Introduction:
AI is a rapidly evolving field and up until a few years ago there were distinct model architectures for different tasks, for example, CNN was the go-to for vision tasks and LSTM like networks for language tasks. Then, with the invention of the Transformer architecture and subsequent development in just the past 2–3 years, these tasks are now handled very well by a single architecture with some tweaks for the different use-cases. Newer, bigger models are being released every few months that beat state-of-the-art models in accuracy by some percent.
When developing AI solutions in practice, it is easy to get caught up in the land of searching for the better architecture, bigger pre-trained models or the best set of hyperparameters with the goal of achieving slightly higher accuracy. This is how the community has looked since the mid 2000s, however, in early 2021, a movement led by Andrew Ng shifted how practitioners think about improving their models. While research in model and architecture development is still going on (for all the right reasons) a new way of model development called data-centric AI is coming into play.
Data-Centric AI:
What is data-centric AI and how does it differ from model-centric AI? Model-centric AI development is what the industry has been traditionally doing. Have a fixed dataset, train a model, evaluate that model on a holdout-test set and then tweak the hyperparameters or change the model to get better results, and continue doing so until the desired metrics are achieved.
The data-centric approach varies in one key concept: Hold the model and hyperparameters fixed and apply error analysis driven data iteration to improve model performance. A very important point to note: Error analysis driven data iteration. This means analyzing the errors on various classes and samples and letting that guide future processes such as data acquisition, collection, and augmentation. This also helps improve the model performance with a strategy in place instead of randomly collecting more data, augmenting certain classes, etc.
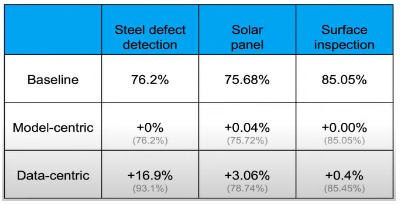
But why move from the current model-centric approach which has worked so well? The answer is simple: Because in ML/AI, data is code. Data defines how our model performs, and by doing so, it takes on the role of code. What you feed into the model dictates its future behavior. Using the model-centric approach hits a performance ceiling, and then the results can be improved vastly by taking a more data-centric approach. Remember, garbage in = garbage out. This slide from Andrew Ng’s course shows how the performance of a model can improve in orders of magnitude by taking a data-centric approach:
Remember, data is code.
Steps for data-centric model development approach:
How do you start taking a data-centric model development approach? It begins during the scoping phase and goes up to the post-deployment stages. Let’s get into the details:
1. Scoping and pre-model development:
Ensure the right data can be acquired: Because data is code, it is important that the right data can be collected. It is important to ensure that the data contains the signal we are interested in. For example, if screen scratches on a phone are seen by a human inspector on the shop floor but the same inspector cannot see the scratch on the image captured by the image acquisition device, it might be that the lighting or the camera resolution used to acquire the images needs to change. Good data coverage is also important, such that as many possible cases are covered for the training and testing datasets.
Establish a Human Level Performance (HLP): For unstructured data such as audio and images, establishing HLP will help set a baseline during model iteration and also help drive the error analysis driven data iteration by identifying classes where improvement is possible and will result in the most positive returns.
2. Labeling:
Be it model centric development or data centric development, this stage is very important. It is important that labels are consistent and clean and is even more important in cases with small datasets, as noisy data can negatively affect the model’s performance. In order to achieve this, labelers must have a rulebook which they can follow to make sure there are no inconsistencies between different labelers.
For example, in the image below some labelers might label individual kittens (left hand side), and some might label it as a group (right hand side). Both of them are technically correct, however, we should set up rules in the beginning of the labeling phase to let the labelers know which one is the preferred way. Tools such as LandingLens can help streamline this process.

3. Model development and error analysis driven iteration:
Model centric development keeps the dataset fixed, and then iteratively improves the model performance by tuning the hyperparameters or changing the model. Because of this, model development usually takes place after all the data required/possible to collect has been collected.
Data centric development takes on a different approach: Start quick and move fast in the initial stages. Rather than waiting for months and years to collect all the data possible, start with a relatively small dataset and train the model on it as soon as it is of a reasonable size for the architecture used.
Real world data doesn’t always play nice. Make sure you’re setting your experiments up for success with our free webinar.
Doing so helps to know whether the right data is being collected, or something in the data acquisition process needs to change. For example, if the lighting condition in a factory means that certain types of scratches on the car cannot be seen in images, this problem would’ve been identified earlier rather than later (waiting a year to collect the data).
Using tools for data version control such as Comet ML and dvc will help keep track of changes in the dataset over time during the iterative process.
Once the model is trained, error analysis is then performed on the initial model. This is the most interesting bit about the data-centric approach. Error analysis, along with HLP (if available) and importance-metrics, is used to guide the future actions and data collection strategy.
