This blog was written in collaboration with Hua Ai, Data Science Manager at Delta Air Lines. In this piece, Hua and Aparna Dhinakaran, CPO and co-founder of Arize AI, discuss how to monitor and troubleshoot model drift.
As an ML practitioner, you probably have heard of drift. In this piece, we will dive into what drift is, why it’s important to keep track of, and how to troubleshoot and resolve the underlying issue when drift occurs.
What is Drift
First things first, what is drift? Drift is a change in distribution over time. It can be measured for model inputs, outputs, and actuals. Drift can occur because your models have grown stale, bad data is flowing into your model, or even because of adversarial inputs.
Now that we know what drift is, how can we keep track of it? Essentially, tracking drift in your models amounts to keeping tabs on what had changed between your reference distribution, like when you were training your model, and your current distribution (production).
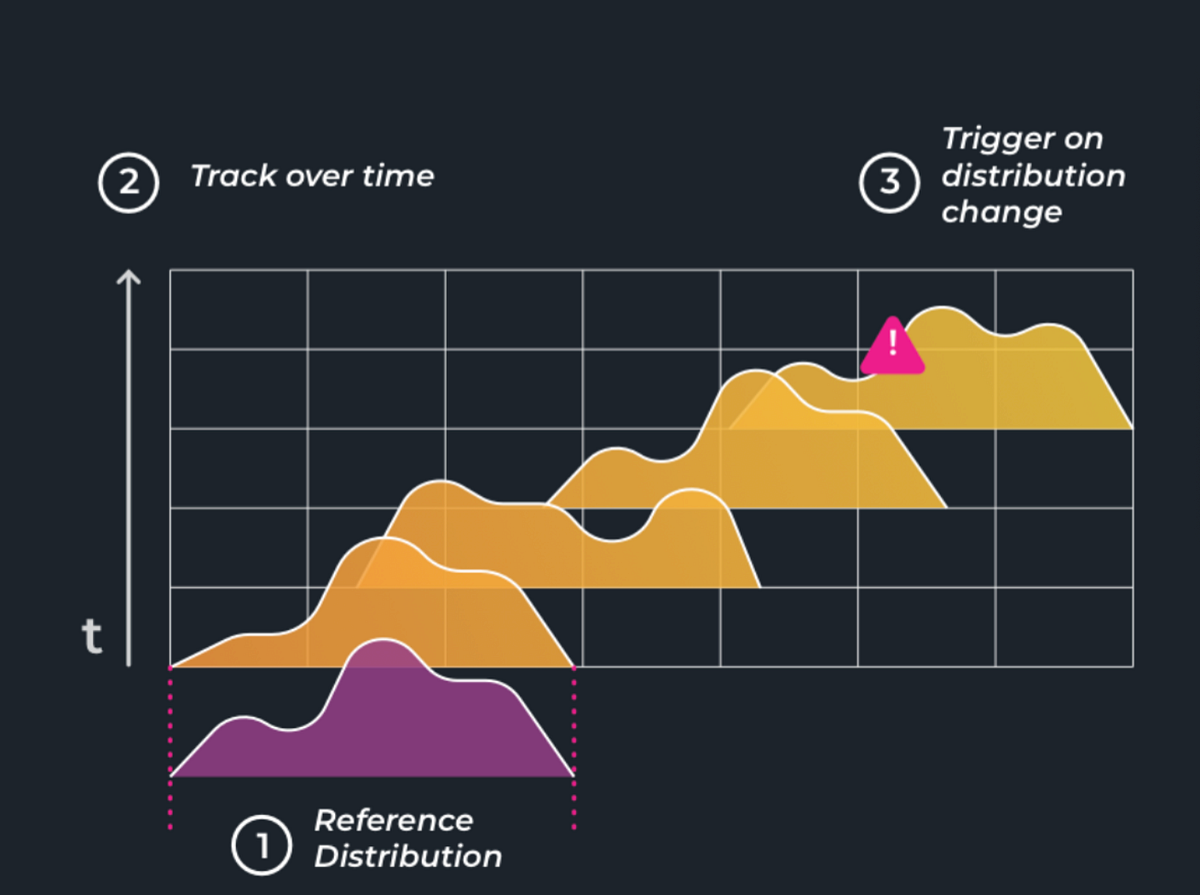
Models are not static. They are highly dependent on the data they are trained on. Especially in hyper-growth businesses where data is constantly evolving, accounting for drift is important to ensure your models stay relevant.
Change in the input to the model is almost inevitable, and your model can’t always handle this change gracefully. Some models are resilient to minor changes in input distributions; however, as these distributions stray far from what the model saw in training, performance on the task at hand will suffer. This kind of drift is known as feature drift or data drift.
