
Realtime machine learning is on the rise, and as companies start introducing realtime into their ML pipelines, they are finding themselves having to weigh the trade-offs between performance, cost, and infrastructure complexity, and determine which to prioritize.
In this post, we will look at some of the most typical trade-offs that occur at each stage of the transition from batch to realtime and why these advantages and disadvantages are important to keep in mind.
Typical Paths to Realtime Machine Learning
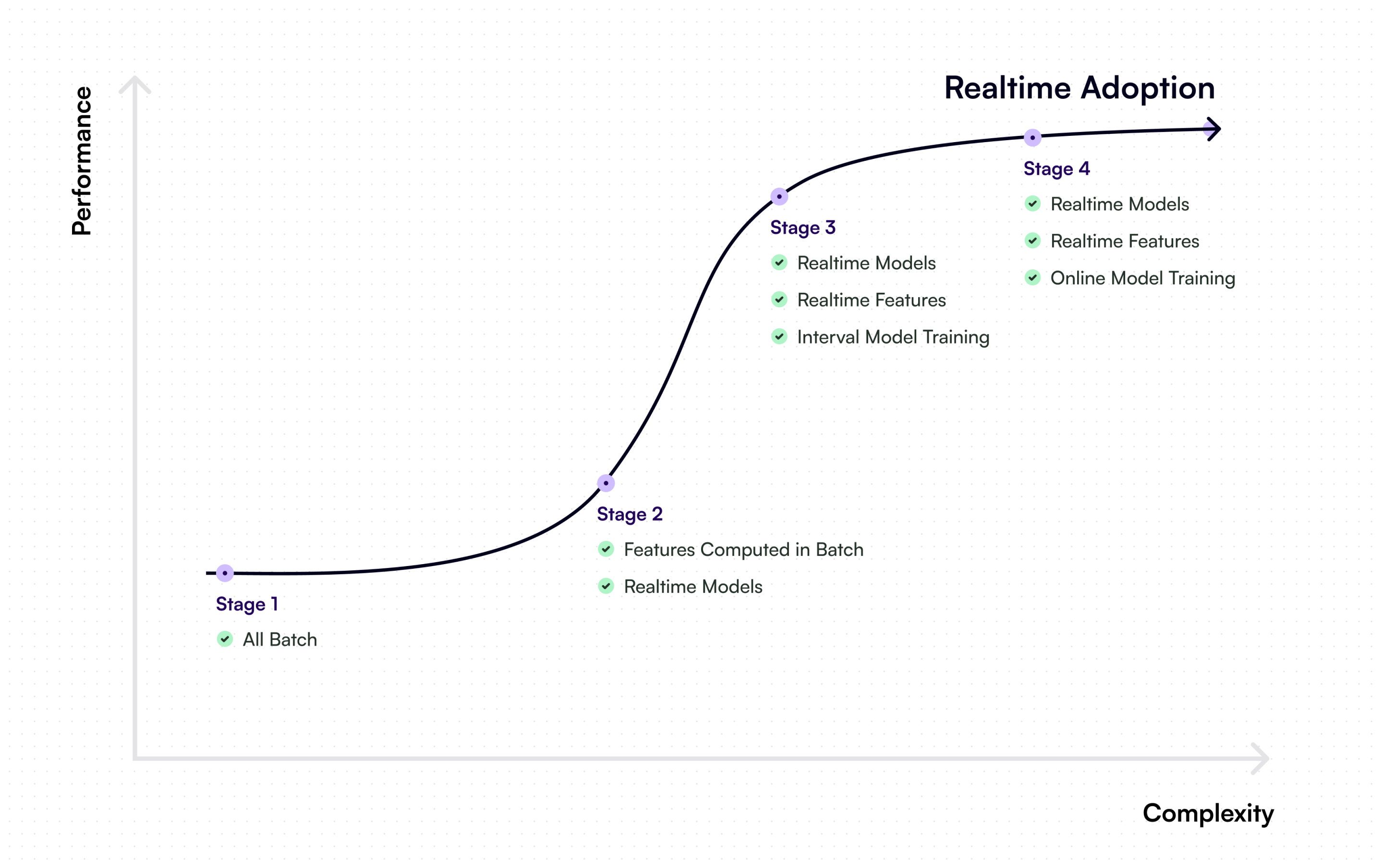
Batch processing is most useful in cases where data is infrequently changing, which is a rarity these days. It was once thought of as a less expensive method of employing machine learning, but many companies who use batch processing are starting to realize that a lot of money is wasted on computation and storage for data pertaining to users who don’t visit their site every day, so precomputed features (which they preemptively spent the money on computing, and are now spending the money to store) are not consulted. These companies are moving towards implementing realtime machine learning, despite the fact that each unit of computation is costlier for realtime, because it can often save them money by speeding up the iteration cycle and allowing them to only work with and store relevant data. This potential reduction in cost only compounds the model performance benefits companies see when working with more up-to-date data, and being able to respond more quickly to changes in markets or user preferences.
