Businesses in almost every industry are adopting Machine Learning (ML) technology. Businesses look towards ML Infrastructure platforms to help them best leverage artificial intelligence (AI).
Understanding the various platforms and offerings can be a challenge. The ML Infrastructure space is crowded, confusing, and complex. There are a number of platforms and tools, which each have a variety of functions across the model building workflow.
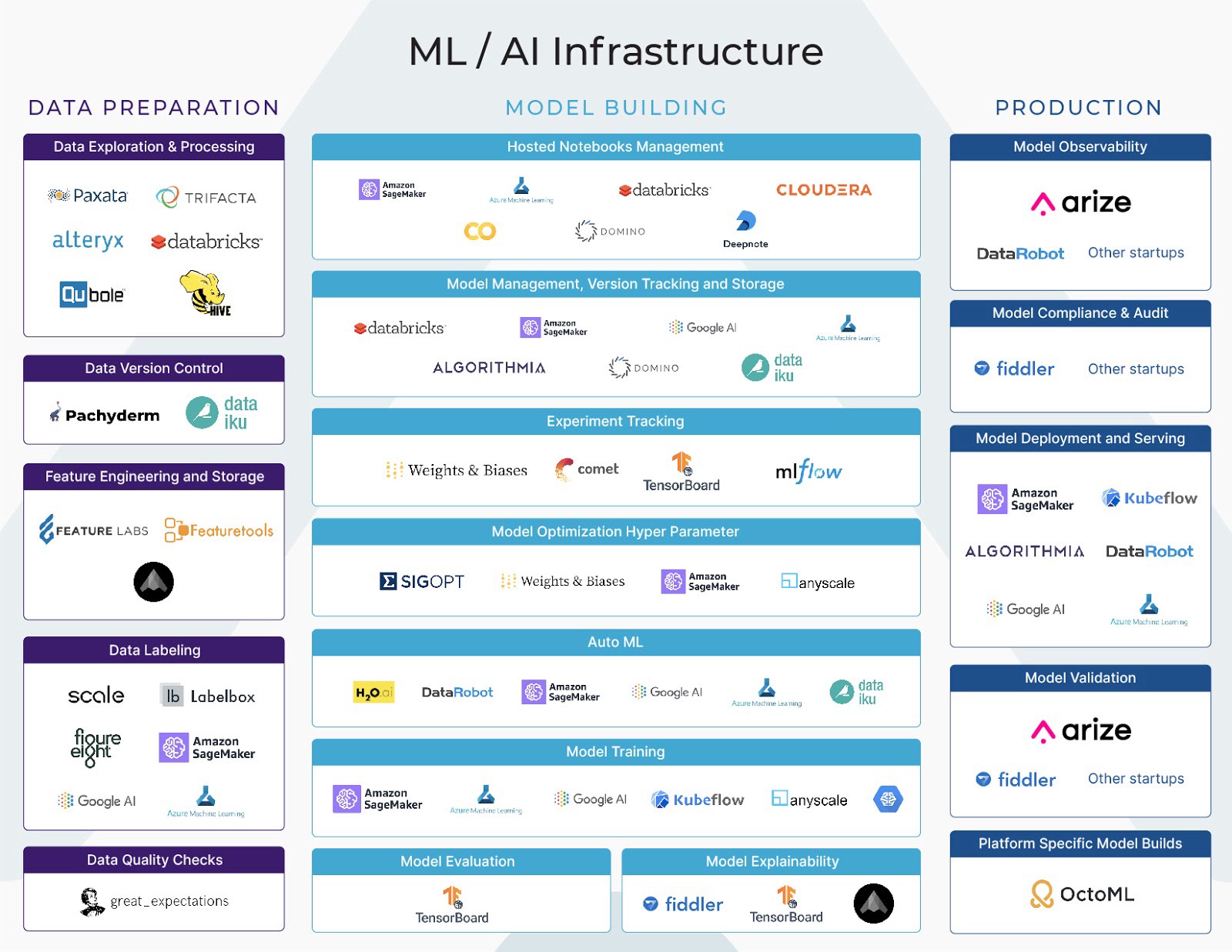
To understand the ML infrastructure ecosystem, we can broadly segment the machine learning workflow into three stages — data preparation, model building, and production. Data preparation refers to the processing and augmentation of data for use by models, while model building refers to a model built based on the data, and production integrates model predictions into the business.
Understanding the goals and challenges of each stage of the workflow can help you make the most informed decision on what ML Infrastructure platforms out there are best suited for your business’ needs.
Each of these stages of the Machine Learning workflow (Data Preparation, Model Building, and Production) have a number of vertical functions. Some platforms cover all three functions across the ML workflow, while other platforms focus on single functions (for example, experiment tracking or hyperparameter tuning).
