It is not news that machine learning and deep learning is expensive. While the business value of incorporating AI into organizations is extremely high, it often does not offset the computation cost needed to apply these models into your business.
Machine learning and deep learning are very compute intensive, and it has been argued that until cloud or on premise computing costs decrease – AI innovation will not be worth the cost, despite its unprecedented business value. In an article on WIRED, Neil Thompson, a research scientist at MIT and author of “The Computational Limits of Deep Learning” mentions numerous organizations from Google to Facebook that have built high-impact, cost-staving models that go unused due to computational cost making the model not profitable. In some recent talks and papers, Thompson says, researchers working on particularly large and cutting-edge AI projects have begun to complain that they cannot test more than one algorithm design, or rerun an experiment, because the cost is so high.
Organizations require dramatically more computationally-efficient methods to advance innovation and increase ROI for their AI efforts. Though, high computational cost, and a focus on more efficient computation doesn’t deserve all the blame. In fact, significant advances in GPU-accelerated infrastructure and other cloud providers have dramatically increased the ability to train the most complex AI networks at unprecedented speed.
In May 2020, DeepCube released its software-based inference accelerator that drastically improves deep learning performance on any existing hardware. In other words, compute solutions are being developed to meet the increasing demands of machine learning and deep learning.
The silent killer of AI innovation is the underutilization of existing compute, and the increasing cost of “computational debt”.
What is “computational debt”?
AI leaders may be surprised to find out that one of the leading factors impeding the ROI for machine learning is the under-utilization of GPUs, CPUs and Memory resources. Companies invest millions of dollars on compute that has the potential to dramatically accelerate AI workloads and improve performance, but end up only utilizing a small fraction of it, sometimes as low as 20% of these powerful resources.
The gap between compute allocation and actual utilization is shocking, and can cost companies more than they realize. This gap between compute allocation and utilization we refer to as “computational debt”. It refers to the “waste” between allocation and capacity. In the graphic below you can visualize the average utilization in green, versus allocation at a time in yellow.
When a workload is running, it is often only utilizing part of the GPU, leaving the other part blocked from other potential workloads. The area in grey is capacity, which is the existing compute available whether GPU, CPU, or memory. This is compute that is left idle, and underutilized.
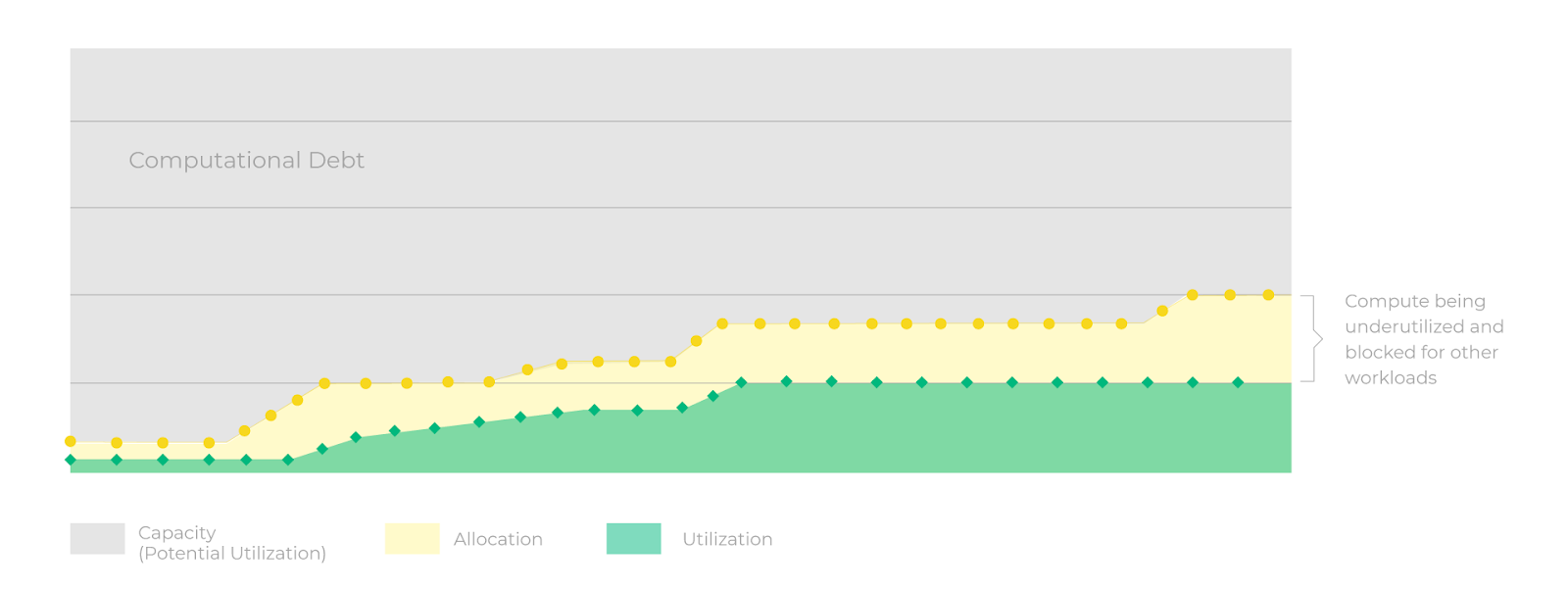
What causes “computational debt”?
