
Photo by Pietro Jeng on Unsplash
A tutorial on how you can combine ydata-synthetic with great expectations
With the rapid evolution of machine learning algorithms and coding frameworks, the lack of high-quality data is the real bottleneck in the AI industry.
Transform 2019 of VentureBeat predicted that 87% of AI projects would never make it into production. According to a 2017 Harvard Business Review study, only 3% of companies’ data meets basic quality standards.
This wouldn’t have been a surprise to you if you’re working in the AI industry — we all have experienced it first hand. Thankfully, we have seen a paradigm shift in the recent past, pioneered by Andrew Ng, moving from a model-centric approach to a data-centric approach.
When used right, synthetic data is one such element that can aid in the data-centric approach. Synthetic data is artificially generated data that is not collected from real-world events. It replicates the statistical components of actual data without containing any identifiable information, ensuring individuals’ privacy. Our open-source library for synthetic data ydata-synthetic focuses solely on this.One of the common concerns we had from our users was how do we ensure that the synthetic data follows all the quality standards of the original data? As much as preserving the statistical properties of the original data, ensuring it follows a rigid data quality standard is essential too.
Luckily our friends at Great Expectations have built and open-sourced a framework they call — a shared, open standard for data quality. When your data team adapts the framework, you know what to expect from your new data.
In this article, we take you through an end-to-end use-case where you use the original data to train a model that synthetic data, validate the synthetic data quality standards against original data using the Great Expectations library.
Combining YData Synthetic and Great Expectations
YData Synthetic is an open-source synthetic data engine. Using different kinds of Generative Adversarial Networks (GANS), the engine learns patterns and statistical properties of original data. It can create endless samples of synthetic data that resemble the original data.
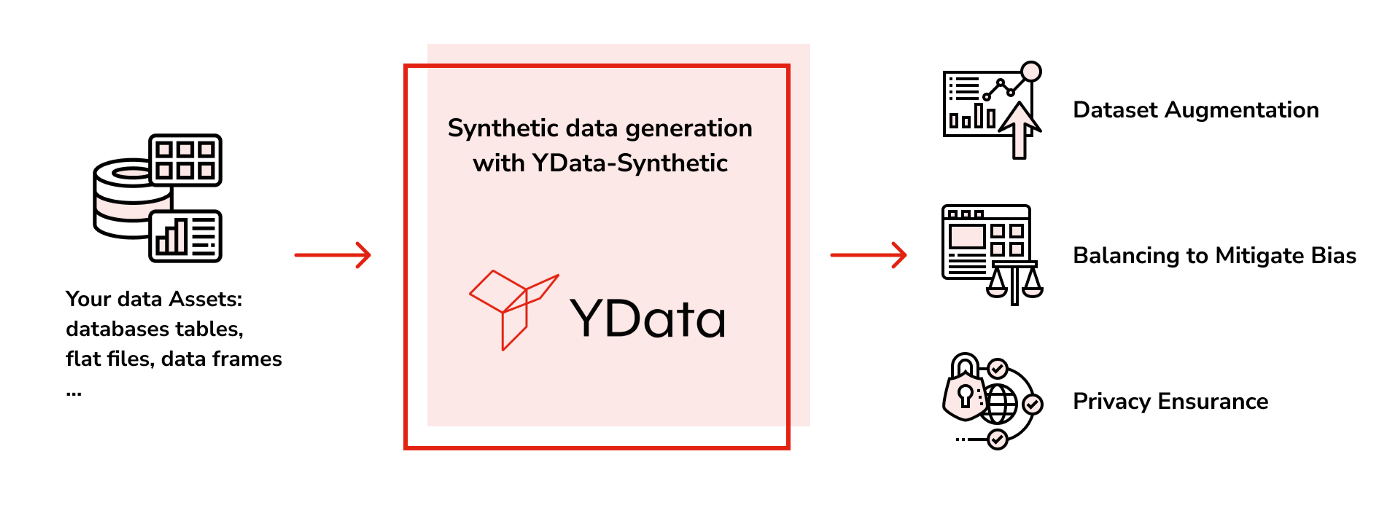
Great Expectations is a tool for validating, documenting, and profiling your data to maintain quality and improve communication between teams. It allows the user to create ‘expectations’ based on a good sample of data and use these expectations to validate if the new data meets the data quality standards.