In our previous posts, we examined the Data Preparation and Model Building parts of the ML workflow. We began diving into Production ML and discussed model validation at length. In this post, we will dive deeper into Production and focus on model deployment and serving.
Model Deployment and Serving
Once the model has been trained, built, and validated, it is finally time to deploy and serve the model! In this last step of ML, all of the work of the previous steps are finally put to use by a data-driven model.
The first decision that teams need to make is whether they should even build a model server at all. Most models deployed in the last five years were home-built serving approaches. In recent years, however, companies working with ML models have moved away from building everything from scratch. In fact, we predict that the approach of building everything from scratch will change drastically going forward, given the number of model servers coming to market.
Model serving options for models typically fit into a couple different types:
- Internally built executable (PKL File/Java) — containerized & non-containerized
- Cloud ML Provider — Amazon SageMaker, Azure ML, Google AI
- Batch or Stream: Hosted & On-Prem — Algorithmia, Spark/Databricks, Paperspace
- Open Source — TensorFlow Serving, Kubeflow, Seldon, Anyscale, etc.
Which of these is the right choice for a given team? There are a number of considerations in the decision of model serving options. Here are a few questions teams ask themselves to determine which is the best ML option for them:
Key Questions to Consider
- What are the data security requirements of the organization?
On-premise ML solutions may be required for organizations with strict data security requirements. Some good choices are Algorithmia, Seldon, Tensorflow, Kubeflow, or home- built proprietary solutions. Some providers such as Algorithmia have security specific feature sets detailed below. Cloud solutions may be a better choice for those organizations needing less security but more remote access/virtualization.
2. Does the team want managed or unmanaged solutions for model serving?
A managed solution such as Algorithmia, SageMaker, Google ML, Azure, and Paperspace are a good idea for companies with a low IT presence. An un-managed solution such as Kubeflow, Seldon, Tensorflow Serving, or Anyscale may be better for more technical organizations.
3. Is every team in the organization going to use the same deployment option?
Even if one team chooses a serving option, rarely is the whole organization using the same serving approach. Having common model management platform like ML-Flow can still help bridge the gap.
4. What does the final model look like? Is there an already established interface?
If a model is already deployed, it might not make sense to rip out the model serving system and replace it with a new model server. How easy it would be to replace the already-deployed model might depend on the model server that was chosen and its integrations with other systems, APIs, and Feature Pipelines.
5. Where does the model executable live? (for example, ML Flow or S3 Bucket)
Easy integration to ML-Flow or model storage systems is an important consideration.
6. Is GPU inference needed?
Predictions using GPU servers based on performance requirements will likely drive you to either cloud providers or Algorithmia for on-premises.
7. Are there separate feature generation pipelines or are they integrated into the model server?
Depending on where your feature pipelines are deployed, say, Amazon Web Services (AWS), that might direct you toward using SageMaker. This is probably one of more common reasons to use SageMaker as data is already deployed in AWS.
Deployment Details
The format of the model can vary, based on the frameworks used to build the model, across organizations and projects. Some example formats include a pickle image of weights/parameters for the classifier, a Tensorflow SavedModel object, a Pytorch model, Keras model, XGBoost model, Apache TVM, MXNet, ONNX Runtime, etc.
Implementation
There are many ways that ML models can be implemented. These models can be integrated into a larger system’s codebase, deployed as a microservice, or even live on a device. If the model is code that is integrated into a larger system, the interface into the model is simply a function call. If the model is in its own service/executable or server, it can be seen as a service. These services have well defined APIs or interfaces to pass inputs to the models and get responses.The model servers described above take the trained model artifact generated in the above formats and allow you to deploy it to a containerized model server that generates well defined APIs.
Containerization
A modern server approach is to containerize the model executable so there is a common interface into models and a common way of standing them up. The model is pulled from the model management system (such as ML-Flow) into a container when it is deployed. There are many ways to accomplish this, either building a custom container for your company, using open source solutions like KubeFlow or Seldon AI, or using the common cloud provider tools such as Algorithmia, SageMaker, Azure or Google AI.
Real-Time or Batch Model
Another important deployment consideration to make is whether to have a real-time/online model or a batch model. Online models are used when predictions need to be immediate and take in real-time application input. If this isn’t a requirement, batch inferences can be appropriate.
A number of serving platforms allow you to build a single model and have different deployment options (Batch or Real Time) to support both types of serving regimes.
Things to Look for in Model Servers
Easy Scale Out:
As the prediction volume grows of an application, the initial approach of having a single server supporting predictions can get easily overwhelmed. The ability to simply add servers to a prediction service, without the need to re-architect or generate a large amount of additional model operations work, is one of the more useful features of a model server.
