
At Galileo, we strongly believe that the key to unlocking robust models is clean, well formed datasets. Although data quality issues are prevalent in production datasets, most modern solutions aren’t built to address these problems effectively. Rather, modern approaches often focus on changing the model configurations or getting more data in the hopes of improved generalization. However, with critical unaddressed flaws in the dataset, this paradigm can cause cause model bias, inaccurate performance metrics, and even worse consequences in production.
Galileo tackles this issue head on. To show it in action, we are kicking-off a series of blogs on Improving Your ML Datasets With Galileo. In these blogs we analyze various benchmark datasets in academia / industry using Galileo, and surface crucial errors and ambiguities within minutes! Without Galileo, this process could take several days of expensive debugging and reannotation effort.
As we release these blogs, we’ll also make the improved datasets publicly available here for anyone around the 🌎 to use!
(Subscribe to our blog or Slack channel to follow along with this series)
Let’s dive right in!
Dataset & Model
Dataset: 20 Newsgroups, a classification task for identifying the newsgroup of various posts on the forum, classifying them into one of twenty classes.
Model: We use a standard Distil-BERT model for our experiments, which achieves a respectable F1 of 0.9 on training, 0.75 on validation, and 0.69 on test splits of the dataset. To keep gains from subsequent iterations attributable purely to fixing the datasets, we hold model parameters constant and use the recommended configurations.