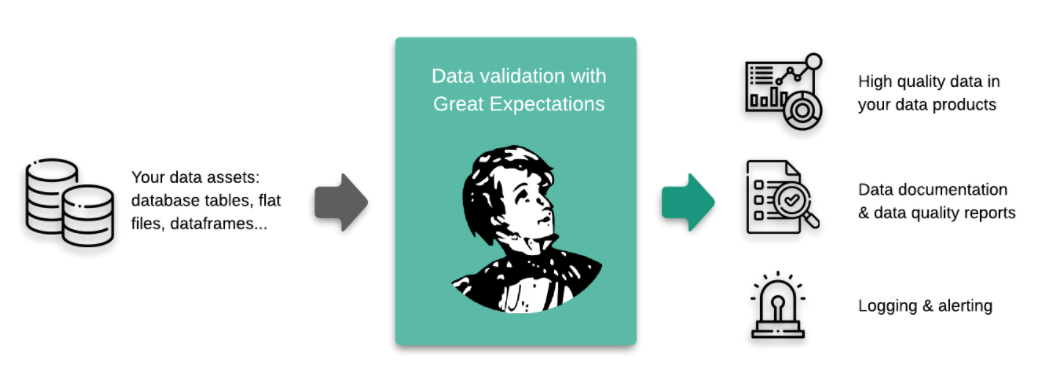
Of course, we kept the introduction simple for the scope of this article, and there’s more to these libraries, which are evolving as we speak. The idea is: both libraries are working towards the same goal, high-quality data at scale on different fronts.
A 10-Step Guide: How to Use Both Tools Hand-in-Hand for Your Next Project
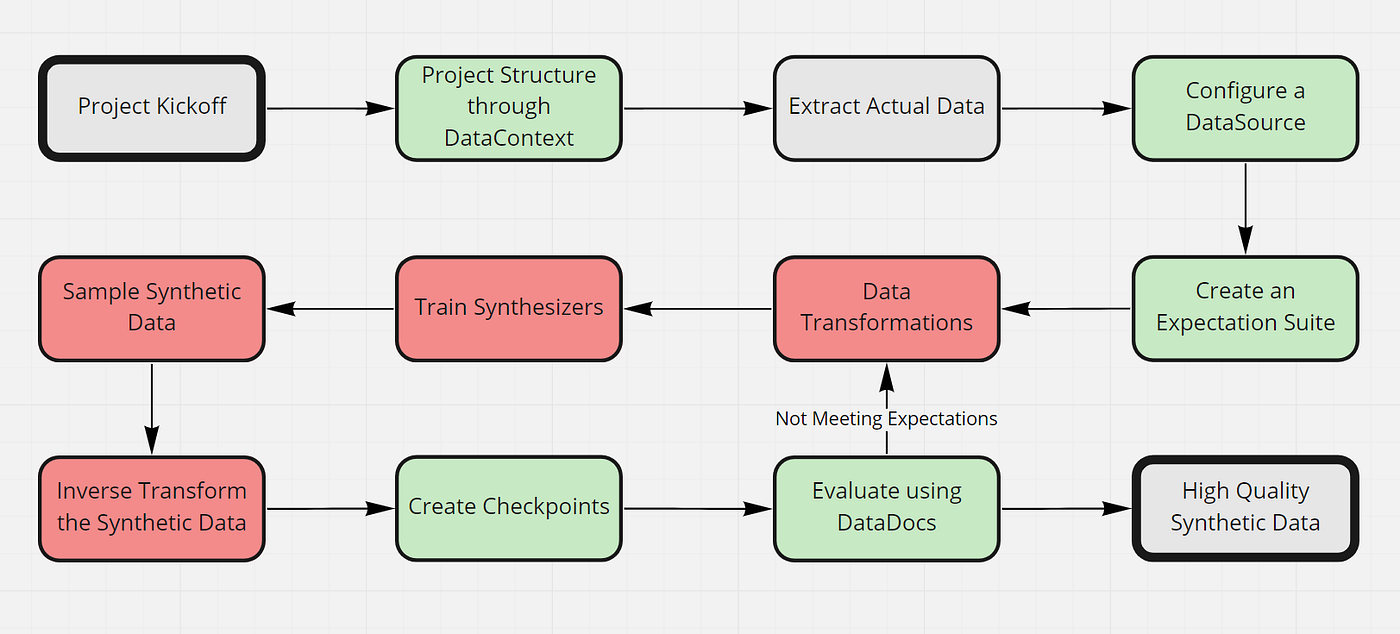
For this guide, we pick a use-case example of “The Credit Card Fraud Dataset — Synthesizing the Minority Class.” We aim to synthesize the minority class of the credit card fraud dataset with a high imbalance.
