
The Evolving Meaning of ‘MLOps’
When you say ‘MLOps’, what do you mean? As the technology ecosystem around ML evolves, ‘MLOps’ now seems to have (at least) two very different meanings:
- One common usage of ‘MLOps’ refers to the cycle of training an AI model: preparing the data, evaluating, and training the model. This iterative or interactive model often includes AutoML capabilities, and what happens outside the scope of the trained model is not included in this definition.
- My preferred definition of MLOps refers to the entire data science process, from ingestion of the data to the actual live application that runs in a business environment and makes an impact at the business level. In this article, I’ll explain the difference between these two approaches and why it matters to your data science team, and to the success of your organization as a whole.
The Research-First Approach to MLOps
The typical journey of an organization with a data science use case and a small team is to start from what they perceive to be the logical beginning: building AI models. A business idea based on data science is selected, and budget is allocated for the data scientists to start the work of building and training machine or deep learning models. They get access to data extractions, search for patterns, and build models that work in the lab.
For veterans of this space, it’s remarkable to observe how the industry has changed. Years ago, ML models were used to generate static or interactive reports for business analysts, and data science was handled as a silo, doing batch predictions on historical data and returning the results for someone else to incorporate manually into applications. In those conditions, there was very little demand for resiliency, scale, real-time access, or continuous integration and deployment (CI/CD), but we also gained limited value from our models.
As a vestige of this old mindset, most data science solutions and platforms today still start with a research workflow and fail to deliver when it comes time to turn the generated models into real-world AI applications. Even the concept of a CI/CD pipeline is often used to refer to just the training loop, and not extended to include the entire operational pipeline. This approach forces the ML team to re-engineer the entire flow to fit production environments and methodologies. This way of duplicative working consumes far too much resources and time, and often results in inaccuracies.
Research-First Approach: How it Works and Why it’s Incomplete
The common way to tackle AI projects is to start by developing a model. The data scientist receive data which is extracted manually from a variety of sources, he or she explores and prepares data in an interactive way (the most common tool for this stage is Notebooks), the training and experiments are run while tracking all the results, a model is generated and tested/validated until satisfying results are obtained. With the resulting model, different teams of ML or data engineers will figure out how to build it into the business application, how to handle API integrations, build data pipelines, apply monitoring, and so on. In many cases, the original data science will be set aside and re-implemented in a robust and scalable way which fits production, but which may not be what the data scientist originally intended.
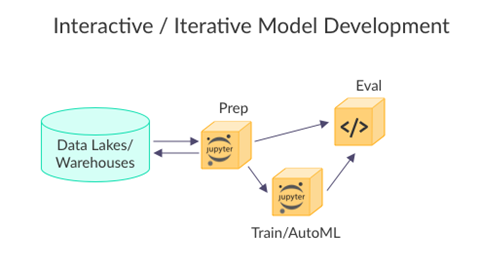
Many tools offer ways to version data and track experiments or models during the research and development phase, and some also allow automation for the model development pipeline and can generate an endpoint which serves the model. Yet they stop after the model development flow, and they don’t contribute much to the production pipeline which starts from automated data collection and preparation, automated training and evaluation pipelines, real-time application pipelines, data quality and model monitoring, feedback loops, etc.
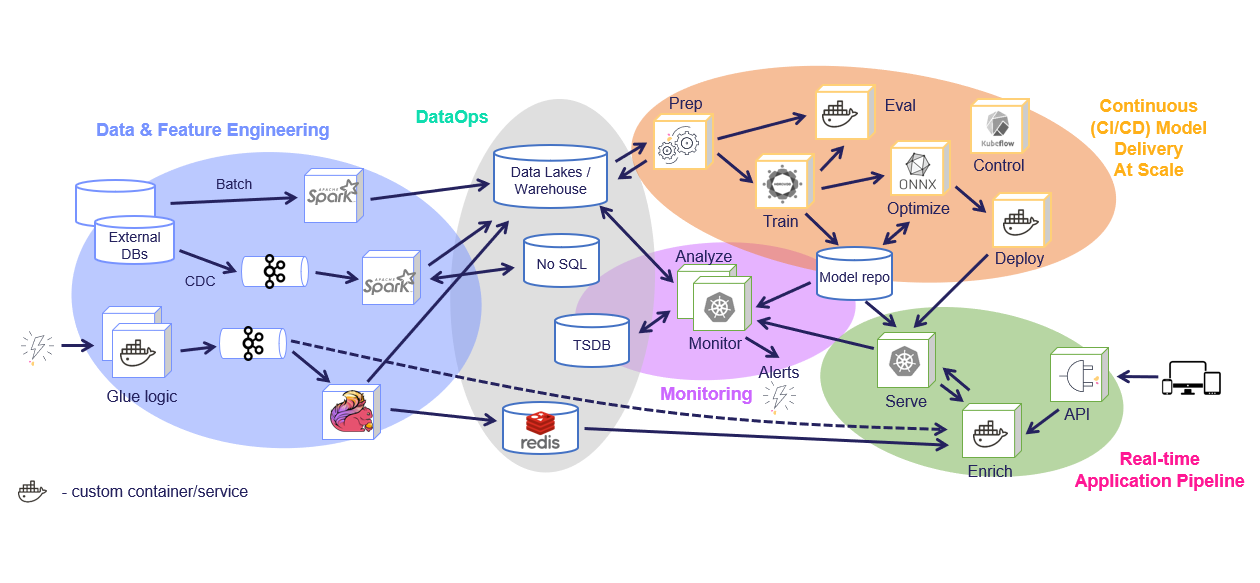
As you can see from the two diagrams above, there isn’t much overlap between the model development phase and the production environment.
