
In this article, we will take a look at some of the Hugging Face Transformers library features, in order to fine-tune our model on a custom dataset. The Hugging Face library provides easy-to-use APIs to download, train, and infer state-of-the-art pre-trained models for Natural Language Understanding (NLU) and Natural Language Generation (NLG) tasks.
Some of these tasks are sentiment analysis, question-answering, text summarization, etc. You can get a quick summary of the common NLP tasks supported by HuggingFace here.
Today, we’re going to fine-tune a DistilBERT transformer for sentiment-analysis (binary classification) on an IMDB dataset.
If you want to follow along you can do so with this handy Colab:
Installations and Imports
For this tutorial, we will need HuggingFace (surprise!) & Weights & Biases.
(We will soon look at HuggingFace related imports and what they mean.)
We’ll also be using Weights & Biases to automatically log losses, evaluation metrics, model topology, and gradients( for Trainer only).
When we say it’s easy to install Weights and Biases, we’re telling the truth:

Now that we are ready with the required installations, let’s see how easy it is to fine-tune a HuggingFace Transformer on any dataset for any task.
The Ease of Data Preprocessing with HuggingFace
In this section, we will see how easy it is to preprocess data for training or inference. The main tool for this is a tokenizer which is in charge of preparing the inputs for a model.
The library contains tokenizers for all the models or we can use AutoTokenizer (more on this later).
What Is Tokenizing In NLP?
In NLP, tokenizing a text block involves splitting it into words or subwords, which then are converted to IDs through a look-up table. But splitting a text into smaller chunks is a task that is harder than it looks.
Let’s look at the sentence “Don’t you love Weights & Biases for experiment tracking?” . We can split the sentence by spaces, which would give:
This looks sensible, but if we look at the token “tracking?”, we notice that punctuation is attached to it which might confuse the model. “Don’t” stands for do not so it can be tokenized as [“Do”, “n’t”].
This is where things start to get complicated and part of the reason each model has its own tokenizer.
That’s why we need to import the correct tokenizer for the model of our choice. Check out this well-written summary of tokenizers.
The conversion of tokens to ids through a look-up table depends on the vocabulary (the set of all unique words and tokens used) which depends on the dataset, the task, and the resulting pre-trained model. HuggingFace tokenizer automatically downloads the vocabulary used during pretraining or fine-tuning a given model. We need not create our own vocab from the dataset for fine-tuning.
We can build the tokenizer by using the tokenizer class associated with the model we would like to fine-tune on our custom dataset, or directly with the AutoTokenizer class. The AutoTokenizer.from_pretrained method takes in the name of the model to build the appropriate tokenizer.
Download and Prepare the Dataset
In this tutorial, we’re using the IMDB dataset. You can use any other dataset but the general steps here will remain the same.
-
First, you will have to download the dataset. Over 135 datasets for many NLP tasks like text classification, question answering, language modeling, etc, are provided on the HuggingFace Hub and can be viewed and explored online with the HuggingFace datasets viewer. We will look at HuggingFace datasets in another tutorial.
-
We might need to do some minor pre-processing like test-train splitting, separating text and labels, merging text, etc. In our case, the read_imdb_split function will split the text and the label.
-
We will also create a train-validation split.

-
The HuggingFace tokenizer will do the heavy lifting. We can either use AutoTokenizer which under the hood will call the correct tokenization class associated with the model name or we can directly import the tokenizer associated with the model (DistilBERT in our case). Also, note that the tokenizers are available in two flavors: a full python implementation and a “fast” implementation.
-
We will feed in the sentence (text) to the tokenizer which will return encoder text (tokens converted to ids).

-
Three key arguments are: padding, truncation and max_length. I highly recommend checking out everything you always wanted to know about padding and truncation.
-
Create TF Dataset if you are using TensorFlow backend to fine-tune the HuggingFace transformer. In the case of PyTorch create PyTorch DataLoader.

