AI INFRASTRUCTURE ALLIANCE
Building the Canonical Stack for Machine Learning


Our Work
At the AI Infrastructure Alliance, we’re dedicated to bringing together the essential building blocks for the Artificial Intelligence applications of today and tomorrow.
Right now, we’re seeing the evolution of a Canonical Stack (CS) for machine learning. It’s coming together through the efforts of many different people, projects and organizations. No one group can do it alone. That’s why we’ve created the Alliance to act as a focal point that brings together many different groups in one place.
The Alliance and its members bring striking clarity to this quickly developing field by highlighting the strongest platforms and showing how different components of a complete enterprise machine learning stack can and should interoperate. We deliver essential reports and research, virtual events packed with fantastic speakers and visual graphics that make sense of an ever-changing landscape.
Download the Enterprise Generative AI Adoption Report
Oct 2023
Our biggest report of the year covers the wide world of agents, large language models and smart apps. This massive guide dives deep into the next-gen emerging stack of AI, prompt engineering, open source and closed source generative models, common app design patterns, legal challenges, LLM logic and reasoning and more.
Get it now. FREE.

AI Landscape

Check out our constantly updated AI Landscape Graphic that shows the full range of capabilities for major MLOps tools instead of just pigeonholing them into a single box that highlights only one aspect of their primary characteristics.
Today’s MLOps tooling offers a broad sweep of possibilities for data engineering and data science teams. You can’t easily see those capabilities in typical graphics that show a bunch of logos so we’ve engineered a better info-graphic to let you quickly figure out if a tool does what you need now.
Events – Past and Future
Check here for our upcoming events and to watch videos from past events. We put on 3 to 4 major events every year and they’re packed with fantastic speakers from across the AI/ML ecosystem.

MEMBERS


ARTICLES

On AI Ethics: Wendy Foster, Director of Engineering and Data Science at Shopify
Shopify, a leading provider of essential internet infrastructure for commerce, is relied on by millions of merchants worldwide to market and grow their retail businesses. This past Black Friday and Cyber Monday weekend alone, Shopify merchants achieved a...

Choosing the Right Infrastructure for Production ML
Choosing the right infrastructure for your production ML can impact the performance, scalability, cost, and security of models. When it comes to deploying machine learning models in production, choosing the right infrastructure is crucial for ensuring the success of...

7 Recommendations for a Safe Integration & Adoption of Generative AI and LLMs in the Enterprise
Executive Summary Generative AI and LLMs: Unlocking new opportunities for innovation, efficiency, and productivity, while posing potential risks including confidentiality breaches, IP infringements, and data privacy violations. Seven Recommendations: Safely integrate...

Feature Engineering for Recommendation Systems – Part 1
The way ML features are typically written for NLP, vision, and some other domains is very different from the way they are written for recommendation systems. In this series, we’ll examine the most common ways of engineering features for recommendation systems. In the...
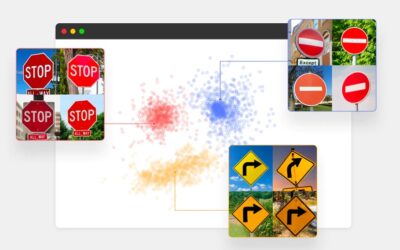
The Future of Embeddings for Computer Vision Data Curation
The concept of embedding in machine learning can be traced back to the early 2000s, with the development of techniques such as Principal Component Analysis (PCA) and Multidimensional Scaling (MDS). These methods focused on finding low-dimensional representations of...

tinyML Talks: Running and Managing Fleets of Single Board Computers at Scale
Presented by the tinyML Foundation: Running and Managing Fleets of Single Board Computers at Scale. The increase of compute power available on single board computers (SBCs) has opened the door to a whole new class of ML-powered applications that can run on the likes...
Connect with Us
Follow US