
According to the 2021 enterprise trends in machine learning report by Algorithmia, 83% of all organizations have increased their AI/ML budgets year-on-year, and the average number of data scientists employed has grown by 76% over the same period. However, the process of developing machine learning–based solutions goes far beyond model development — and you need a lot more than just the right budget and staffing resources to succeed.
For ML models to deliver good results and get better over time, they need to be trained with high-quality data. Not only that, but they must also be built and tuned in a continuous manner to keep the delivery of the insight accurate and relevant, and ensure continued performance in production. And of course, you won’t get any value from ML unless your models are actually put into production.
Many organizations are struggling to extract the full value from their ML investments for these reasons. Algorithmia’s same report revealed a number of challenges that organizations are facing throughout the ML lifecycle, especially with ML governance and integration with ML technologies. In fact, the report found that the time required to deploy a model has actually increased, due in large part to operational and tooling concerns such as these.

That’s why we’re excited to share a new integration between YData and Algorithmia. YData is the first data development platform for improved data quality. It provides tools that not only allow the understanding of the data quality and its impact on ML models but also the tools for higher quality data preparation. Algorithmia is the enterprise machine learning operations (MLOps) platform. It manages all stages of the production ML lifecycle within existing operational processes, so you can put models into production quickly, securely, and cost-effectively — unlocking the value contained in them for your business.
This blog post will explain how you can combine these two powerful machine learning platforms to not only improve the quality of your data you use to train your ML models but also to enable them to deliver useful insights in a production environment.
How YData and Algorithmia work together?
As mentioned previously, poor data quality is a major challenge preventing organizations from extracting the full value contained in their ML. It might sound simple to solve data issues such as missing data, imbalanced datasets, and the absence of labels, but those who work in data science know that good data is an endangered species in enterprise environments. Many factors can lead to training models with poor data, from scarcity of data, errors from data collection and ad-hoc manual labeling, to the lack of technical expertise from data science teams.
And while improving the quality of your training datasets is very important to ensure better outcomes and generalization from ML models, it’s just as important to ensure an easy path to model deployment. Combining YData’s platform and Algorithmia can not only increase the productivity of data science teams and improve the value delivered by ML models but also relieve the pain and bottlenecks to deploy the solutions in production environments.
YData allows for seamless integration with Algorithmia, enabling organizations to speed up their path to production for ML models built with high-quality data.
Improving data quality with YData
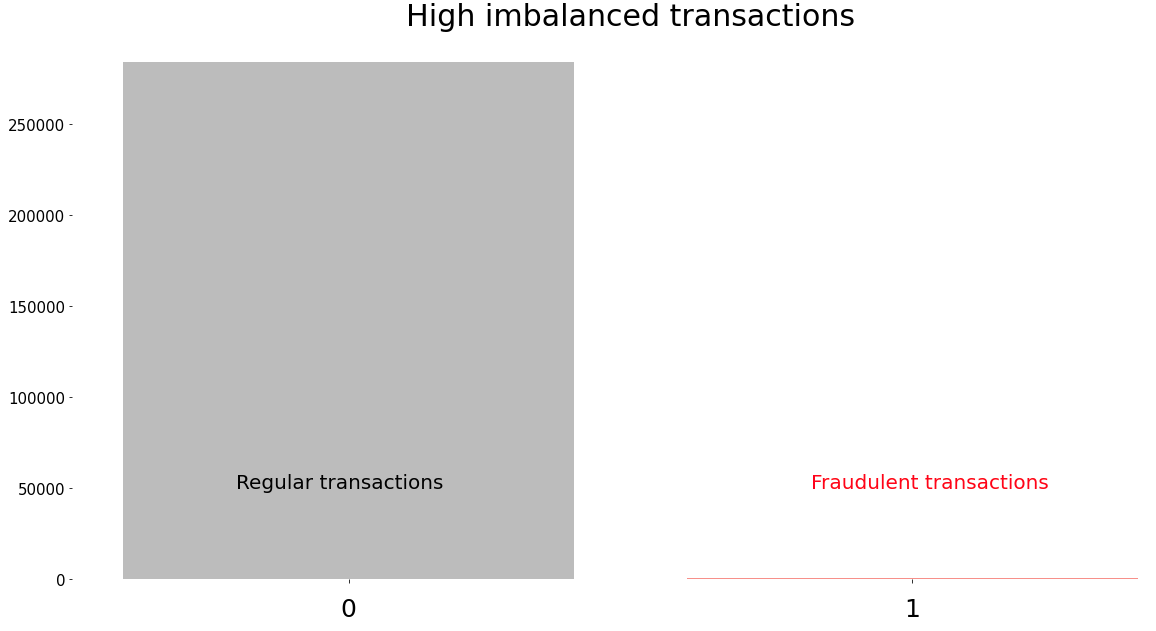
Imbalanced datasets are a reality in the industry, where the distribution of the represented classes is often biased or skewed. The problems of imbalance classification are not always straightforward to solve. However, one solution for this is balancing the classes to achieve a better overall quality of the dataset — by balancing the data through augmentation of the less represented classes.