The mentioned steps might change depending on the task and the dataset but the overall methodology to prepare your dataset remains the same. You can learn more about preprocessing the data here.
HuggingFace Transformer Models
The HuggingFace Transformer models are compatible with native PyTorch and TensorFlow 2.x. Models are standard torch.nn.Module or tf.keras.Model depending on the prefix of the model class name. If it begins with TF then it’s a tf.keras.Model. Note that tokenizers are framework agnostic. Check out the summary of models available in HuggingFace Transformers.
The easiest way to download a pre-trained Transformer model is to use the appropriate AutoModel(TFAutoModelForSequenceClassification in our case). The from_pretrained is used to load a model either from a local file or directory or from a pre-trained model configuration provided by HuggingFace. You can find the list of pre-trained models here.
We will import TFDistilBertForSequenceClassification since we are fine-tuning a DistilBERT transformer. This will download the pre-trained model along with the classification head.

Suppose we need the output layer(head) to have 3 neurons, we can initialize the same by passing num_labels=3 to the model class. It will create a DistilBERT model (in our case) instance with encoder weights copied from the distilbert-base-uncased model and a randomly initialized sequence classification head on top of the encoder with an output size of 3.
We can also ask the model to return all hidden states and all attention weights if we need them:

We can change how the model itself is built, by defining custom configuration class. Each architecture comes with its own relevant configuration (in the case of DistilBERT, DistilBertConfig) which allows us to specify any of the hidden dimensions, dropout rate, etc. However, by doing so we will have to train the model from scratch. We will cover this in another tutorial.

Feature Complete Trainer / TFTrainer
You can fine-tune a HuggingFace Transformer using both native PyTorch and TensorFlow 2. HuggingFace provides a simple but feature-complete training and evaluation interface through Trainer()/TFTrainer().
We can train, fine-tune, and evaluate any HuggingFace Transformers model with a wide range of training options and with built-in features like metric logging, gradient accumulation, and mixed precision. It can be used to train with distributed strategies and even on TPU.
Training Arguments
Before instantiating Trainer/TFTrainer, we need to create a TrainingArguments/TFTrainingArguments to access all the points of customization during training.
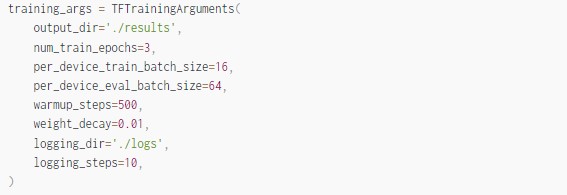
Some notable arguments are:
-
per_device_train_batch_size: The batch size per GPU/TPU core/CPU for training.
-
gradient_accumulation_steps: Number of updates steps to accumulate the gradients for, before performing a backward/update pass.
-
learning_rate: The initial learning rate for Adam.
-
weight_decay: The weight decay to apply (if not zero).
-
num_train_epochs: Total number of training epochs to perform.
-
run_name: A descriptor for the run used for Weights and Biases logging.
If you are using PyTorch DataLoader then use TrainingArguments. You can learn more about the arguments here. Note that there are some additional features that you can use with TrainingArguments like early stopping and label smoothing.
HuggingFace Trainer
HuggingFace Trainer/TFTrainer contains the basic training loop supporting the features mentioned above. This interface is easy to use and can be used to set up a decent baseline. You can always use native PyTorch or TensorFlow to build a custom training loop.

trainer.train() is used to train the model while trainer.eval() is used to evaluate the model.
If you have installed Weights & Biases then it will automatically log all the metrics to a W&B project’s dashboard.
Results
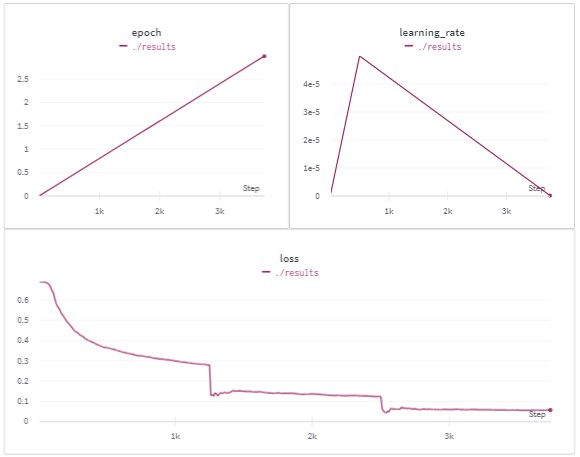
Conclusion and Resources
I hope you find this report helpful. I will encourage you to fine-tune a HuggingFace transformer on a standard or custom dataset of your choice.
This blog has been republished by AIIA. To view the original article, please click HERE.
Recent Comments