For example, if the defect detection model isn’t doing well on scratches less than 2 cm on silver colored car doors, that insight can be used to drive the future data collection strategy. Tools such as Comet ML can help identify cases where the model’s performance is not up to the mark.
The number of samples can be increased by:
- Collecting more data with current data acquisition pipelines.
- Data augmentation.
- Synthetic data generation using packages such as Unity Perception.
In most modern day deep learning architectures, adding data rarely hurts, especially if a large model is being used. In fact, it usually results in similar classes improving their performance slightly. This means that if it is proving difficult to gather more samples of scratches less than 2 cm on silver colored doors, gathering samples from other similar looking doors (ex: grey doors) with scratches less than 2 cm will likely increase the model’s accuracy for silver colored doors too.
Prioritizing the improvement of the model’s performance on one class at a time can help focus the resources available. This decision can be taken through various methods, such as:
- Measuring the gap between the model’s performance on a particular class and the HLP (if available) of that class.
- Using a particular class’s misprediction cost (confusion matrix with weights for each pair-wise misprediction).
- Percentage of data of a particular class likely to be encountered during serving.
- Combining the information about gap to HLP and percentage of data (as shown in the figure below).
From the table above, it can be seen that focusing on improving the performance on grey cars will provide more value to the business than the other cars. In doing so, the accuracy of other similar classes should increase too.
Other techniques include testing the latest iteration of the model on samples misclassified by the previous iteration to analyze performance improvement on the latest iteration, and also whether the model training and data collection strategies are working. It will also help identify on which samples different iterations of the models are continuously failing to accurately predict, which might also serve as a guide for future data collection strategies.
4. Data monitoring:
Once the model is in production, the incoming data needs to be constantly monitored. This is because the real world is ever-evolving, which means data being fed into the model for prediction is constantly evolving. There are usually two kinds of drifts that happen:
Data drift: Change in the distribution of the input X. This can be due to a variety of reasons, such as:
- The voice input differs because different nationalities have started using the NLP system from what it was trained on.
- In the case of a visual inspection system, the camera is knocked off its desired field of view.
- Changes in the website, which now lets the user input negative values compared to only positive values the model was trained on.
Concept drift: The mapping from X to y changes. For example, a housing price dataset trained in 2000 probably wouldn’t work well today, as housing prices in most cases have gone up since then. Concept drift usually happens slower than data drift, as human sentiments and behavior rarely changes abruptly. However, events such as COVID-19 can cause a sudden change in concept, such as many more people ordering groceries online than they used to before.
Both types of drifts are detrimental to a model’s performance. There are various ways these drifts can happen. Therefore, the methods to handle drift vary case-by-case. However, in order to understand that there is data drift, the incoming data during model serving must first be monitored. This can be done in various ways, such as plotting a histogram of the incoming image image pixel values and comparing against a set schema (which can be obtained during training), or in the case of tabular data, calculating the various statistics such as min, max, mean, variance, and range, etc., of the incoming values.
Tools such as Comet MPM can help monitor production models and detect concept drifts. This blog by Chip Huyen titled ‘Data distribution shifts and monitoring’ is a detailed must-read post on how to detect drifts in different cases.
In some cases, samples suffering from data drift or concept drift will pass right through the monitoring system. For example, a slightly blurry image from the camera because of vibrations in a factory will result in almost the same statistical image properties, which may pass under the data drift detector. This is why it is also important to track the performance of the model.
5. Model monitoring and retraining:
Model monitoring is the process of monitoring how accurate the model’s prediction is during serving.
Model monitoring can be done in different ways, either through human-in-the-loop feedback or through automatic feedback systems such as click-through-rate for recommendation systems. Some feedback can be obtained quicker than others.
A model can degrade in performance either due to concept drift or data drift or a combination of both. When the model performance for real-world inference falls below a set threshold (depending on the use case), it will have to be retrained. There are different techniques for doing so, such as retraining by using the new data on top of the old model (transfer learning), or if the concept change is drastic, then entirely new models will have to be retrained with the new data.
It is good practice to have systems in place where the correctly and misclassified samples during serving are stored separately, which can later be used for analysis and re-training.
Once re-trained, the performance of a new model can be assessed by rolling out the model using different deployment strategies such as shadow mode, canary deployment or blue-green deployment.
Conclusion:
As you’ve seen, taking a data-centric approach to a problem is an iterative process which uses data as your guide.
Data centric doesn’t only mean using the right high quality data to train your model, but it also means using data to measure the model’s success, perform error analysis driven iteration on that data to improve the model, and maintain the model by monitoring the incoming data and the models performance on it.
With the development of more developer friendly tools to take a data-centric approach, such as Comet ML, LandingLens, etc., the data-centric approach for model development will be a great driver for model development and improvement in the future. Think about ways you can implement a more data-centric approach in your current project or future projects, and share your thoughts on this fairly new approach of model development.
Remember, data is code.
This blog has been republished by AIIA. To view the original article, please click HERE.
Recent Comments