Fixing ‘20 Newsgroups’ with Galileo
While exploring the Newsgroups dataset, we quickly uncover a number of interesting issues and insights. Below we showcase some of these erroneous patterns, and subsequently, we demonstrate how fixing these dataset errors leads to immediate improvements in model performance (results below).
Dataset Error #1: Empty Samples
Galileo’s embeddings visualization quickly surfaces an island, with points colored by ground-truth label far from the rest of the data. The presence of different ground-truth samples in that cluster shows the model is able to find similarity in spite of differences in labels.

By selecting the samples in this cluster and inspecting them in Galileo’s dataframe view, we see over 200 empty samples (~3%)! Additionally, the label distribution of these samples is spread quite evenly throughout all 20 classes.
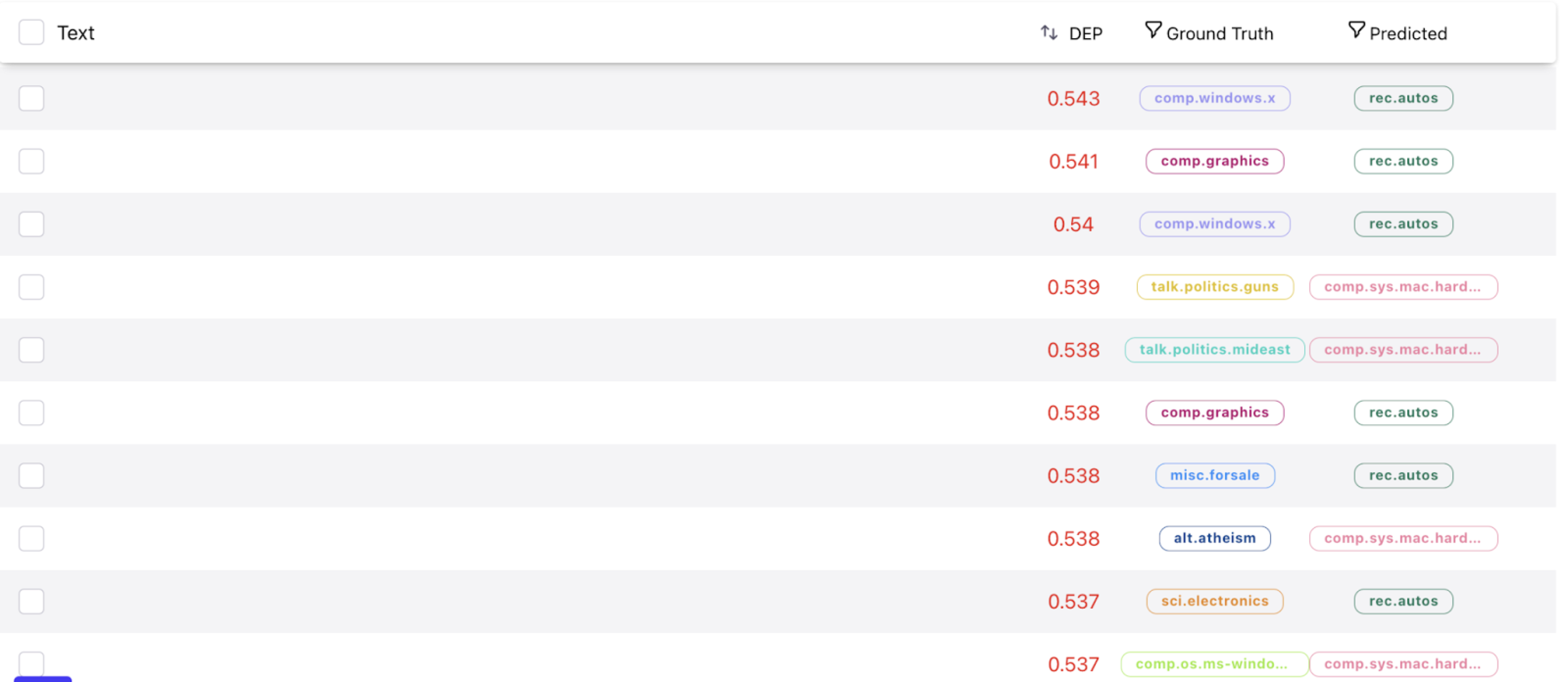
From this inspection we glean that these empty samples might be interfering with the model’s ability to predict / distinguish these classes.
Dataset Error #2: Garbage samples
Continuing to look at different clusters (again colored by ground truth) in our embeddings view, we find an “isolated coast” of samples from many different classes. These samples are likely not empty (because they are close to many others), but nonetheless they are confusing for the model. Through Galileo, we can quickly ascertain where the problem lies for these samples.