Canary A/B Framework:
A canary A/B framework allows developers to roll out software to a small subset of users to perform A/B testing to figure out which aspects of the software are most useful and provide the best functionality for users. Once deployed, some teams run a A/B (canary) model side-by-side with the production model, initially predicting on only a small subset of traffic for the new model. This is done as a simple test before deploying the new model across the full volume of predictions. A lot of teams we talk to have home-built their own A/B testing framework. That said, some of the model server solutions also support easy A/B deployments out of the box, for example, to choose the % of traffic to the B model with the click of a button.
Ensemble Support:
The ability to co-locate multiple models in the same server or easily connect the prediction (inference) flow between models might be an important consideration. Most of the time, the model response will be consumed by the end application, but as systems get more complex, some models’ outputs are inputs to another model. In cases of fast prediction response, co-locating models can be desired.
Fall Back Support:
As you deploy a new model into production, you might find that performance drops drastically. The ability to have a different model, maybe a previous version or a very simple model during periods of degraded performance, can be very helpful in situations like this.
Security:
If security is extremely important to the organization, some platforms have very well thought out security feature sets. These span a set of security requirements focused on: access rights, application security, network security, and memory security. The model in production needs to grab data/inputs from somewhere in the system, and it needs to generate predictions/outputs used by other systems. The application who has access to the predictions might not have rights to the input data. Also, if the application is using Python packages in a Kubernetes-hosted model, many companies want to make certain that those packages are not public packages. Lastly, if you are running in a shared memory environment like a GPU, you will need to take stock of what data protections you have in place around memory encryption and access. Some platforms, such as Algorithmia, have more developed security feature sets that provide solutions for a myriad of situations.
Feature Pipeline Support:
In containerized solutions, input-to-feature transformations may reside in the container itself, or may have separate feature transformation pipelines. The larger the infrastructure, the more likely the input-to-feature transformation is a pipeline or feature store system with inputs to the container being pre-processed.
In the serving layer, there are also some new platforms such as Tecton AI which are focused on feature serving. A global feature store allows teams to easily deploy the feature pipeline directly into production environments — minimizing feature pipeline mistakes, and allowing teams to take advantage of cross-company feature builds.
Monitoring:
Some model servers support basic monitoring solutions. Some servers support monitoring for serving infrastructure, memory usage, and other operational aspects. Our view is that this type of raw model ops monitoring and visualization is important to model scale out, but is not observability. We are obviously biased, but have an opinion that true model observability is really a separate platform.
Example ML Infrastructure Platforms for Deployment and Serving include Datarobot, H2O.ai, Sagemaker, Azure, Google Kubeflow, and Tecton AI.
Model Observability vs Model Monitoring
It may seem like anyone can do monitoring — green lights are good, and red lights are bad. You can set alerts, and if a value falls below a certain level, this triggers sending an email to the staff.
Yet, if that were the case, Amazon Cloud Watch would have killed Datadog.
The issue here is — what do you do when you get that alert?
Our opinion is that the difference between a monitoring solution and an Observability platform is the ability to troubleshoot and bottom out issues seamlessly. In the ML ecosystem, these problems surface as issues linking AI research to engineering. Is the platform designed from the bottom up to troubleshoot problems, or was an alerting system tacked on to some pre-existing graphs? Troubleshooting models + data in the real world is a large and complex space. That’s why Observability platforms are designed from the ground up to help research and engineering teams jointly tackle these problems.
Why the model server is not a great spot for Observability:
The model server does not have the right data points to link the complex layers needed to analyze models. The model server is missing essential data such as training data, test runs, pre-one hot encoded feature data, truth/label events, and much more. In the case of feature data, for a number of larger models we have worked on, the insertion point into the data pipeline for troubleshooting is a very different technology than the model server. Lastly, many organizations have as many model serving approaches as they have models in production, and it is very unlikely they will move to a single server to rule them all. What happens when you have a mix of models served that feed each other data but you want a cohesive picture?
It’s the same in software infrastructure; your infrastructure observability solutions are not tied to the infrastructure itself.
Up Next
We hope you enjoyed the ML Infrastructure series! Up next, we will be diving deeper into Production AI. There are so many under-discussed and extremely important topics on operationalizing AI that we will be diving into!
Contact Us
To read more of our thoughts on the potential of AI and ML, follow us on Twitter and Medium!
Arize AI is laser-focused on Production ML. If you’d like to hear more about what we’re doing at Arize AI, reach out to us at contacts@arize.com. If you’re interested in joining a fun, rockstar engineering crew to help make models successful in production, reach out to us at jobs@arize.com!
Recent Comments