Imbalanced class data is a common problem when building models, and generating synthetic data for the minority class can help develop more accurate models. However, we need to ensure that the newly generated data points maintain the same quality standards as the original minority class data points.
We will solve this problem by generating synthetic data using YData Synthetic and validating it through Great Expectations.
Before we get started, to follow along with the tutorial, we recommend you create a virtual environment and pip install both ydata-synthetic and great_expectations by running the following on your terminal.
pip install ydata-synthetic great-expectations
Now that you have the environment ready, let’s get started. If you want to follow our steps by steps, you can download the materials from ydata-synthetic GitHub.
Step 1: Setup the project structure through a Data Context
In Great Expectations, your Data Context manages the project configuration. There are multiple ways to create the Data Context; however, the simplest one is by using the CLI that comes along when you install the great_expectations package.
Open your terminal and navigate to the project directory and type in the following:
great_expectations init
Press enter to complete the creation of the Data Context, and that’s about it.
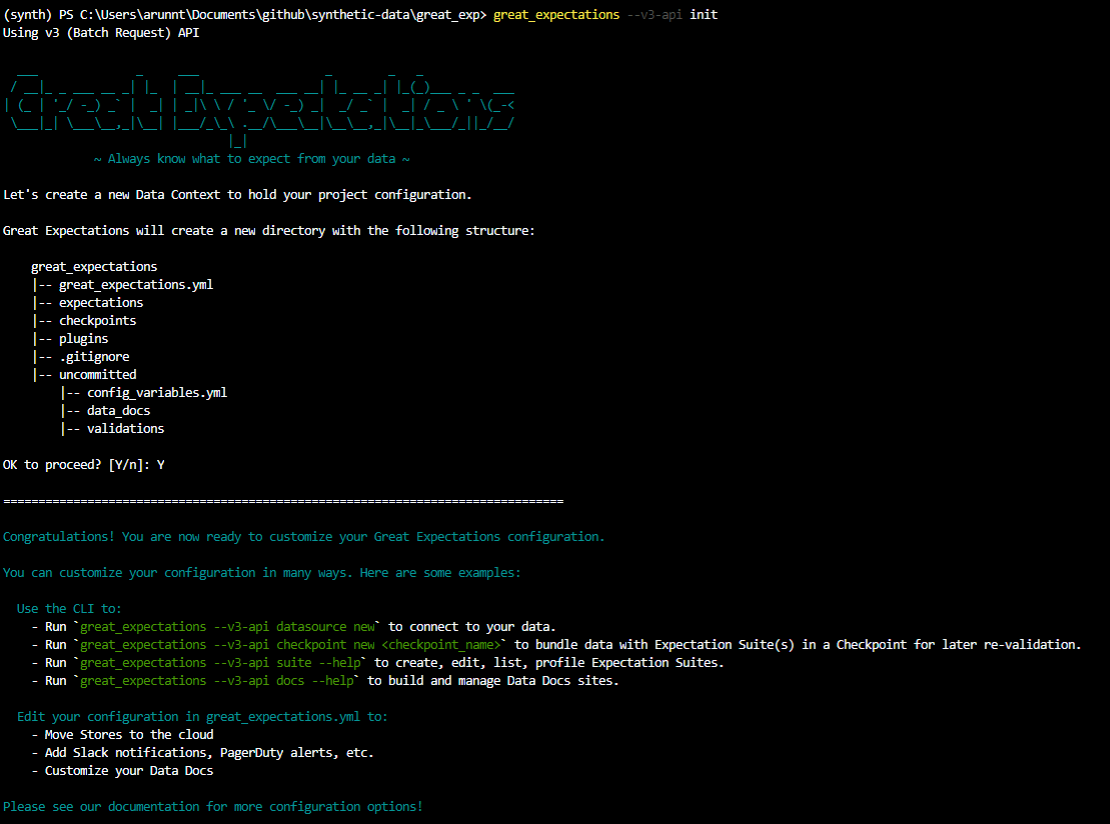
If you’re curious about the modified project structure, here’s an excerpt from the GE documentation:
- great_expectations.yml contains the main configuration of your deployment.
