
Today, TruEra launched TruEra Diagnostics 2.0, the next major release of our flagship solution. This release is a game-changer for our customers and for ML leaders looking to accelerate the time required to get high quality models into production. That’s because TruEra Diagnostics now offers an automated test harness for ML models. We believe that it’s the first automated, systematic ML testing solution available with root cause analysis. It leverages our comprehensive analytics across accuracy, reliability, stability, and fairness to help test, debug, and act quickly, so that you can build better models faster. We believe that the ML test harness will be a fundamental requirement of any modern ML tech stack, making ML quality assurance a reality.
Why does ML need better testing and debugging?
ML development is where software development was a few decades ago – lots of promise and potential, but suffering from a lack of mature development tools and methodologies to ensure high quality outcomes. It’s one of the reasons why data science projects are often over time and over budget, while exhibiting high failure rates. In particular, data scientists and ML engineers have immature tools and methodologies around two key parts of the development lifecycle that software engineering experience has shown are key to high quality and efficient outcomes: testing and debugging.
The challenges that ML teams face when testing ML models include:
- Evaluation limitations: the metrics used to test models are typically too limited today. Many ML teams primarily look at global accuracy type metrics such as AUC, ROC, confusion matrices, error metrics, etc.. Critical analyses regarding conceptual soundness, explainability, model stability, bias, data quality, overfitting, or more specific accuracy metrics are often overlooked. In addition, ML teams often don’t look at these metrics at a segment level. When segments differ in business value, such as the not uncommon case when 20% of your customers drive 80% of your profits, this can lead to situations where a model with better global accuracy can underperform a model with higher segment performance but lower global accuracy. These limits can lead to unexpected and surprising real world results. ML models can often appear to be performant against test and train data, but not generalize well and perform poorly in real world use since they were not thoroughly evaluated across a range of metrics before being moved into production.
- Manual: Testing is too manual and time consuming. Today most data scientists test their models through manual model evaluation, selection and validation. Model evaluation and selection consists of data scientists manually performing analyses and checks on one or more models and assessing the quality of the models on an absolute and/or comparative basis. However, because these checks are manual, they can take a lot of time. This leads data scientists to sometimes cut corners such as not checking for conceptual soundness across all of the model features, performing out-of-time analyses, stress testing, or assessing the performance across all relevant segments ML teams often face a choice of long lead times in building models if they want to perform comprehensive model evaluations or validations. These efforts are often performed by separate teams, and run the risk of lower performance or unexpected results.
- Adhoc: Testing is too unsystematic and non-repeatable. Testing is done on a sporadic, ad-hoc basis today, such as ad-hoc manual evaluation by a single data scientist; ad-hoc reviews with key stakeholders; and limited or no verification testing prior to production. This often leads to large disparities in model quality. Testing is also often undocumented, limiting the knowledge of a key model to one person or a small number of individuals. Ad-hoc testing is often not repeatable, so it’s hard to show consistent and systematic progress.
Overall, today’s non-comprehensive, manual, and ad-hoc testing tools and methodologies lead to low AI quality, post-production surprises, and uneven business results.
Current ML debugging tools and methodologies have similar problems. They are:
- Guesswork-based: most debugging tools and techniques don’t support true causal root cause analysis, forcing data scientists to make educated guesses as to the cause of bugs. Most tools enable data scientists to calculate stats around model performance between different distributions of data such as test-and-train sets or a period of time showing lower performance than the original model baselines. These stats can be used to make guesses as to how changes in feature inputs might be contributing to changes in model outputs, but don’t do a great job of understanding how changes in inputs are contributing to changes in outputs and model performance. As a result, it can be hard to truly debug ML models. Sometimes data scientists identify correlations that could be a root cause of a performance issue. But often, no clear root cause can be found leaving the data scientists to ignore the problem or make an outright guess.