If you want to dig further into the merits of realtime ML, check out our blog post on 7 Reasons Why Realtime ML Is Here To Stay.
Stage 1: All Batch
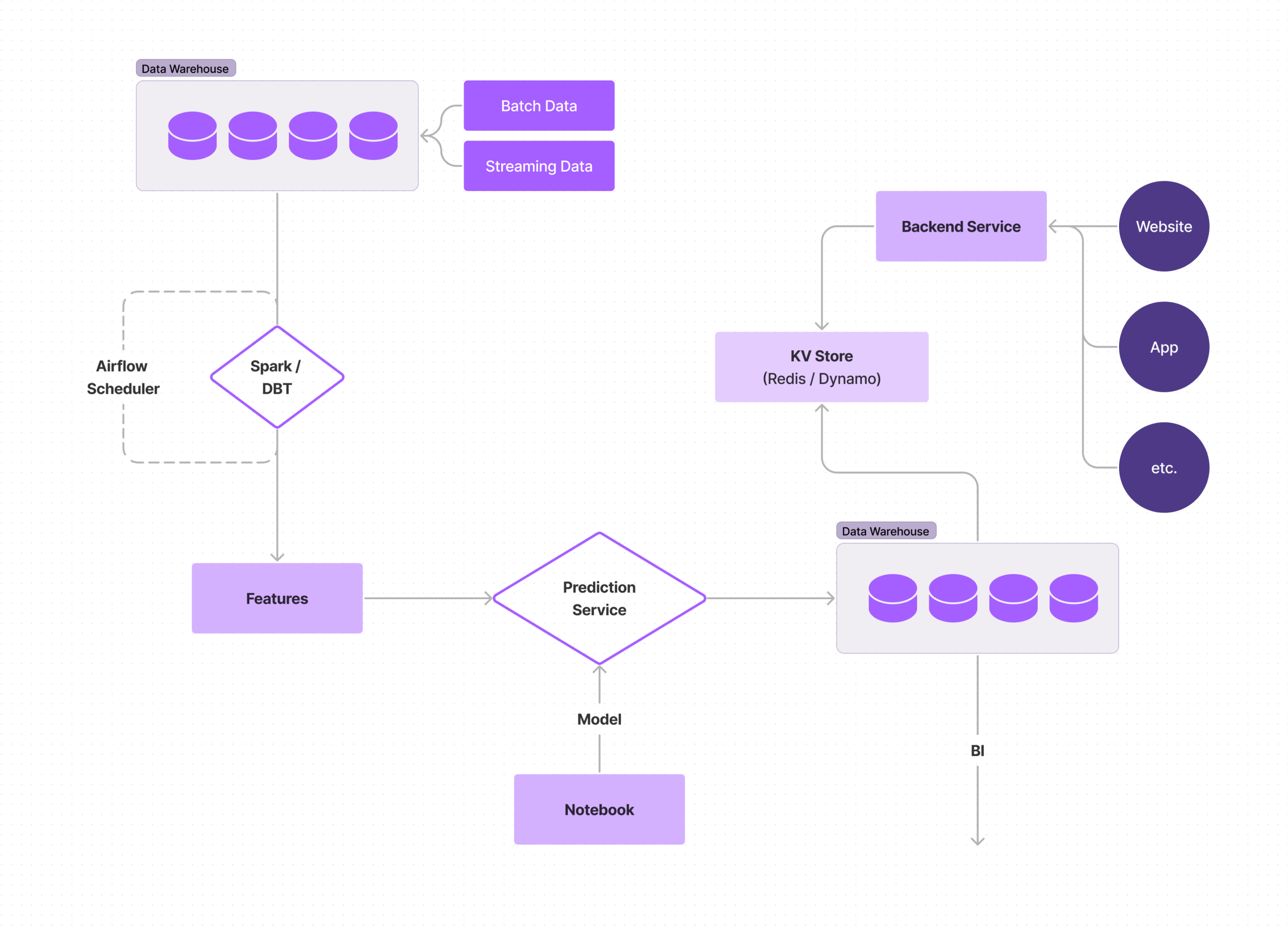
An all-batch ML pipeline is the most common approach to building an ML pipeline. In this scenario, features are computed from a batch source, such as Snowflake or S3, and model predictions are computed in advance for every user/scenario, stored, and served when needed. In some cases, model predictions are not even served online (e.g. via Redis); in these cases, a batch job reads all the model scores and performs an action or computation (e.g. if the model is predicting if the user will churn or not, a pipeline reads these scores and decides to send an email to them, and all of this is happening offline).
