have permission to change which model is deployed.
- Fast rollback mechanisms to previously deployed model versions if needed
- Flexible support for different ML application types. For example in the case where prediction latency is not an issue, your serving platform should allow for batch inference to optimize for compute
- Integrate well with the model store for easy model promotion
- Integrate well with the evaluation store to enable model observability in production.
Recommendation:
AI Orchestration Platform:
In many cases, a platform that works across the the end-to-end lifecycle and enable teams to orchestrate the entire workflow is necessary. These platforms helps teams bring in their data form various sources, manage the training workflow, store models, serve them, and also connect to monitoring platforms. Managing the infrastructure across all these different tools can be complex, and an AI orchestration layer helps data scientists and ML engineers focus on delivering models.
Recommendation:
Conclusion
Finding the right tools for the job can sometimes feel overwhelming, especially for an emerging field. Just like the tools that empower software engineers today, there will be no end to end platform for building, deploying, and monitoring your machine learned models in production; however with just these few tools you should be able to get your models out of the lab and into the hands of your customers quickly and effectively.
Acknowledgements:
Credits to Josh Tobin for creating the term Evaluation Store!
This blog has been republished by AIIA. To view the original article, please click HERE.
Recent Comments