The production deployment:
- Involves many more components which need to work and be versioned together
- Significant effort is placed on data processing, application integration, and monitoring tasks
- Interactive development is replaced with managed micro-services which can handle scale and automated (re)deployment
- Focuses on resiliency, observability, security, and continuous operations.
The common approach of developing models in a data science silo leads to waste of valuable resources and far longer time to production.
Training is done! Now what?
Modern applications in which AI models provide real-time recommendations, prevent fraud, predict failures and guide self-driving cars bring far more value, but also require significant engineering efforts and a new approach to make it all feasible. Business needs have forced data science components to be robust, performant, highly scaleable, and aligned with agile software and DevOps practices. For every hour spent on developing a model there are a dozen more spent on engineering and deployment.
Often, the broader team only realizes the challenges of operationalizing AI that lie before them once they’ve built the model in the lab. At this late stage, building the actual AI application, deploying it, and maintaining it in production become acutely painful, and sometimes nonviable. Then comes the realization that to create a process that is repeatable and reproducible, so that more AI applications can be built and deployed on an ongoing basis, is a whole other ballgame.
Adopting a Production-First Mindset
It happens all too often that operationalizing machine learning — in the sense of considering all the requirements of the business, such as federated data sources, the need for scale, the critical implications of real-time data ingestion or transformation / online feature engineering, handling upgrades, monitoring etc. — comes as an afterthought, making it all the more difficult to create real business value with AI.
That’s why I advocate for a mindset shift. Begin with the end in mind: that is, take a production-first approach to designing a continuous operational pipeline, and then make sure the various components and practices map into it. Automate as many components as possible, and make the process repeatable so that you can scale along with the organization’s needs.
The Production-First Approach to MLOps & Its Benefits
Instead of this siloed, complex and manual process, start by designing the production pipeline using a modular strategy, where the different parts provide a continuous, automated, and far simpler way to move from research and development to scalable production pipelines, without the need to refactor code, add glue logic, and spend significant efforts on data and ML engineering.
There are four key components that should be considered for every production pipeline:
- Feature Store: collects, prepares, catalogs, and serves data features for development (offline) and real-time (online) usage
- ML CI/CD pipeline: automatically trains, tests, optimizes, and deploys or updates models using a snapshot of the production data (generated by the feature store) and code from the source control (Git)
- Real-time/event-driven application pipeline: includes the API handling, data preparation/enrichment, model serving, ensembles, driving and measuring actions, etc.
- Real-time data and model monitoring: monitors data, models, and production components and provides a feedback loop for exploring production data, identifying drift, alerting on anomalies or data quality issues, triggering re-training jobs, measuring business impact, etc.

While each of those steps may be independent, they still require tight integration.
For example:
- The training jobs need to obtain features from the feature store and update the feature store with metadata, which will be used in the serving or monitoring.
- The real-time pipeline needs to enrich incoming events with features stored in the feature store, and may use feature metadata (policies, statistics, schema, etc.) to impute missing data or validate data quality.
- The monitoring layer must collect real-time inputs and outputs from the real-time pipeline and compare it with features data/metadata from the feature store or model metadata generated by the training layer, and it needs to write all the fresh production data back to the feature store so it can be used for various tasks such as data analysis, model re-training (on fresh data), model improvements.
MLOps Automation & Orchestration
When we update one of the components detailed above, it immediately impacts the feature generation, the model serving pipeline, and the monitoring, so we need to apply versioning to each component as well as versioning and rolling upgrades across components.
Because these four components are so tightly connected, they cannot be managed in silos. This is where MLOps orchestration comes in. ML teams need a way to collaborate using the same set of tools, practices, APIs, metadata, and version control. This collaboration can happen on a custom-built platform, built with individual components that must be glued together and maintained by large internal teams, or using an off the shelf automated solution like the Iguazio MLOps platform or the open source MLOps orchestration framework, MLRun.
MLOps Should Provide Real Business Value!
Did your data science team prevent fraud for your organization, reducing fraudulent transactions to save costs for your organization, enable extension of credit lines to new customers and reduce legal hassles?
Was your organization able to predict which machines are about to malfunction, and proactively mitigate the issue to save costs on repairing broken machines or purchasing new ones?
Were your customer success teams able to predict customer churn and produce the exact benefit needed to retain your customers, directly impacting your organization’s bottom line?
If the answer to these is no, and software / infrastructure inefficiencies are holding your organization back from seeing the real value your data science team could deliver, now is the time to look into solutions that make the data science process automated, orchestrated, accelerated and reproducible. With a solid MLOps foundation, you will be able to quickly and continuously deliver new AI services for the business, even at scale and in real-time. You will enable your data science, data engineering and DevOps teams to collaborate more efficiently and effectively. Most importantly, the entire organization will be able to benefit from your team’s innovative solutions, and see them directly impacting the organization’s goals and bottom line.
This blog has been republished by AIIA. To view the original article, please click HERE.
Recent Comments