The biggest advantage of a batch ML pipeline is that it is relatively easy to set up and does not require real-time data. However, the downside is that batch pipelines can be slow and inefficient, making them less suitable for large-scale or time-sensitive data.
Challenges
One of the biggest challenges with an all batch ML pipeline is stale predictions and developing a process for fixing them, or any other issues. Because data is stored in a static place, you need to fetch and process the data before training. This process becomes tedious, as any time you need to make an update, no matter how small, you need to go through the entire process of fetching, processing, and training again. In most cases, this means that many companies that employ batch processes don’t train their models frequently enough for them to be truly useful (since they aren’t up-to-date).
Another reason you run into stale predictions with batch processes is that they require enormous datasets to hold all of the data, since you are computing for all users (or even just all active users), and there isn’t any personalization. This can work in some select, simple cases, but isn’t useful for most cases in our current fast-paced, highly-dynamic world. Furthermore, the lack of flexibility and speed in altering your data makes it challenging to personalize for any new users; first impressions are incredibly important for creating repeat users and reducing churn, so this inability to properly personalize for new users can have a significant business impact.
The aforementioned challenges also result in significantly delayed experimentation velocity. For the first three stages most companies go through, models are trained in intervals, but those intervals are, comparatively, much longer with batch processes because you are working with static data and models, so it is incredibly time-intensive to determine if your model is improving or drifting each time you feed it new data.
Stage 2: Features Computed in Batch, with Realtime Models
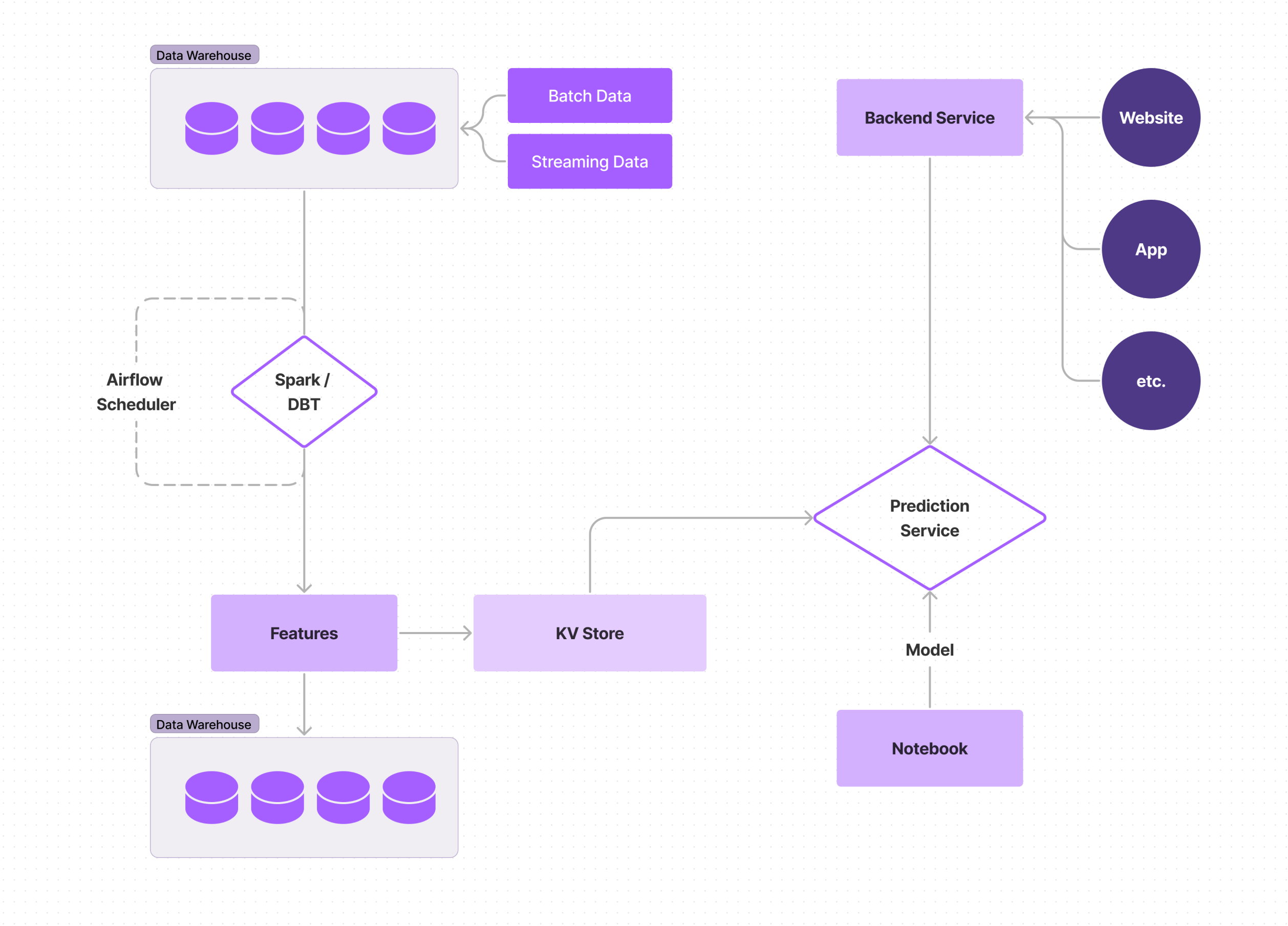