- Slow: Model debugging and optimization often takes far too long. The debugging process described above can often require large amounts of time to complete. Often, data scientists go down rabbit holes without finding the root cause. As a result, ML debugging exercises can be hugely time consuming, taking time away from other goals such as building the next iteration of the model.
There’s a better way – systematic, comprehensive, and integrated testing and debugging
TruEra’s latest Diagnostics 2.0 release addresses the gap in ML development tools and methodologies by providing a comprehensive, automated testing harness with integrated debugging.
Key elements of TruEra’s testing and debugging capabilities include:
- Automated testing harness: TruEra enables ML teams to create a comprehensive set of AI quality tests, including those for global and segment performance, stability, bias and more. Tests can be created once and then programmatically run against any number of additional models, saving data scientists considerable time during model evaluation, selection, or validation. Tests can fail or warn based on absolute thresholds or thresholds based on comparisons between models.
As a result, tests can be used throughout the lifecycle, from programmatic evaluation of multiple training experiments to automatic testing of re-trained models against their prior versions.
- Root Cause Analysis. For each type of test, TruEra provides methods for performing root cause analysis, enabling data scientists to efficiently and rapidly debug testing failures. Unlike other solutions, TruEra supports true root cause analysis capabilities. Data scientists can understand precisely how much the differences in feature distributions contribute to outcomes, such as declines in accuracy or scores, or differences in bias metrics such as disparate impact ratios. Most other root cause analysis capabilities only calculate statistics around feature values for different distributions. This leaves data scientists guessing as to which statistical differences might be contributing to drift or bias.
- Easily integrated into the existing AI stacks. TruEra’s testing and debugging capabilities are supported in our SDK and GUI, and via APIs. As a result, they can be easily and programmatically integrated into most customer development environments and pipelines, making it a snap for data scientists to incorporate into their existing workflow. TruEra’s testing and debugging functionality can be accessed via notebooks and the TruEra GUI; results can be easily exported into other systems such as Business Intelligence (BI) or custom reporting tools.
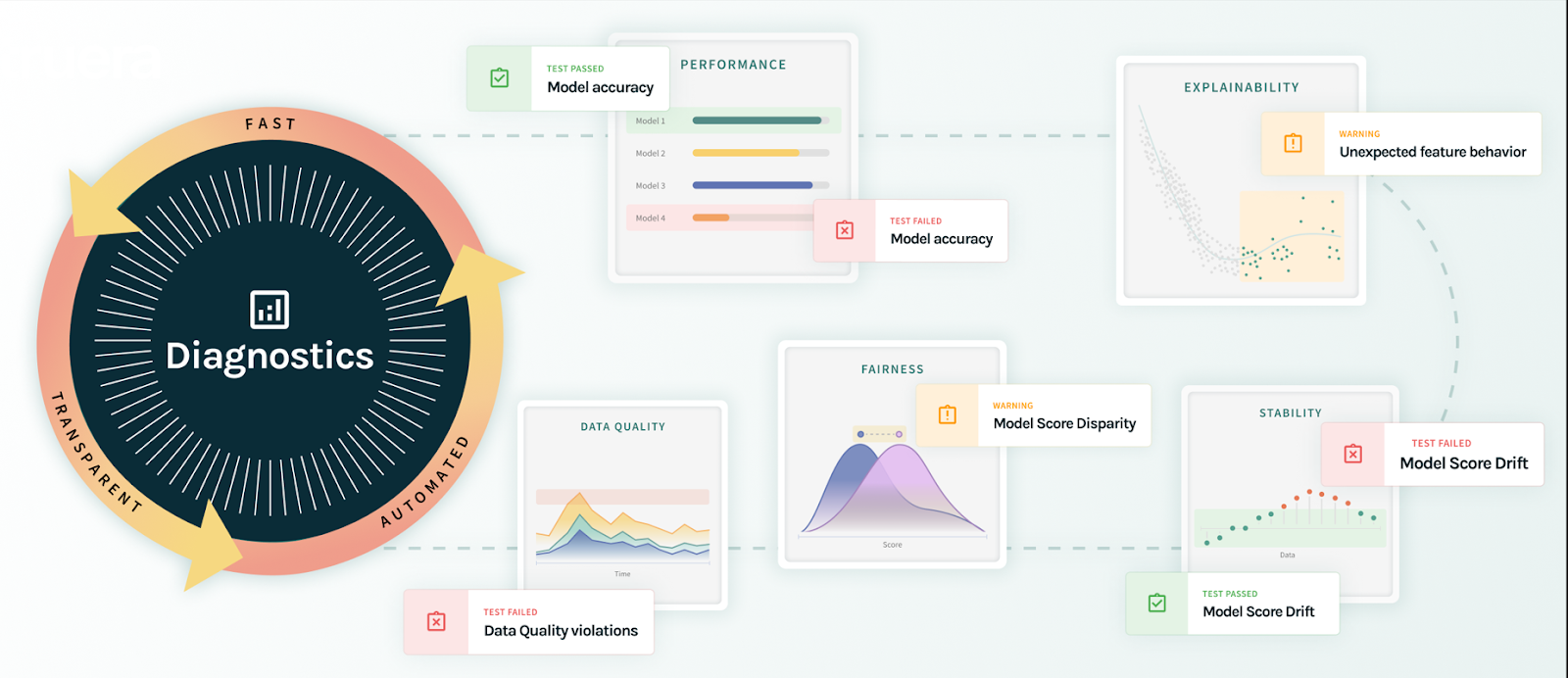
TruEra Diagnostics 2.0 provides a systematic, automated approach for driving model development and high quality AI.
Data Science and ML Leaders are clamoring for a test harness.
