
tl;dr PipeRider is an open-source data reliability toolkit for identifying data quality issues across pipelines. PipeRider was created after months of industry research and it’s available now. Start learning more about the quality of your data by taking PipeRider for a test drive.
It’s been an interesting and fun time at InfuseAI during the latter half of 2021 and the beginning of 2022 as we’ve been working on our new open-source data reliability product, PipeRider.
For a few months we were deep in research as we interviewed many data industry professionals about the tools they use in their daily workflow, and the common issues they run into when working with data. The result of our research was a plan for a new product that would fix these issues at the source — the data source.
That’s where PipeRider comes in — our data reliability toolkit. But first, let’s rewind and look at some of the issues that were raised during our research and how these came to determine what exactly PipeRider would become.
Trust in Data
In a data-centric world, trusting your data is essential to make informed business decisions. For organizations that rely heavily on data, blindly trusting the quality of that data is a big ask. Business decisions are so reliant on quality data and, in some cases, trust so lacking, that during our research we heard about instances of data scientists manually checking data to ensure its reliability. An unsustainable situation.

‘Gut feeling’ is no way to make business decisions
When the data sources were too abundant, making manual checking impossible, sometimes decisions were made on “gut feeling”, with data sources serving only as a reference. Exactly the opposite of what should be happening in data-centric environments.
We found other situations in which BI had so much distrust in the data reports they were receiving that they sought out data engineers to ask questions face-to-face.

The main takeaway here is that a lack of robust data reliability testing leads to a distrust of data, which in turn leads to wasted time, second-guessing, and decisions led by gut-feeling. In other words — Lost revenue. In those cases when untested data was incorrectly trusted, errors were only noticed when some anomaly was discovered downstream, far too late to prevent any negative effects
Learn from your data-nightmares
We’re not recounting these data-nightmares for dramatic effect, we needed to learn from these mistakes, as the oft-used George Santayana quote says “Those who cannot remember the past are condemned to repeat it”… Maybe we should coin a new phrase? “Those who do not test their data, are condemned to data decay”. (Not as catchy? Oh well)
The research gave us insight into some essential attributes of a data reliability tool:
- It should help manage the complexity of data pipelines, providing data profiles to help you keep ahead of show-stopping data changes. The last thing you want is to be checking logs after something breaks.
- It should fit into your existing tool ecosystem, and enable you to seamlessly insert it between stages in the pipeline. Users can’t be expected to completely rework their pipelines to fit in a data quality tool.
- It should allow users to trust their data, and prove the data is trustworthy by providing useful and insightful reporting.
Riding the data pipeline
PipeRider is a data reliability tool which ensures the health of your data. It does this by profiling the data and schema and then applying data assertions to ensure that the integrity of the data is retained.
Maintain a high-profile
Hands on, the idea behind PipeRider is simple –
- Connect it to your data source at any point in your pipeline.
- Run PipeRider to generate a data profile.
- Test the profile against your data assertions.
The data profile works on both the table and column level and provides information such as the number of rows, schema structure, distribution of column data, ranges etc.