As companies begin to integrate realtime into their ML pipeline, they generally start by continuing to work with batched features, but have the model use the batch-computed features in real time; the model is serving in realtime, but the computed features are in a key-value store. With this implementation, you get the familiar ease and simplicity of static data, but start to see some of the accuracy and performance benefits of more up-to-date models and predictions.
Challenges
With features being computed in batch, you still have to make sure you aren’t working with stale features and need to train models at intervals, but these intervals can be shorter than with all batch processes because your feedback loop is shorter. With that being said, you now have to be mindful of your model serving, because that is the only serving part, so it has to be reliable and have good SLAs around it.
You also don’t quite reap the benefits of realtime without a good bit of added work, since your features are still static; it can take a lot of work to be able to use application context, even though your models are being served in realtime. Since there are many moving pieces, with your model being realtime, data validation and monitoring need to be put into place to help catch data quality issues and model drift before it starts impacting business metrics. This means logging needs to be put in place, and engineers need to be put on call.
With any element of your ML pipeline being batch computed, you also are unable to solve for some of the most important use cases for modern sites and apps. For example, on social sites, news apps, and most platforms that are trying to grab and hold users’ attention, personalized content and feeds are expected (even subconsciously), and batch computed features simply don’t allow for fast enough iterations to deliver this user experience. Fraud detection is also imperative for the majority of business use cases, but this requires nearly immediate recognition of and action against bad actors, which is also not feasible when features are batch computed.
