
The concept of embedding in machine learning can be traced back to the early 2000s, with the development of techniques such as Principal Component Analysis (PCA) and Multidimensional Scaling (MDS). These methods focused on finding low-dimensional representations of high-dimensional data points, making it easier to analyze and visualize complex data sets.
In computer vision, the concept of image embeddings gained popularity with the rise of deep learning techniques in the early 2010s. Deep learning models, such as Convolutional Neural Networks (CNNs), require large amounts of data for training, and embeddings provide a way to represent this data in a more efficient and effective way.
Join us as we explore the current state of embeddings in data curation for computer vision by looking into the trends that have propelled their rise to prominence. We’ll also discuss the challenges and potential pitfalls that lie ahead, providing invaluable insights for development teams on curating representative and well-balanced datasets that deliver results through performance. As we look to the future, we’ll also present our predictions on how embeddings will continue to shape and redefine the way data is curated, unlocking new opportunities for innovation in the field of computer vision.
We Will Cover:
-
Early development of embeddings
-
Advances in embedding algorithms
-
Trends in embedding implementation
-
Future directions for computer vision tasks
-
Challenges of embedding-based development
-
The right curation tools to pair with embeddings
The Evolution of Embeddings in Computer Vision
The early adoption of embeddings in machine learning and computer vision applications was characterized by the use of low-dimensional representations of high-dimensional data points.
This included techniques such as PCA and MDS, which were used to simplify the analysis and visualization of complex data sets. However, with the development of deep learning techniques and neural networks in the early 2010s, embeddings gained popularity in the field of computer vision.
Advanced Algorithms
Since then, there have been many advances in the use of embeddings for computer vision. One of the most significant advances has been the development of more advanced embedding algorithms. These algorithms are designed to capture and quantify the relationships between data points more effectively, resulting in more accurate and robust computer vision models.
Generating Deep Learning Embeddings
Another significant advance has been the integration of embeddings into deep learning models. This allows for more efficient and effective analysis of visual data, and has led to the development of many state-of-the-art computer vision models. More recently, the use of reinforcement learning for embeddings has gained popularity.
This involves using machine learning algorithms to automatically generate embeddings that are optimized for specific tasks. This approach has been particularly effective in improving the accuracy and efficiency of computer vision models.
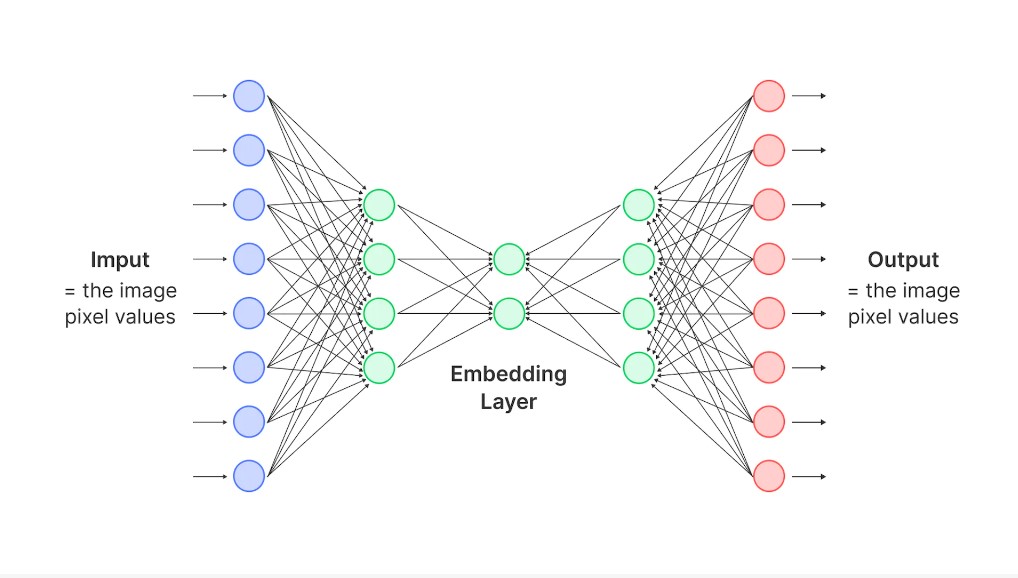
Understanding Datasets Through Embeddings
Understanding Datasets Through Embeddings
Embeddings in computer vision are used for a wide range of tasks, including image classification, object detection and recognition, image retrieval, similarity, and video analysis. In image classification, embeddings are used to represent images and assign them to specific classes or labels.
Object detection and recognition involves identifying specific objects within an image and accurately labeling them. Image retrieval involves finding images that are similar to a given query image, while similarity involves quantifying the similarity between images based on their embeddings.