Assertions provide a way for you to define your expectations of the data, and then test your data source against these assertions. Each time you run PipeRider, your data is profiled and checked against these assertions. If any of the profiled data falls outside the bounds of your assertions then the test fails and an alert raised.
Be assertive
PipeRider comes bundled with a set of data assertions that you can implement by adding them to your data assertions file. These ready made assertions allow you to test factors of your data such as:
- Ensuring that certain column exists.
- Ensuring the uniqueness of a column.
- Ensuring the data type of a column.
- Testing for null values.
- Applying acceptable ranges to minimum and maximum values of a column.
- Monitoring for schema changes between runs.
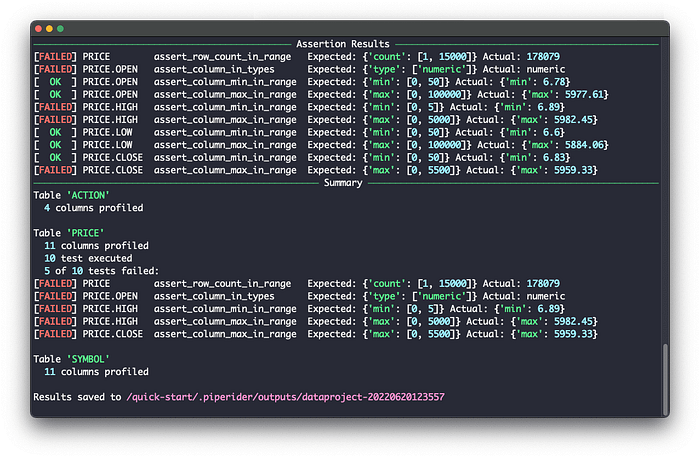
When your data source is profiled for the first time, PipeRider will output an assertion template for each table. Then you only need to apply your desired assertions to each column and the next time PipeRider runs, your data will be tested against the assertion files.
Customized assertions for your needs
In addition to the built-in assertions, PipeRider also has a plugin system that allows you to create your own custom assertions. So long as the information is contained in the PipeRider data profile, then you can test against it. All that is required is a little Python knowledge and you can create assertions to test all aspects of your data profile — a task that is well within reach of all data engineers.
Data quality reports
Running data checks on the command line isn’t for everyone, especially departments who need the visualize the data in a meaningful way. Each time PipeRider runs, it automatically creates a report on the current state of your data.
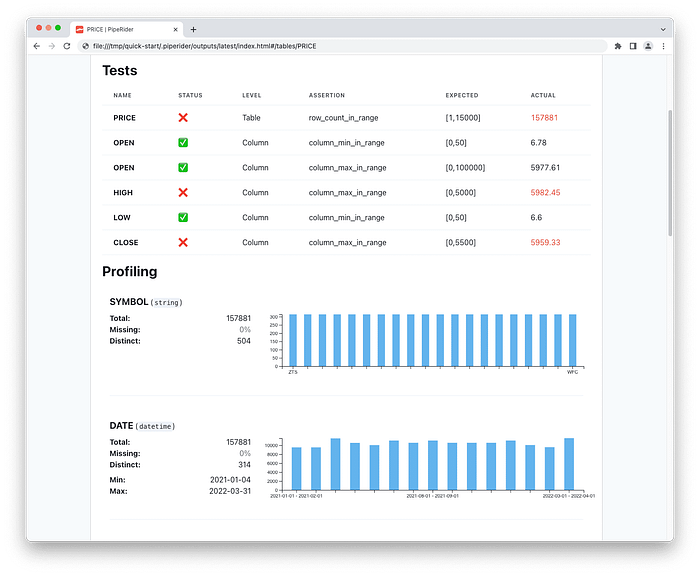
If any data assertions have failed, or the schema has changed in any way, then the report will show this information, along with the profiling information for the data source. Reports provide a convenient way to share data profiling and assertion results to users who aren’t interested in running commands in the terminal.
Comparison reports are also available to compare the results of two different PipeRider reports and see how data has changed between profiling and testing runs.
The future is automated
PipeRider has only just seen its first public release, but we’re moving fast on our roadmap to implement even more features to ensure the reliability of your data.
One feature we’re really excited about is automatically suggesting tests based on your data profile. Right now it’s up to you set decide on which assertions to use for which columns, but the new version of our profiler will intelligently analyze your data source and suggest recommended tests based on the structure of your data.
For instance, PipeRider might suggest that a certain column should be within a numerical range, the content should belong to a set of values, or automatically detect that a column should adhere to some business logic format such as email address, date, IP etc. This could really speed up the time to implement data reliability checks and even shed light on previously overlooked data .
In addition, we’ve got more data warehouse support coming, insight into data lineage, integration with dbt tests, and also enhanced notifications through popular communication platforms such as Slack.
Join us on the data reliability journey
As the developer adage goes — release early, release often. We’ve released PipeRider with what we feel is a solid base of features that we are already building on, and we want you to come with us on the journey and help us make PipeRider meet your needs.
PipeRider is an open source project, and with all our projects at InfuseAI, that means you are welcome to contribute to the project. A contribution could be anything — code if you’re a developer, a bug report or feature request if you’re a user, or simply your thoughts about the project after using it.
It’s easy to take PipeRider for a test drive, just head over to the Quick Start guide in our documentation. We’ve got a sample dataset ready for you to use, so you won’t need to connect to an existing project to try it out.
After using PipeRider we’d appreciate your feedback! Get in touch through whichever platform you prefer:
- GitHub: https://github.com/InfuseAI/piperider
- Twitter: @InfuseAI
- Discord: InfuseAI Community
This blog has been republished by AIIA. To view the original article, please click HERE.
Recent Comments