Upon selecting them, we find an expected low F1, as well as a large class distribution. The dataframe view shows a collection of short, ill-formed samples with a myriad of different ground truth labels. Because these samples do not fit an existing label category, they increase confusion during the training process. From this insight, we further explore short samples (non-empty but <= 100 chars long) to see if there is a wider pattern. We see more ill-formed samples, capturing ~7% of the dataset, which certainly warrants further investigation!
In fact, we find that about half (3.5%) of these samples are indeed garbage.
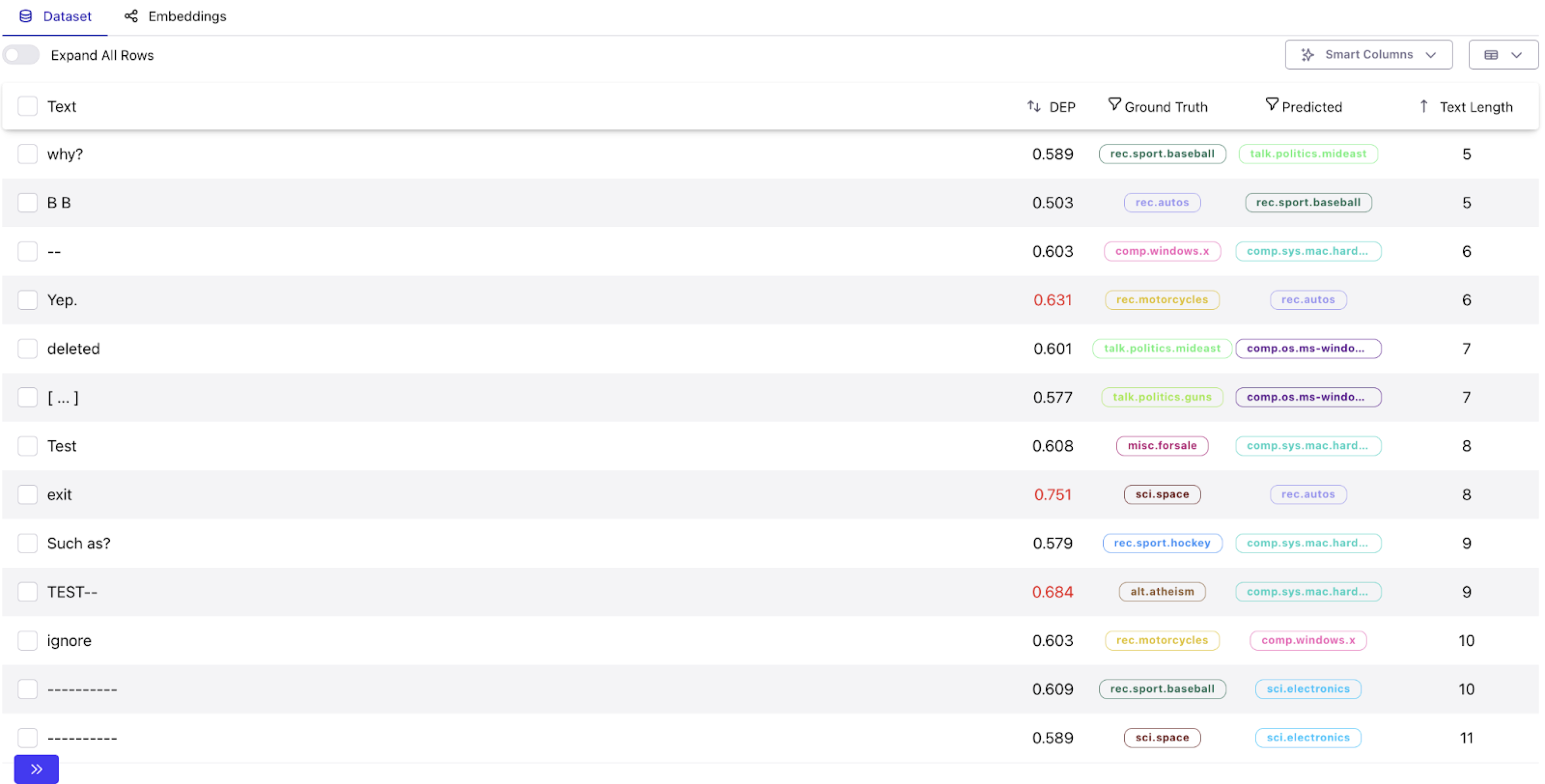
By this point, Galileo has enabled us to identify 6.5% of malformed samples across the dataset, all with minimal exploration time.
Dataset Error #3: Labeling Errors
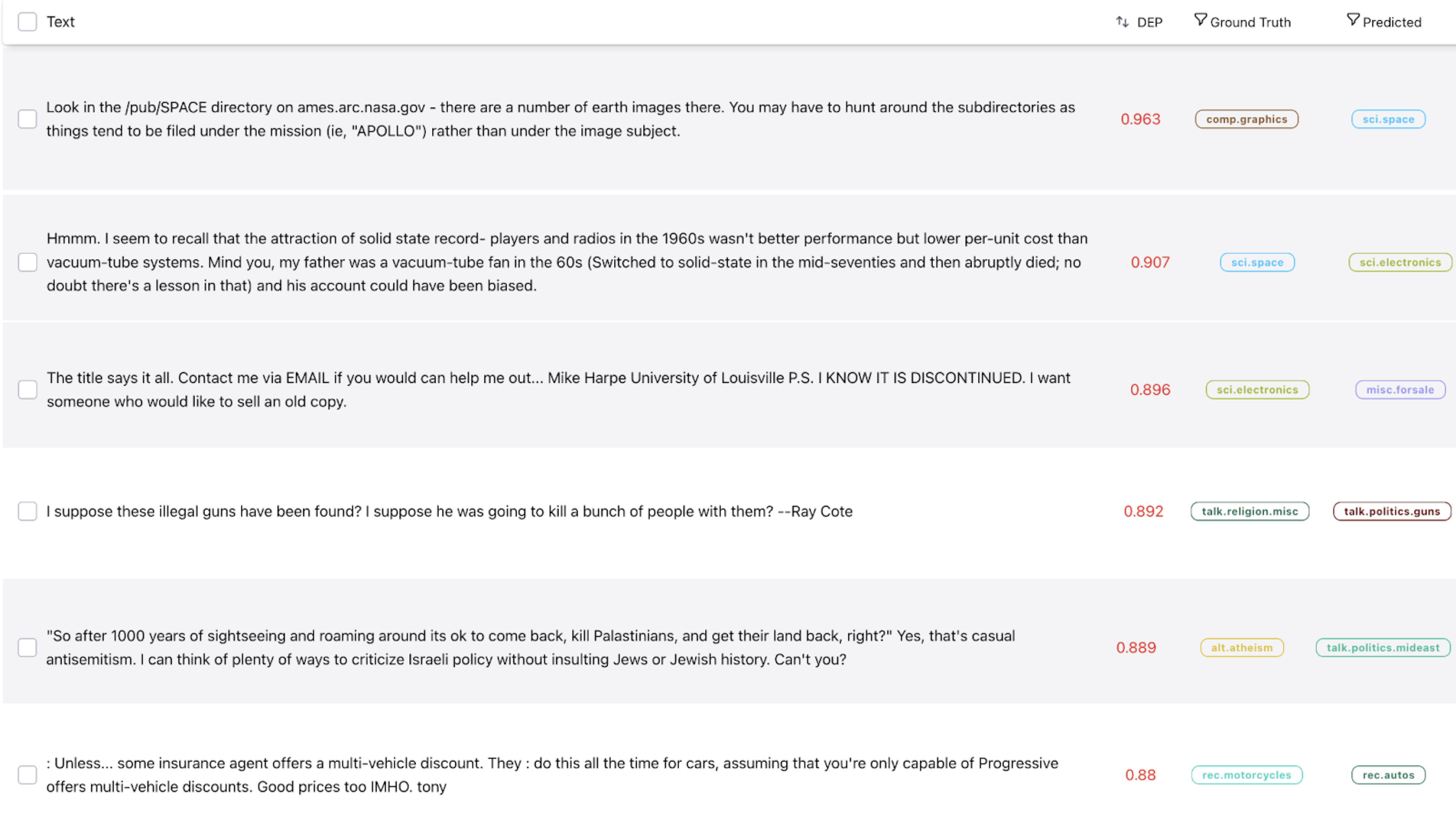
Using Galileo’s Data Error Potential (DEP) Score1 to guide the discovery process, we uncover samples that are confusing to the model, either because of human labeling errors or semantic overlap between classes. A high DEP score denotes a sample being hard for the model to learn from, which can lead to weaker generalizations. Overall, DEP is a powerful tool for rapidly uncovering data errors which are otherwise found with ad-hoc exploration.
Due to the source of this dataset, we cannot definitively say that samples uncovered through DEP analysis are mislabeled, as they are merely excerpts taken from newsgroup forums such as reddit. For instance, a given thread about cars may come from a forum about guns. In such scenarios, the subject matter in the text sample does not align with the forum, leading to a label that is misleading or garbage to the model without the necessary context.
Here are a few of our favorites (from the 290 samples uncovered):
Dataset Error #4: Class Overlap
By looking at class-level metrics in Galileo, we observe that the talk.religion.misc class is particularly low performing. Furthermore, this label has the highest DEP score and the lowest class distribution, with only 323 samples in the training set.
Digging deeper, we discover that there are two other semantically very similar classes: alt.atheism and soc.religion.christian. Unsurprisingly, we confirm that talk.religion.misc is often confused for these similar classes. The Top Misclassified Pairs matrix below highlights this confusion.

Using Galileo to analyze these samples, we see the high level of ambiguity. Moreover, we note note that over 50% of original samples labeled talk.religion.misc in the training data are flagged by Galileo as particularly hard for the model, representing 2.8% of the dataset!
It may be the case that there are simply not enough inherent differences between the three classes (talk.religion.misc, alt.atheism, soc.religion.christian) to warrant such a fine grained distinction.
Actions Taken
Based on the insights above, we now demonstrate how addressing these dataset errors can directly improve model performance. For this experiment, we restrict our actions to fixing the empty and garbage samples identified in the first two insights. These insights are both fast to discover and easy to address with Galileo.
Rather than removing these samples, we propose adding a new “None” label to the dataset. In this way, the model can become robust towards such garbage samples through learning to identify them as a separate class. In our experiments, we first fix the errors just in the training dataset.