Stage 3: Realtime Model and Features, Interval Model Training
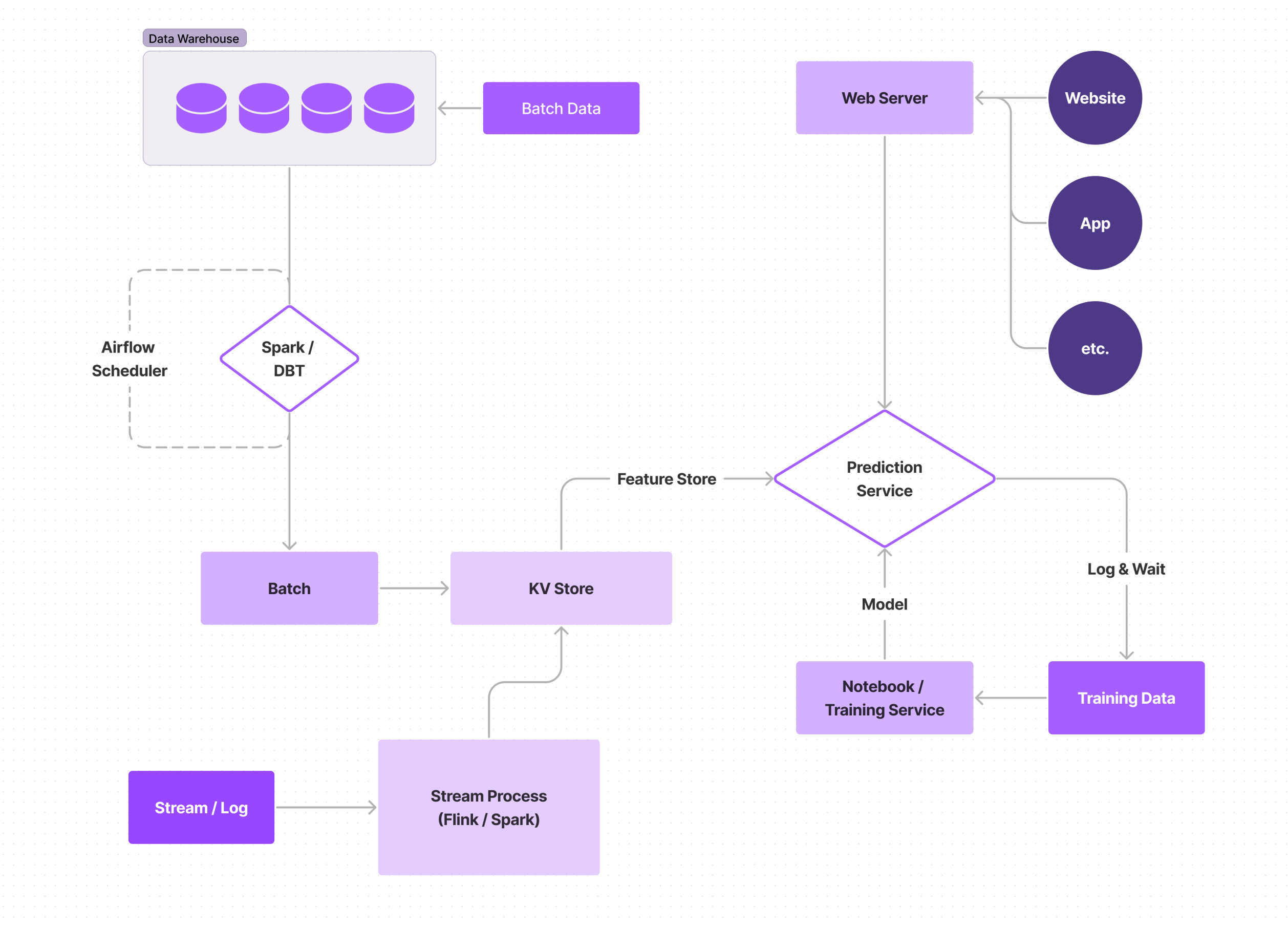
Features are real-time, and the model is realtime and trained at intervals. The fact that the model is using features as they are updated in realtime eliminates the majority of the staleness issues that the previous stages had. This implementation is where you really start to be able to dig into use cases like fraud detection, where you need to be able to instantaneously detect and act on deviations from the behavior or trends the model predicts.
