
Achieving high AI Quality requires the right combination of people, processes, and tools.
In the post, “What is AI Quality?” we defined what AI Quality is and how it is key to solving critical challenges facing AI today. That is, AI Quality is the set of observable attributes of an AI system that allows you to assess, over time, the system’s real world success. It is evaluated across four key categories: model performance, societal impact, operational compatibility, and data quality. Explainability is a key enabling technology.
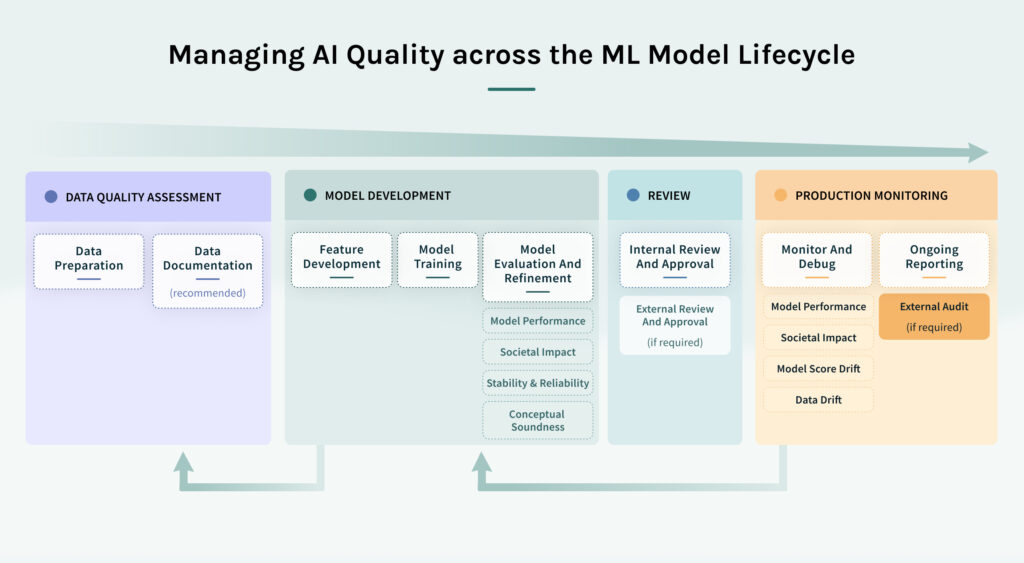
Achieving consistently high AI quality across a broad range of models requires a thoughtful combination of people, processes, and technology. All three components need to work together in an ongoing, iterative lifecycle in order for machine learning applications to drive desired results. In this multi-part blog series, we will cover the processes and technology part of the combination, with a particular focus on steps in the process where high-impact failures are widespread: evaluating models and data, getting stakeholder approval, and monitoring models. We will also discuss how you can overcome these typical breakdown points by augmenting your processes and leveraging emerging tools.
Part 1 of the blog series covers the overview of the process flow, data quality assessment, feature development, and model training.
The core processes for managing AI Quality
Managing AI Quality effectively requires reviewing and refining the four key areas of AI Quality – model performance, societal impact, operational compatibility, and data quality – throughout the lifecycle of a model project. This analysis and optimization of the model starts early during model development and continues even after the model has been pushed into live production, since it includes steps for monitoring and updating deployed models.
Initiate a ML Project
The process begins with project initiation. Project initiation is most effective when it involves both the business owner and the technical execution team. The business owner is required to ensure that the business or organizational objective of the project is well understood, which increases the likelihood of project approval and success. The project execution team generally consists of the data scientists and ML engineers who will develop the model. It may also include data engineers, if there are separate data owners who need to approve of data usage and ensure data readiness. At this early point, any other teams that will be involved later in the process, such as the review stage or the monitoring stage, are apprised of the project goals and timing.
Assess Data Quality
Reviewing and ensuring data quality is critical during model development and on an ongoing basis for production models.
Data preparation
The goal of data preparation is to ensure that the data is ready and fit for use in the project. Processes and tools that cover some areas of data quality are quite mature, in particular, for data preparation. These tools can, among other things, help with identifying anomalies, imbalances, and patterns in datasets and support review and quality improvements before models are built.
Data documentation
Going beyond standard data preparation, there is increasing recognition that datasets used for machine learning can benefit from datasheets that document the data attributes for the benefit of dataset creators and consumers. Data documentation is a gap in the process at many organizations. Since data is foundational to ML success, we encourage data scientists and their managers to assess their data documentation requirements and take steps to ensure that documentation is in place.
Key aspects to document include the motivation for creating the dataset, its composition, the collection process, any preprocessing/cleaning/labeling operations applied to the dataset, its uses, distribution, and maintenance. An example datasheet for a dataset for sentiment analysis – a Natural Language Processing (NLP) task – illustrates this methodology. Embedding this kind of methodology into the standard processes of data quality assessment is still in its infancy, and it will be increasingly important as expectations around describing AI models and data increase due to requirements from internal peers and stakeholders, as well as pressures from customers, the general public, and possibly regulators.
Develop Features
Developing features is a standard step in the ML model development workflow. Historically, it has been a laborious process that draws on significant domain expertise and experimentation. More recently, there have been major advances in automated feature engineering and selection tools.
To ensure high AI Quality, it is critical to supplement these efforts to ensure that humans remain in control of this step. This requires AI Quality and Explainability tools that surface features learned by models automatically, in a form by which data scientists and domain experts can assess whether they are appropriate or conceptually sound for the task at hand.
Examples of feature assessments include:
- surfacing visual concepts learnt by deep learning models for medical diagnostics or facial recognition
- linguistic concepts learnt by a sentiment analysis or document processing model
- how features are being combined by a tree model to make credit or fraud decisions
- how model outputs depend on groups of features.
There are also opportunities to extract interpretable features from complex models (e.g., capturing feature interactions and time-series behavior) to add to simpler models. The feature analysis stage also represents an important opportunity to assess the fairness of the model, since data proxies for gender, race, and other characteristics may creep into models even when they are not relevant to the achievement of model objectives. Since fairness is an area which attracts both regulatory and public scrutiny, it is a key step to include.

Train Models
The process of training a model involves providing an algorithm with the data from which it learns.. A primary focus of training is optimizing the accuracy of models, as measured by AUC, GINI, and other standard performance metrics. While accuracy is a key consideration for AI Quality, it is also important to pay attention to other AI Quality attributes, such as robustness, fairness, and privacy. This may require adjustments to the model training process, e.g., through data augmentation, adding constraints, or updating the objective function during training. While the act of model training has gotten more straightforward due to the availability of a number of ML platforms, the actual evaluation and assessment of model performance generally requires a supplementary AI Quality solution to address.
Part II of this series will cover the next three steps in the AI Quality management process: evaluate and refine models, select model, and review and approve model.
This blog has been republished by AIIA. To view the original article, please click HERE.
Recent Comments