- The
expectations/directory stores all your Expectations as JSON files. If you want to store them somewhere else, you can change that later. - The
plugins/directory holds code for any custom plugins you develop as part of your deployment. - The
uncommitted/directory contains files that shouldn’t live in version control. It has a .gitignore configured to exclude all its contents from version control.
Step 2: Download/Extract the actual data set we use to create synthetic data
We can download the data we use for this example from Kaggle. If you inspect the classes, you’ll notice that the “fraud” class is much lesser than the “not fraud” class, which is the case in real life.
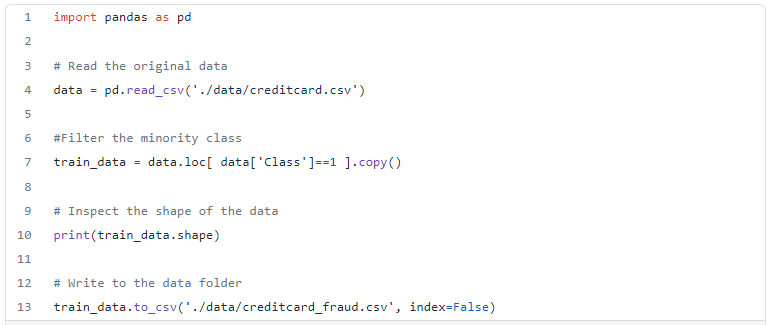
Hence we can extract the fraud class data points only and consider it the actual dataset. We aim to create synthetic data points similar to fraud occurrences.
Step 3: Configure a Data Source to connect our data
In Great Expectations, Datasources simplify connections by managing configuration and providing a consistent, cross-platform API for referencing data.
Let’s configure our first Datasource: a connection to the data directory we’ve provided in the repo. Instead, this could even be a database connection and more.
great_expectations datasource new
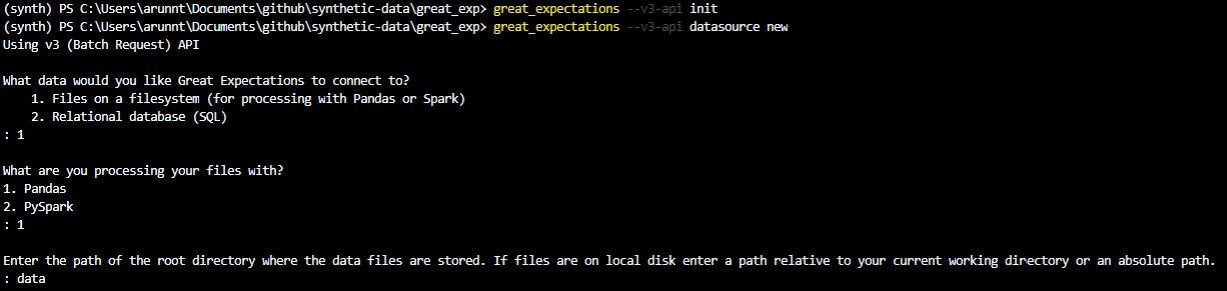
As shown in the image above, you would be presented with different options. Select Files on a filesystem (for processing with Pandas or Spark) and Pandas. Finally, enter the directory as data (where we have our actual data).