Machine learning and deep learning are compute intensive and complex to manage, making this computational debt difficult to reduce. One of the greatest challenges for AI infrastructure teams is understanding how to increase utilization, and manage the resources in a way that maximizes consumption, and increases the ROI of machine learning projects. Some of the leading causes for “computational debt” are:
- Infrastructure Teams Lack AI Project Visibility: Infrastructure costs for ML projects are growing 2X each year, however IT teams lack the tools to manage, optimize and budget ML resources properly, on-prem or in the cloud. Most IT/DevOps leaders lack visibility into utilization, allocation and capacity of GPU/CPU and Memory at a given time. This makes it impossible to control consumption, and reduce inefficiencies.
- Growing “Computational Debt”: As AI compute needs become more complex, the gap between computational allocation and actual utilization increases in size. On average, organizations are likely to only consume around 30% of their overall resources. That leaves nearly 70% of compute idle, wasting companies thousands and even millions of dollars.
- Inability to Identify Inefficient Jobs: Infrastructure teams can’t easily identify workloads that consistently underutilize GPUs/CPUs. Without the data collected on historical workloads, there is no way to analyze and identify workloads that are running inefficiently. This lack of visibility makes it difficult to improve utilization, and to control how workloads are being prioritized.
- Productivity Disruption: Underutilized GPUs are being blocked for other jobs, and increases waiting time for data scientists to complete projects. This results in more time wasted waiting for the GPU availability, and wasted resources on top of that. Meanwhile, there are other resources that are idle that could be used for other jobs.
- Lack of standardization and unification: Often, teams are unable to correlate a job to its utilization metrics. There is no standard visualization tool that allows you to see an allocation, utilization and capacity of jobs at a certain point in time. This makes it difficult to identify inefficient jobs and prioritize wasteful workloads. Machine learning has reached the stage of maturity that AI infrastructure strategizing is necessary in order to grow.
- Inability to control optimization strategies: While some teams might be able to identify inefficiencies and plan for an optimized infrastructure strategy, there are few tools to execute on these strategies. IT/DevOps teams require control of AI workloads in order to optimize resource management. Without ways to prioritize jobs, configure compute templates and monitor workload allocation and utilization, no substantial improvements can be made.
Strategies to reduce “computational debt”
There is no clear resolution to this problem, but there are ways to increase the effectiveness of resource management. Here are a few strategies that could improve utilization of your compute resources.
- Invest in the most advanced GPU-accelerated AI infrastructureGPU acceleration technology has come a long way. Hardware and software deep learning acceleration solutions have emerged to deliver unprecedented performance. Research the latest available solutions for GPU acceleration to adopt a truly modern AI infrastructure.
- Adopt a Hybrid Cloud infrastructureCombining public clouds, private clouds, and on-premise resources offers agility and flexibility in terms of running AI workloads. Because the types of workloads vary dramatically between AI workloads, organizations that build a hybrid cloud infrastructure are able to allocate resources more flexibly and custom sizes. You can lower CapEx expenditure with public cloud, and offer the scalability needed for periods of high compute demands. In organizations with strict security demands, the addition of private cloud is necessary, and can lower OpEx over time. Hybrid cloud helps you achieve the control and flexibility necessary to improve budgeting of resources.
- Utilize estimation tools for GPU/CPU memory consumptionAccording to a Microsoft Research study on 4,960 failed DL jobs in Microsoft, 8.8% of the job failures were caused by the exhaustion of GPU memory, which accounts for the largest category in all deep learning specific failures. Many estimation tools have been developed to help plan GPU memory consumption to reduce these failures. In addition, if you’re able to collect utilization data, you can use this historical data to better forecast GPU/CPU and memory needs for each quarter.
- Scale MLOps Introduce a way to streamline your ML workflow and standardize transitions between science and engineering roles. Since IT and DevOps are responsible for deploying and managing workloads, it’s important to have a clear communication channel when running different jobs. Proper scheduling tools and strategizing resource templates can also improve resource management of AI workloads.
- Maximize utilization, and reduce “computational debt”Focusing on computational debt as a KPI for your infrastructure team and data science team is necessary in order to improve utilization. Organizations that manage to reduce computational debt and increase utilization will thrive in the race towards AI.
Conclusion
There are few solutions that maximize visibility of GPU/CPU and memory consumption for infrastructure teams to improve utilization. While the industry is quickly building more efficient hardware and software to solve the threat of computational debt, we have a long way to go.
The reality is, most organizations are sitting on millions of dollars of underutilized compute.
By using what you have, and improving resource management, organizations will enable massive scalability of their AI infrastructure. By adopting some of these strategies into your modern AI infrastructure, you may find that full utilization of compute is achievable.
Companies that focus on infrastructure optimization are going to see an increased ROI for their AI efforts, and gain a competitive edge against the competition.
Recent Comments