It would be amazing if the only things that could change were the inputs to your model, but unfortunately, that’s not the case. Assuming your model is deterministic, and nothing in your feature pipelines has changed, it should give the same results if it sees the same inputs.
While this is reassuring, what would happen if the distribution of the correct answers, the actuals, change? Even if your model is making the same predictions as yesterday, it can make mistakes today! This drift in actuals can cause a regression in your model’s performance and is commonly referred to as concept drift or model drift.
How do I measure drift?
As we talked about previously, we measure drift by comparing the distributions of the inputs, outputs, and actuals between training and production.
But how do you actually quantify the distance between these distributions? For that, we have distribution distance measures. To name a few, we have
- Population Stability Index (PSI)
- Kullback — Leibler divergence (KL divergence)
- Wasserstein’s Distance
While each of these distribution distance measures differs in how they compute distance, they fundamentally provide a way to quantify how different two statistical distributions are.
This is useful because you can’t build a drift monitoring system by looking at squiggles on charts. It would be best if you had an objective, quantifiable ways of measuring how the distribution of your inputs, outputs, and actuals are changing over time.
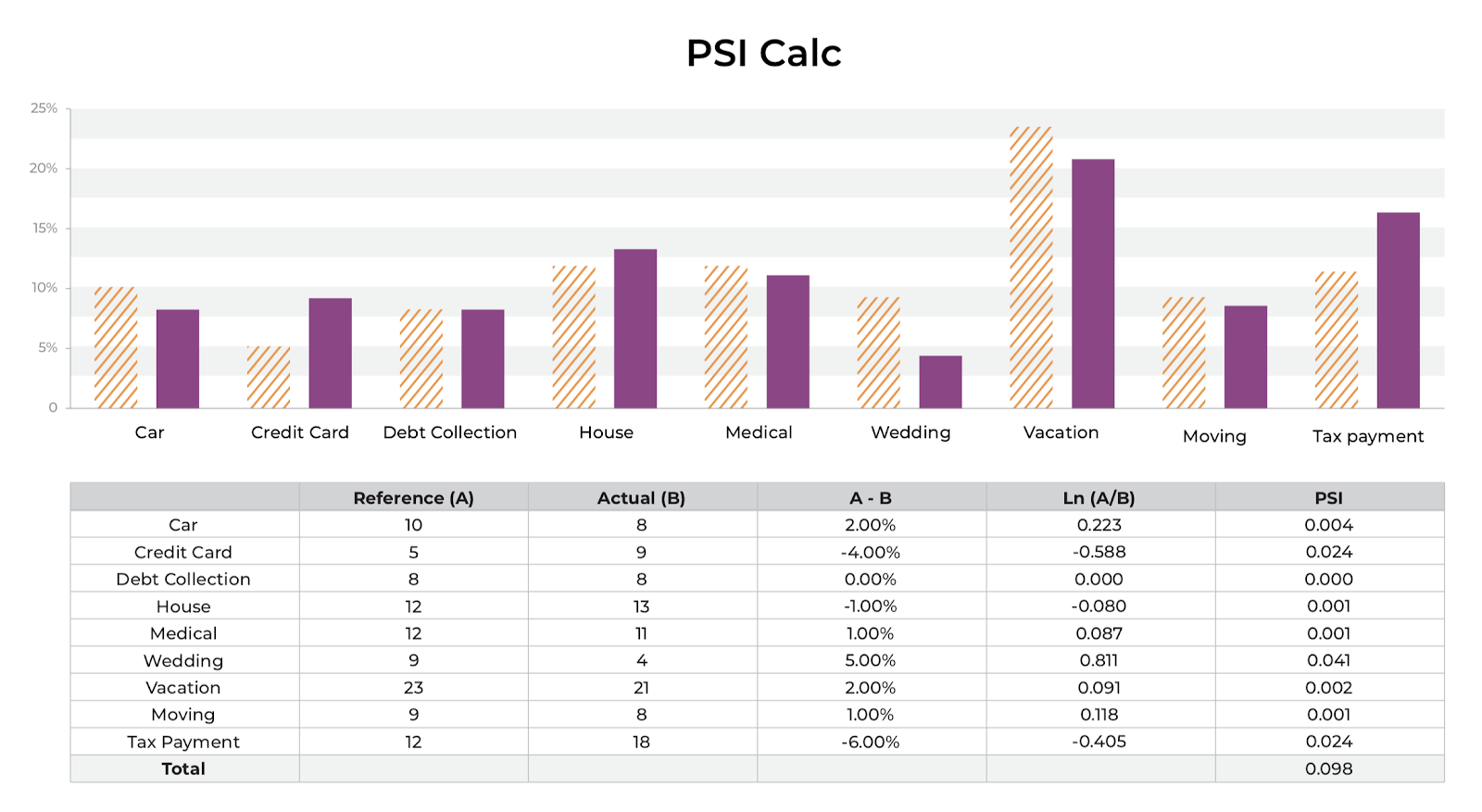
For example, in the above figure, we see a comparison in the distributions of how I spent my money this last year as compared to the year prior. The Y-axis represents the percentage of the total money I spent in each category, as denoted on the x-axis. To see if my allocation of money has changed significantly over the last year, we can calculate the population stability index (PSI) between these two distributions.