However, we find that very similar errors exist in the test dataset as well. To accurately track our model’s ability to generalize its prediction over garbage data, we take the additional step of fixing the test dataset. Although guided by Galileo, we additionally inspect selected samples with a human annotator.
Note that in an ideal production setting the test dataset is stringently screened and held as a true gold standard; however, we have found that for many public datasets beyond just Newsgroups, this is not the case – issues that exist in the training sets are often found within test data.
Results
Looking at the results below, we see that by just fixing errors in the training dataset, model performance improves. This is particularly noteworthy because we have not yet relabeled any test data to reflect the new None class. Therefore, the improvements are due solely to the removal of label noise within the training data, which allows the model to learn a more generalizable representation of non-garbage data.
To then test the model’s ability to generalize on garbage data and predict the new None class, we run the model over the cleaned, human validated test dataset. The results show a dramatic improvement in absolute performance. We emphasize that although we have cleaned the test dataset, the model must learn a general representation of garbage data in order to properly predict over the test dataset. Therefore, the observed improvement comes from the model’s newly learned understanding of garbage data, for which the baseline model performed no better than randomly guessing the labels.
Total Dataset Errors Fixed: 1163 (6.5% of 18,000 samples in the dataset)
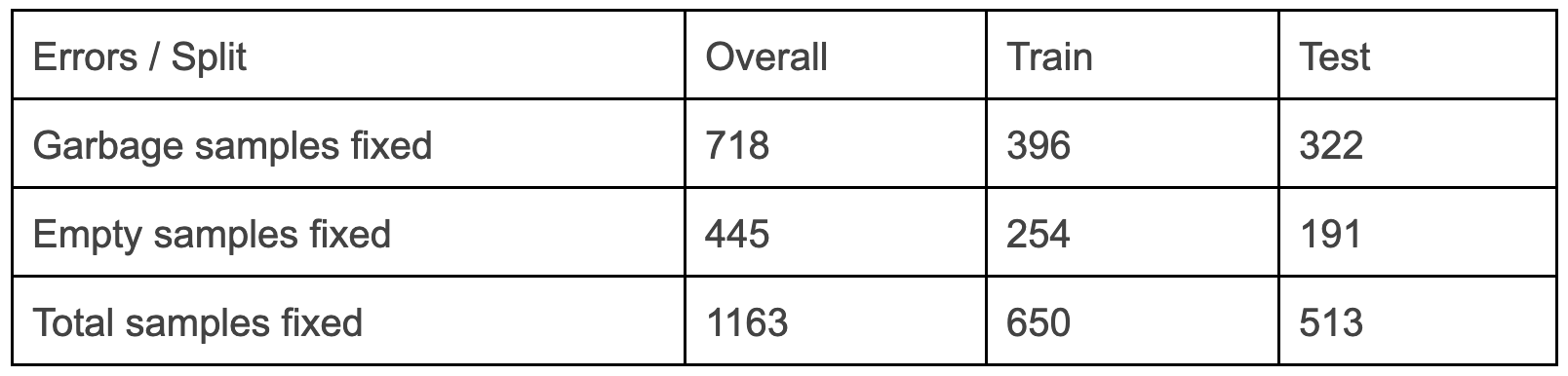
Note: that these errors fixed can seem trivial, but Galileo surfaces many such “unknown-unknowns” from datasets which we will continue to showcase in this series of blogs.
You can access the fixed dataset here.
Quality Impact

Conclusion
In this short experiment, we have fixed 6.5% of the dataset within 10 minutes, with a 7.24% overall performance improvement.
We call this practice of inspecting, analyzing and fixing crucial data blindspots – ML Data Intelligence. This quick experiment (which surfaced many nuanced issues in a highly peer-reviewed dataset) underlines the importance of this practice. Galileo short-circuits this process and solves for these necessary steps in the ML lifecycle.
If you have thoughts, feedback or ideas for other datasets we can tackle, please join our Slack Community and let us know. If you want to use Galileo within your team, we would love to chat!
1 Details on the DEP score to follow in later articles
2 Model performance was measured over 5 random seeds
This blog has been republished by AIIA. To view the original article, please click HERE.
Recent Comments