We’ve talked to hundreds of business, data science, and ML engineering leaders about their ML development processes and tools over the last three years and found that few ML teams are satisfied with their level of ML testing and debugging. Most teams see many opportunities to use testing and debugging capabilities including but not limited to:
- Programmatic testing of multiple experimental models during iterative development. Automated TruEra testing can be used to improve evaluation comprehensiveness and to accelerate the time required for model evaluation and selection.
- Automated testing of frequently re-trained models. Most teams report that they either do limited to no testing of re-trained models or have to use expensive AB testing methods, which limit the frequency of re-training.
- Programmatic model validation. Regulated uses of ML often require a separate model validation step which can require significant work and calendar time. Creating automated model validation tests can increase the reach of model validation teams and reduce the calendar and work time associated with model risk management.
- Verification testing. Testing models prior to and after promotion from development to production environments.
We’ve also run an AI Quality course for data scientists that has had well over 1,000 registrants over the last 12 months. One thing comes out loud and clear – better tools are needed for managing the ML development process and driving higher model quality. We think that TruEra Diagnostics 2.0 and the automated test harness meet this need and will make the lives of data scientists and ML engineers easier, while enabling ML systems to get to the same level of quality that we see in software systems today.
What else is new in TruEra Diagnostics 2.0?
The new major capabilities in TruEra Diagnostics 2.0 include:
- Automated Test Harness
Systematic testing for evaluating models across a broad array of critical model metrics - Automated Error Analysis
Ability to look at certain segments of a model with high error issues - Model Leaderboard and Model Summary Dashboards
The cross-model leaderboard quickly shows status across multiple models. The detailed model summary dashboard provides critical details about model performance of an individual model. - Enhanced Data Quality Analytics
Tool that analyzes data inputs to check for data integrity weaknesses that might be impacting the model.
TruEra Diagnostics 2.0, ML testing and the ML test harness are all part of our dedication to advancing AI Quality. What is that? Check out this blog from our Chief Scientist: “What is AI Quality? A framework”
This blog has been republished by AIIA. To view the original article, please click here: https://truera.com/ml-testing-and-debugging-the-missing-piece-in-ai-development/
Recent Comments