Challenges
As more parts of your system become realtime, more moving pieces are introduced, and that added complexity makes your pipelines harder to maintain. Keeping a good SLA can be difficult if you are building things from scratch, and the teams responsible for the different elements have to learn to coordinate their efforts. Data engineers who are responsible for writing ML pipelines and managing features need to coordinate with ML engineers who are responsible for putting the model into production, and those models need to be trained by Data Scientists, and all of these people need to be in sync; at first, this coordination need can decrease team velocity.
Monitoring becomes even more important at this stage, since your data is changing much more quickly. Models will still eventually degrade, so it is important that you have solid drift detection mechanisms in place and the ability to train new models when drift is detected.
More rapid changes in data also mean you need to be aware of skews in training data vs. data at serving time; the features you used to train your model will look slightly different than the features you use when making predictions. You can use a log-and-wait approach, but that can make it harder to experiment with new features, as it is time-consuming and decreases your velocity. A more accurate method is to use point-in-time backfills, but that can quickly become complex.
Yet another issue with realtime feature computation is handling bad or out-of order data. When working with realtime features, methods need to be put into place to handle data that may come in non-chronologically, due to factors like the user’s device buffering the data it sends back to you when they’ve got a poor connection; the order of users’ actions is often just as important as the actions themselves when predicting behaviors and building tools that feel intuitive to users, and when tools feel intuitive, users will continue using (and recommending) them. Models being trained on realtime features can also become inaccurate if your data becomes corrupted; this can be a result of some bad datapoints, or something like a change in the units being used for a feature not being properly communicated to the ML engineers. To combat this, it is ideal to put in data correctness checks for each data point that enters your system.
The final big challenge with more aspects being realtime is that it becomes harder to predict what models will perform best in practice; a newly trained model might look great on paper but might perform poorly in production. This is where canary models come into play; when deploying a new model, you can apply it to a small percentage of requests initially, to ensure that it is functioning the way you expect. Yet again, however, this adds complexity to your system.
Stage 4: Realtime Features and Model, Online Model Training
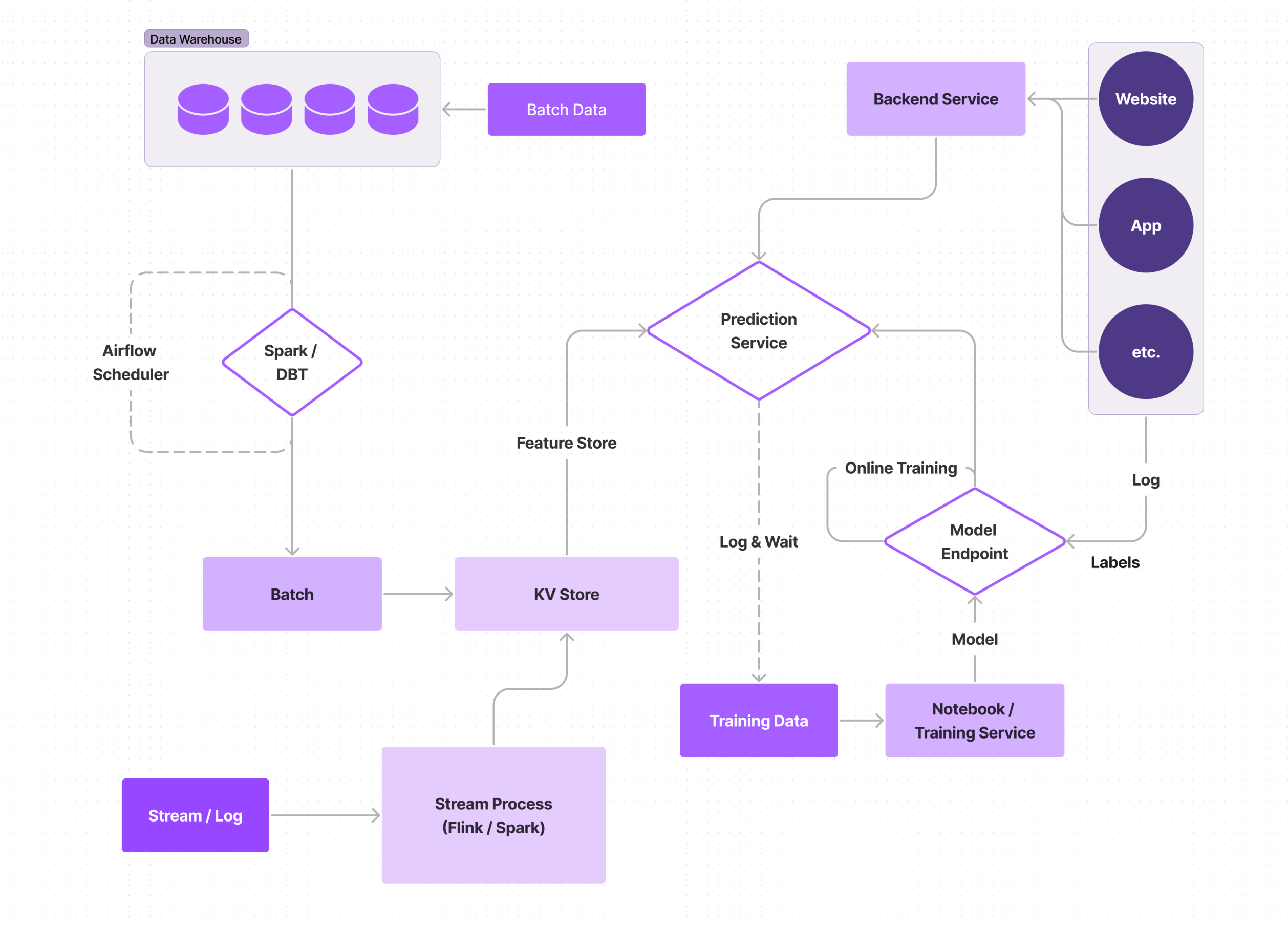