Once you’ve entered the details, a jupyter notebook will open up. This is just the way Great Expectations has given templated codes, which helps us create expectations with a few code changes.
Let’s change the Datasource name to something more specific.
Edit the second code cell as follows: datasource_name = "data__dir"
Then execute all cells in the notebook to save the new Datasource. If successful, the last cell will print a list of all Datasources, including the one you just created.
Step 4: Create an Expectation Suite using the built-in Great Expectations profiler
An expectation is nothing but a falsifiable, verifiable statement about data. Expectations provide a language to talk about data characteristics and data quality — humans to humans, humans to machines, and machines to machines.
The idea here is that we assume that the actual data has the ideal quality of the data we want to be synthesized, so we use the actual data to create a set of expectations which we can later use to evaluate our synthetic data.
The CLI will help create our first Expectation Suite. Suites are simply collections of Expectations. We can use the built-in profiler to automatically generate an Expectation Suite called creditcard.quality
Type the following into your terminal:
great_expectations suite new
Again select the options as shown in the image above. We create expectations using the automatic profiler and point it to use the actual dataset.
Again another jupyter notebook would be opened with boilerplate code for creating a new expectation suite. The code is pretty standard; however, please note that all columns are added to the list of ignored columns in the second cell. We want to validate every column in our example; hence we should remove these columns from the ignored_columns list.
Executing the notebook will create an expectation suite against the actual credit card fraud dataset.
Step 5: Transform the real data for modelling
Now that we have created the expectation suite, we shift our focus back to creating the synthetic data.
We follow the standard process of transforming the data before training the GAN. We’re applying PowerTransformation — make data distribution more Gaussian-like.
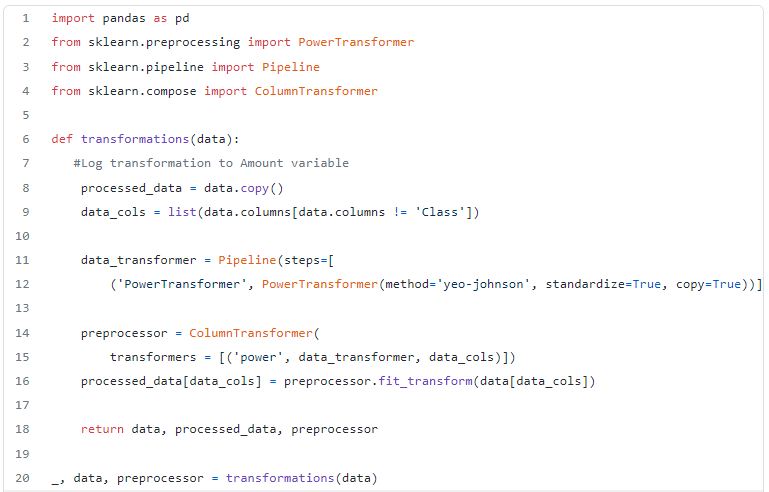
Feel free to experiment with more pre-processing steps as it will yield better results.
Step 6: Train the synthesizers and create the model
Since we have pre-processed our data, it’s time to put our advanced ydata-synthetic GAN models to work.