For each category in the budget, we calculate the difference in percentage between the reference distribution A (my budget last year) and the actual distribution B (my budget this year) and multiply this by the natural log of (A %/ B%). For each of these categories, take the sum of this value, which gives us our PSI.
The larger the PSI, the less similar your distributions are, which allows you to set up thresholding alerts on the drift in your distributions.
Regardless of the distribution distance metric you are using, it’s important to not just measure the drift in your distributions but also to measure how these distance metrics relate to important business KPIs and metrics. By doing so, you can start to understand how the drift can actually impact your customers and help you understand what drift thresholds trigger alerts to your team.

Can I Retrain my model?
What should we do when we notice a trained model has drifted? A first thought could be, “let’s retrain it”! While retraining is usually necessary, how to retrain requires some more thoughts. Simply adding the most recent data into your training set and redeploying the same model architecture may not solve the problem.
To start, you have to be careful about how you sample this newer data and represent it in your model. If you add too much new data and cause an overrepresentation in your training set, you risk overfitting this newer data. By doing so, your model might not generalize well in the future, and it may impact its performance on inputs that it previously had no trouble with.
On the other hand, if you only add a few examples, your model likely won’t change much at all, and your model might still make the mistakes that you set out to resolve.
You can adjust this tradeoff by weighting the examples in your loss function to strike the right balance between these two competing forces. One way you might measure how to balance this tradeoff is by measuring your performance on one globally sampled hold-out set to approximate your generalization performance and on another hold-out set sampled just from the population of the newer data. If you are performing really well on the global hold outset but not the newer data, you can try upping the weight you assign to the new data in your training set and visa-versa.
While, in many cases, retraining your model is the right solution, some changes are so fundamental that a simple retrain won’t solve anything. If you cannot achieve an acceptable validation performance on your retrained model, it may be time to go back to the drawing board. If something in your business has fundamentally changed, your models may need to as well.
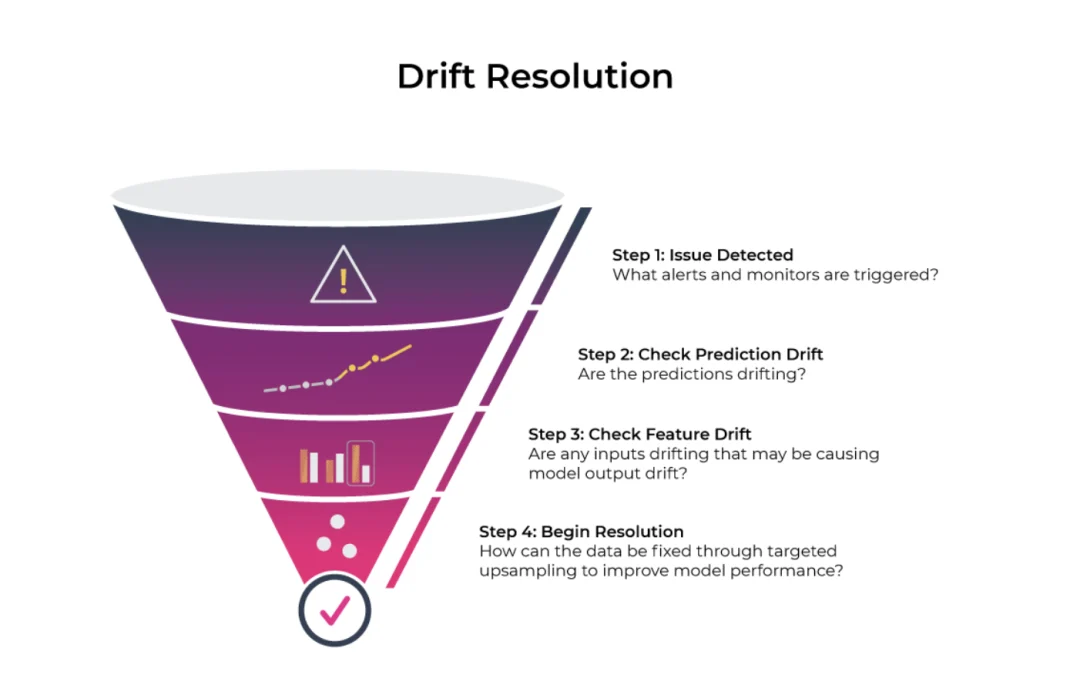
How to Troubleshoot Drift
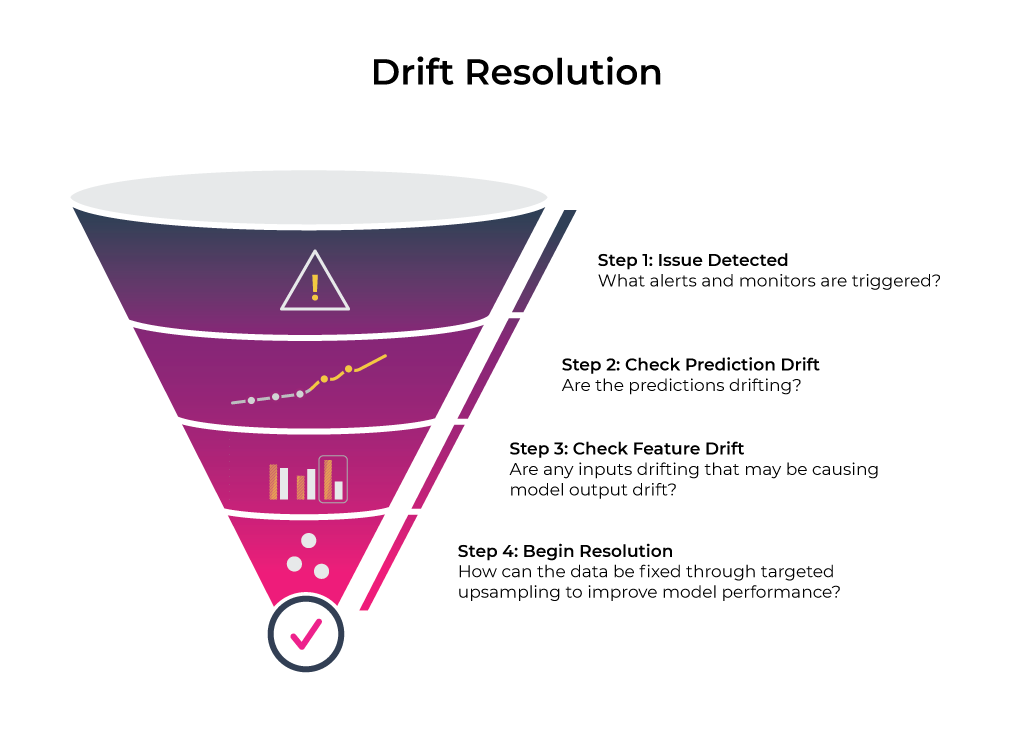
It all starts with an alert — an email or a notification that something is off. Usually, it is a good practice to keep track of the change in performance and changes in the input data since those changes may provide answers to the change in performance. It is also important to understand where drift has happened on a specific slice of data or certain dates. That will help to diagnose the model and to come up with solutions.