In this demo, we’ll depict the end-to-end process of developing a classification model for highly imbalanced datasets using YData’s synthetic data generation open-source, augmenting the fraudulent events in the Kaggle Credit Card fraud dataset -, and serving the trained model on Algorithmia.
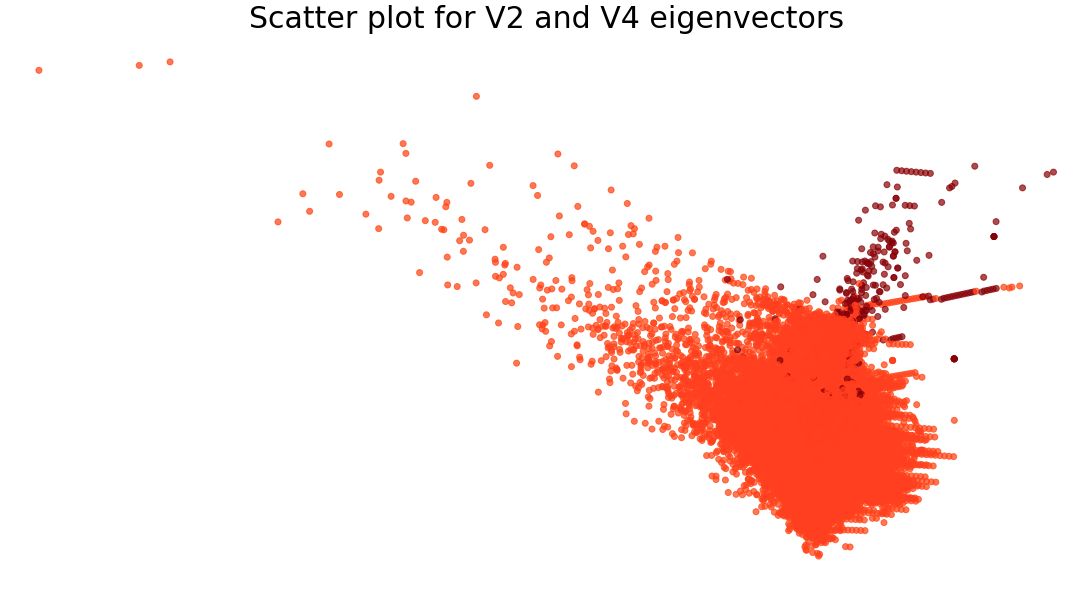
This dataset is heavily biased towards “Normal” transactions — has a very low proportion of real “Fraud” transactions to train on. This severely hampers the model’s performance, as it only gets the majority of samples from the “Normal” class in the training stage.
The XGBoost classifier model is used to train the data. XGBoost is a popular library among machine learning practitioners, known for its high performance and memory-efficient implementation of gradient boosted decision trees, with incremental improvement at each cycle.
YData’s Python SDK allows you to generate synthetic data samples that inherit similar characteristics as the original data. Here, we generate 400 new samples of “Fraud” transactions to balance the dataset, since the number of “Fraud” transactions as a percentage of total transactions is too low to achieve a good training set. These synthetic data samples are then embedded into the original training data.
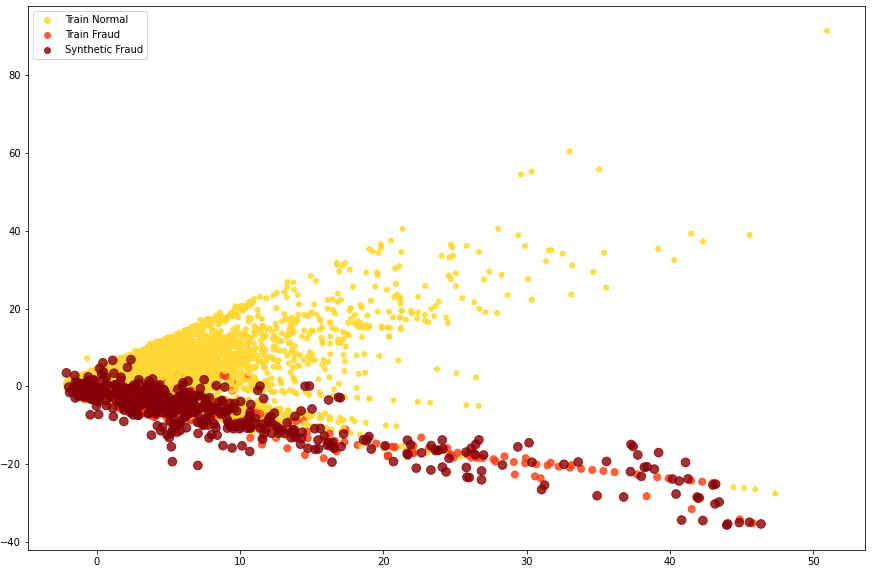
Plotting the synthetic fraud samples shows that the nature of the generated data is similar to the original fraud samples in the training set.