The main benefit of using embeddings in computer vision is the ability to capture and quantify the relationships between data points. By doing so, teams can ensure that their training data is well-balanced, diverse, and accurately labeled. This leads to more accurate and robust computer vision models that can perform a wide range of tasks.
The Applications of Embeddings in Computer Vision
Image Classification
A fundamental task in computer vision, image classification assigns labels to images based on content. Embeddings represent images as high-dimensional vectors, enabling machine learning models to classify images accurately. For instance, models can differentiate between various dog breeds using their images.

Semantic Segmentation
Embeddings enhance semantic segmentation, a computer vision task that assigns class labels to individual pixels in an image. By representing localized image features, embeddings contribute to more accurate pixel-wise classification, improving scene understanding in applications like autonomous driving and aerial imagery analysis.
Face Recognition
Embeddings find wide application in face recognition, where they encode facial features as high-dimensional vectors. These embeddings allow models to identify and verify individuals based on their facial features, contributing to biometric authentication, surveillance, and social media applications.
Visual Question Answering
Embeddings enable visual question answering, an advanced computer vision task that combines natural language processing with image understanding. By representing both images and text as high-dimensional vectors, embeddings facilitate the development of models capable of answering questions about image content.
Anomaly Detection
Embeddings support anomaly detection in computer vision, where unusual patterns or objects in images are identified. By representing images as high-dimensional vectors, embeddings allow models to learn normal patterns and detect deviations, assisting in applications like quality control, surveillance, and medical imaging analysis.
Superb Curate’s clustering dashboard view is a powerful tool that can be used to resolve these anomalies in datasets. By creating a balanced dataset of unlabeled images with even distribution and minimal data redundancy and focusing on images that are rare.
Which have a higher likelihood of being edge cases, or are representative of the dataset. This feature minimizes any data errors that may have gone unnoticed earlier on during manual curation work, ensuring machine learning teams can build anomaly-free models.
A t-SNE visualization of 5000 random MNIST representations and embeddings. The first row is the representations from latent space and the second row displays the corresponding embeddings from embedded space. Image Source.
Object Detection and Recognition
Object detection and recognition is another important application of embeddings in computer vision. This involves identifying specific objects within an image and accurately labeling them. Embeddings can be used to represent different parts of an image, allowing for more accurate object detection and recognition. For example, a model could be trained to identify different objects in an image and label them accordingly, such as cars, buildings, and trees.
Image Retrieval
Image retrieval involves finding images that are similar to a given query image. This can be done using embeddings, which can be used to represent images as high-dimensional vectors. Similarity between images can be quantified using distance metrics such as Euclidean distance or cosine similarity. For example, a model could be trained to find images that are similar to a given image of a cat.
Future Directions for Embeddings in Computer Vision
As the field of computer vision evolves, so do the innovative features of our Curate product. Auto-curate is a powerful tool that harnesses the potential of embeddings in computer vision, helping machine learning teams build more efficient and effective models. Let’s explore how Auto-curate connects to the future directions of embeddings in computer vision.
Deep Learning Integration
Curate’s Auto-curate feature utilizes embedding technology, which is continuously being integrated with deep learning models to improve accuracy and efficiency. By selecting high-value data points based on sparseness, label noise, class balance, and feature balance, Auto-curate streamlines the data curation process and in the process, shortens and levels out the iterative training and validation phases of developing machine learning models.
Reinforcement Learning
The potential of reinforcement learning in generating optimized embeddings for specific tasks aligns with Auto-curate’s automated data curation. By leveraging advanced AI technology, Curate ensures accurate and efficient analysis of visual data to help you build state-of-the-art computer vision models.
Multi-Modal Embeddings
Curate embraces the potential of multi-modal embeddings, allowing for more complex applications in various industries. Auto-curate considers metadata and attributes of images, ensuring a balanced representation of different data types for a well-curated dataset.
Interpretable Embeddings
Understanding decision-making processes is crucial in fields like healthcare and finance. Curate’s Auto-curate feature aids in the development of interpretable embeddings by selecting data that is likely to be correctly labeled and similar to other data points in the same class, ensuring a reliable foundation for model development.
Real-Time Embeddings
As real-time embeddings gain importance for efficient video analysis, Curate’s Auto-curate feature offers a valuable solution. By automating the data curation process, Curate enables a ground truth-deep analysis of visual data, paving the way for any future CV applications with next-gen performance.

Discover the capabilities of Curate and tap into the promising future of embeddings in computer vision. With automated data curation and enhanced machine learning model optimization, Curate is the essential solution and partner for elevating your AI project’s proficiency.
Major Challenges and Opportunities
While embeddings have proven to be a powerful tool for data curation and computer vision model development, there are also several challenges that must be addressed in order to fully realize their potential.