A systematic evaluation is needed when a significant drift alert has been triggered for a period of time. It’s usually an art instead of science to decide how significant a drift becomes concerning since it depends on how the predictions are being used and the business value of the prediction. But here are some steps to get you started in resolving drift.
1. Repull training data
Identify what input features or outcome variables have drifted and understand how their distributions have changed. Carefully consider what time period should be included in the retraining. Resampling or weighting observations can be used to reconstruct a more balanced training data set.
2. Feature Engineering
Sometimes we’ll notice some features have drifted significantly but have not caused model performance issues. That is not something to be overlooked since that indicates the relationship between those features and the outcome variable. Re-construct and select features to adapt to the new dynamics in this data set.
It is also a good time to connect with the end-users of the model to understand if their business processes have changed. New features are often needed to capture the change.
3. Model structure
Sometimes, the model structure should be revisited as well. For example, if only a slice of predictions has been impacted, a hierarchical model can be helpful to address this without changing the entire model.
How to get ahead of this?
It would be the worst if you’re doing all these in a fire drill. You get a call from your business partners asking you to explain why the model significantly underperforms in one day since they need to explain an undesirable business outcome to their stakeholders. It is never easy to explain a model’s performance on a set of specific data points, especially in pressured situations. It can also cause people to make nearsighted decisions and over-adjust the model to catch the most recent trend.
A good practice is to set up a cadence to review model performance periodically instead of relying entirely on alarms to indicate when things have gone wrong. Regular reviews help to keep track of changing business dynamics and of thinking about model adjustments proactively. Also, it is important to set up a regular channel to communicate with end-users, hear about their feedback on the model, or learn about upcoming process changes. At the end of the day, the models are there to support the end-users. Therefore, user perceptions are equally important as model performance metrics.
Take the Drift Away!
As we covered, drift is an aspect of ML Observability, and measuring is not enough. Having tools to resolve and troubleshoot drift helps improve models across its life.
This blog has been republished by AIIA. To view the original article, please click HERE.
Recent Comments