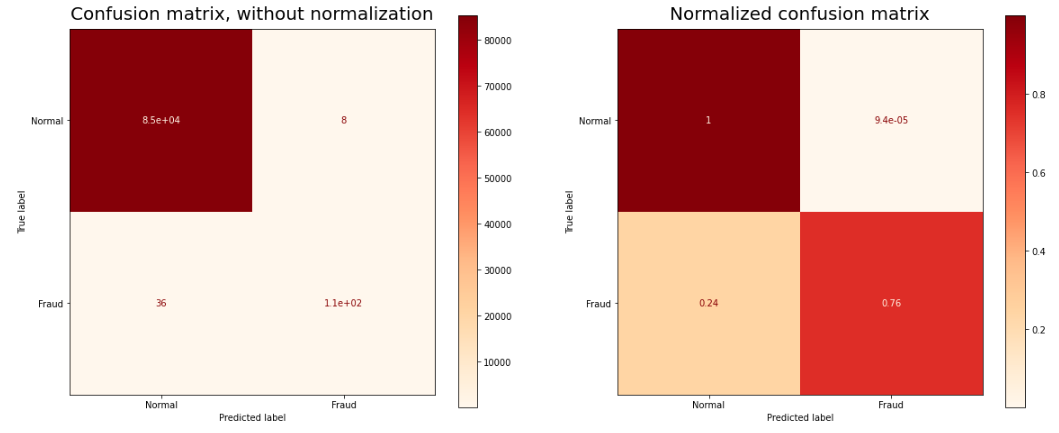
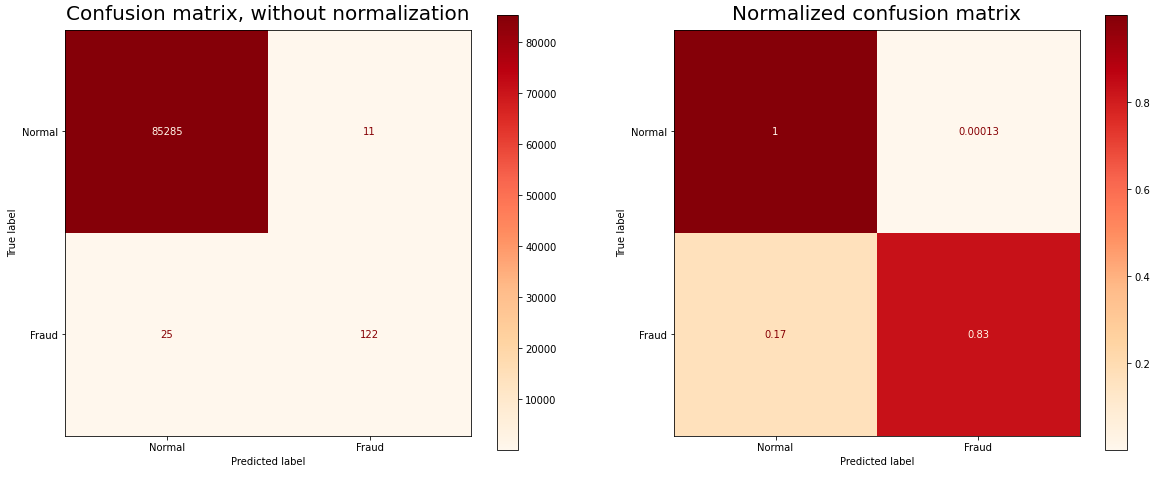
The synthetic data hugely improves the accuracy-precision metrics of the model by balancing the data bias in the original dataset by generating additional data samples of the “Fraudulent” kind, without changing the inherent nature of the data samples or giving skewed and unrealistic data points.
Note the improved model metrics after the synthetic data was added to the training set.
Serving the model on Algorithmia
Our next step is to serve our trained model on Algorithmia. We start by initializing the Algorithmia client and uploading our serialized model file to Algorithmia’s hosted data collection.
After uploading the model, we continue by creating a Python algorithm that will be built on Algorithmia’s Python 3.7 runtime environment.
After creating the algorithm, we put down our Algorithm dependencies on a requirements.txt file and our model serving code on a .py file. To push these files to our algorithm’s git repository, we can use YData Lab’s git tools or Algorithmia’s Web IDE.
Once the algorithm files are pushed to the repo, we build our algorithm and have our serving endpoint ready. We can test it with some test input and make sure our model predictions are as expected.
Get started with YData-Algorithmia integration
Many challenges prevent organizations from unlocking the full value of their ML investments. The better your AI infrastructure covers the data science lifecycle, the more time will remain for your data science teams to focus on adding valuable business value into the models. When used together, YData and Algorithmia can help you build models based on high-quality data and deploy them rapidly to production, freeing up your data scientists to focus on innovation — and achieving greater results for your business.
For a step-by-step walkthrough of this integration, you can check out the repository and implement similar workflows for yourself.
For more information on YData, check out our latest post on synthetic data for sequential data, check our open-source packages, and join our community slack.
To learn more about Algorithmia, head on over to algorithmia.com to read the latest blog posts, get a product walkthrough, or watch a demo.
This blog has been republished by AIIA. To view the original article, please click HERE.
Recent Comments