Skewed Datasets
One major challenge is the issue of bias in embeddings. Because embeddings are trained on a specific dataset, they can inherit biases from that dataset. This can lead to inaccurate or unfair predictions, to address this challenge, it’s important to carefully select and curate training data to ensure that embeddings are representative of the real-world population.
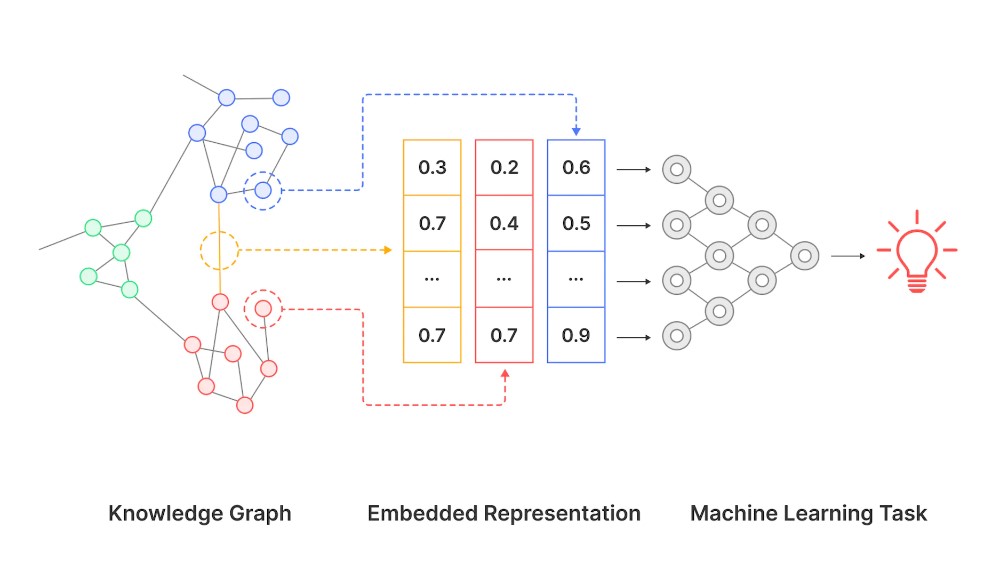
Knowledge Graph Embeddings
An approach to overcoming the challenge of preserving the semantic meaning in low-dimension dataset representations is through knowledge graph embeddings. Knowledge graphs are a way of representing information in a graph structure, where nodes represent entities, and edges represent relationships between entities.
Knowledge graph embeddings can capture the complex relationships between different entities and preserve semantic meaning in a low-dimensional space. This enables the development of more accurate and efficient models, while still providing insights into the underlying relationships within the data.
Scaling
Another challenge is the issue of scalability. As datasets and models become larger and more complex, the computational cost of generating embeddings can become prohibitive. This can limit the ability of smaller organizations or researchers to use embeddings effectively. To address this challenge, it’s important to continue to develop more efficient and scalable embedding algorithms.
Interpretability
Finally, there is the issue of interpretability. While embeddings can be highly effective at representing complex data, it can be difficult to interpret how models are making decisions based on those embeddings. This can make it difficult to diagnose errors or improve model performance. To address this challenge, it’s important to continue to develop methods for interpreting and visualizing embeddings.
An Ethical Obligation
Ethical considerations are also an important factor when it comes to the use of embeddings in computer vision development. For example, there are concerns about the use of embeddings in applications such as surveillance or facial recognition, where they could be used to infringe on people’s privacy or civil liberties.
It’s important for developers and researchers to be aware of these concerns and to take steps to mitigate them, such as building in privacy protections or limiting the use of embeddings in certain applications. While there are certainly challenges to using embeddings in computer vision development, there are also many opportunities for improving their use and ensuring that they are used ethically and responsibly.
By addressing these challenges and taking advantage of these opportunities, we can continue to drive innovation in the field of computer vision and enable more effective and responsible applications of this powerful technology.
The Future of Data Visualization
Embeddings play a crucial role in data curation and model development efforts in computer vision. The future of embeddings in computer vision is likely to see continued integration of deep learning models, the use of reinforcement learning for embeddings, the development of multi-modal embeddings, interpretable embeddings, and real-time embeddings. These trends and innovations will enable computer vision models to analyze and understand visual data more efficiently and accurately.
It’s worth noting that as the use of embeddings in computer vision continues to grow, the importance of data curation tools and platforms like Superb AI’s Suite will also become clearer. These platforms provide an efficient and streamlined approach to data curation, allowing teams to label large amounts of data with high accuracy and consistency. With less manual labeling required, the use of embedding models can achieve a high level of model accuracy and performance.
Additionally, with these platforms, machine learning teams don’t require the same degree of authority or expertise in a field or industry for their model to be successful; they can train data for various use cases and applications with embedding models they didn’t spend resources or time on developing themselves.
This blog has been republished by AIIA. To view the original article and please click HERE.
Recent Comments