By far, the most expensive, complex, and performant method is a fully realtime ML pipeline; the model runs in realtime, the features run in realtime, and the model is trained online, so it is constantly learning. Because the time, money, and resources required by a fully realtime system are so extensive, this method is infrequently utilized, even by FAANG-type companies, but we highlight it here because it is also incredible what this type of realtime implementation is capable of.
Fully realtime systems are most commonly employed for use cases such as ad prediction, where the model predicts the likelihood of user engagement with an ad; when ads are your business model, every cent counts, and fully realtime ML pipelines can ensure resources are being allocated efficiently.
Challenges
Online model training heavily relies on “snapshots” of your model for checks and balances, and the ability to respond to corrupted data (basically a versioning system for your model). Model snapshots can easily go bad with just a few bad training data points, causing the model to behave erratically, so this is yet another part of the cycle where you need to employ excellent monitoring, as well as an on-call setup, in order to quickly catch and revert bad snapshots, and know which snapshot to revert to.
Additionally, with this type of system, many of the drawbacks mentioned in the previous stage are amplified, as things are moving exponentially more quickly. Teams have to be more efficient and communicative; more and better checkpoints need to be added for data quality, drift, and training skew; model experimentation becomes trickier; there are more factors to worry about ensuring low latency for. For most companies, the costs of maintaining this type of system outweigh the benefits it provides; if you even need to question whether you need online model training, you probably don’t.
Final Thoughts
In this post, we reviewed the benefits and drawbacks of different realtime ML pipelines. While there seem to be a good number of drawbacks to any method, the most important thing is to be aware of what these are, so that you can be prepared for and mitigate them before they happen, rather than scrambling to play whack-a-mole if you were to go in blind. Mitigating these challenges is something you can decide to do in-house, but there are also many tools that can help address subsets of the complexities involved with each method, and there are even some, like Fennel, that can address most, if not all, of them.
While the ideal method for your use case will depend on how quickly the data your models depend on tend to change, many companies are moving towards implementing more realtime aspects to their ML pipelines, due to the performance benefits that accompany this strategy. With the help of third-party tools, it can be relatively easy to implement a highly performant realtime ML pipeline, with realtime features and a realtime model, like that of Stage 3, and reap the benefits of a fully end-to-end realtime ML pipeline, without much of the infrastructure complexity that usually accompanies realtime ML pipelines.
This blog has been republished by AIIA. To view the original article, please click HERE.
Recent Comments