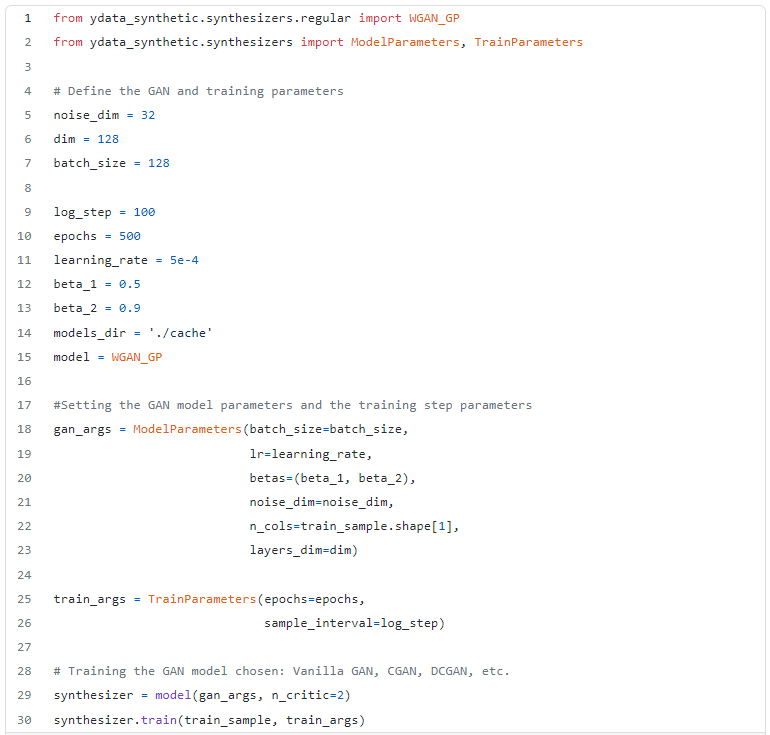
For this example, we train a kind of GAN, called WGAN-GP which provides much-needed training stability.
Step 7: Sample synthetic data from the synthesizer
Since we have built our model, now it’s time to sample the required data by feeding noise. The beauty of this step is you can keep generating data as much as you want. This step is powerful when you want to generate different copies of data that are shareable and sellable.
In our case, we generate an equal number of samples as the actual data.
# use the same shape as the real data
synthetic_fraud = synthesizer.sample(492)
Step 8: Inverse transform the data to obtain the original format
Here we notice that the generated synthetic data is still on the transformed form and needs to be inverse-transformed to the original structure.
synthetic_data = inverse_transform(synthetic_fraud , preprocessor)
Step 9: Create a new checkpoint to validate the synthetic data against the real data
For the regular usage of Great Expectations, the best way to validate data is with a Checkpoint. Checkpoints bundle Batches of data with corresponding Expectation Suites for validation.
From the terminal, run the following command:
great_expectations checkpoint new my_new_checkpoint
This will again open a Jupyter Notebook that will allow you to complete the configuration of our checkpoint. Edit the data_asset_name to reference the data we want to validate to the filename we wrote in step 8. Ensure that the expectation_suite_name is identical to what we created in step 4.
Once done, go ahead and execute all the cells in the notebook.
Step 10: Evaluate the synthetic data using Data Docs
You would have created a new checkpoint to validate the synthetic data if you’ve followed along. The final step is to uncomment the last cell of the checkpoint notebook and execute it.
This will open up an HTML page titled Data Docs. We can inspect the Data Docs for the most recent checkpoint and see that the expectation has failed. By clicking on the checkpoint run, we get a detailed report of which expectations failed from which columns.
Based on this input, we can do either of these actions:
- Go back to our data transformation step, modify transformations, change synthesizers or optimize the parameters to get better synthetic data.
- Go back to the expectation suite and edit a few expectations that are not important (maybe for specific columns). Yes — the expectations are customizable, and here’s how you can do it.
Conclusion
In this tutorial, we have successfully demonstrated the use of ydata-synthetic alongside great expectations.
A 10 step guide was presented, from configuring a data context to evaluating the synthesized data using Data Docs. We believe integrating these two libraries can help data scientists unlock the power of synthetic data with data quality.
You may find all the codes used for this article in our GitHub repository. You wouldn’t want to miss out on the informative workshop series from Great Expectations on their YouTube channel.
Still, got questions? The Synthetic Data Community and our friends at Great Expectations are always willing to help. Join the slack communities, collaborate with other users and ask away all your questions for our developers directly!
This blog has been republished by AIIA. To view the original article, please click HERE.
Recent Comments