In this article, founder and CEO of Galileo Vikram Chatterji discusses the problems with ML data blindspots and introduces ML Data Intelligence that helps an ML team holistically understand and improve the health of the data powering ML across the organization.
As a former product leader at Google AI, my team and I were responsible for building models that would ‘just work’. They needed to ‘just work’ because we were selling to some highly regulated industries like financial services and healthcare, where the price to pay for poor or biased predictions is very steep.
Over and over again, we would think our model ‘worked’ due to high values on vanity metrics such as F1 or confidence scores, but within days we would realize issues with our data – it didn’t matter what other shiny tools we used for training, deploying or monitoring models – if the data was erroneous, the model would suffer, and the data can be ‘erroneous’ in dozens of ways, which made this a hard problem.
Turned out that this problem was not unique to Google – over the past year, we realized after speaking with 100s of ML leaders, that analyzing and fixing the data across the ML workflow, or continuous ML Data Intelligence is their top problem.
What tools did we use at Google, and these 100s of ML teams use for ML data intelligence?

Sheets and scripts are still state-of-the-art! This has many problems.
-
‘Known issues’ bias – when we drive analysis in these tools, we go after the problems we think exist. We’re going after the ‘known unknowns’. This mindset leads to missing out on the vast majority of ‘unknown unknowns’ (cohorts of business-critical data slices that perform poorly, data in languages that you didn’t know were lurking around, PII data that slipped into training data but shouldn’t be there, and a lot more) that surface quickly in production and lead to customer churn.
-
Ad-hoc techniques and data silos: Scripts in notebooks are great for quickly inspecting the data, but it’s a bunch of code that needs to be written over and over and over again each time a data scientist gets into ‘data detective’ mode. These scripts are sometimes based on wonderful data-centric AI research (which is in its infancy and we’re excited about the field!), but it is hard to share with others on the team. This leads to an ad-hoc bag of tricks that data scientists leverage, with limited collaboration on the data insights found.
-
Slow to deliver ROI: Google Docs truly changed how people could collaborate while writing. Getting a piece of written content out the door, after all, is a collaborative sport. It’s the same with ML data intelligence! Getting a model out the door depends on collaborative data inspection and fixing across the ML workflow. Doing this in sheets and scripts is a lot like using paper instead of Google docs!
What is ML data intelligence? The 5 Principles.
ML data intelligence is a team’s ability to holistically understand and improve the health of the data powering ML across the organization. This removes data biases and production mishaps proactively thereby resulting in 100s of hours saved for data scientists, lowering costs dramatically and improving model predictions quickly, sometimes in the order of 10-12% or more.
ML data intelligence tools are embedded in the model training and production environments to quickly identify data errors leveraging data-centric AI techniques baked in, and systematically enable data fixing with actionability and collaboration as key cornerstones.
ML data intelligence is one of the first tools that companies need when embarking on the ML journey, even before labeling or figuring out which model to use – getting an understanding of the data health first and fixing/improving it sets a good foundation for smarter data sampling for annotation (thereby saving on labeling costs).
The five pillars of ML data intelligence are:
-
Inspection – shining a light on the data powering your models is one part of inspection. The other is enabling you to short-circuit the needle-in-the-haystack process of finding the long tail of erroneous data quickly.
-
Actionability – finding errors is meaningless without appropriate action. Removing data samples, editing/cleaning the data, sending them to labelers or subject matter experts, exporting to S3 – actions should be built-in and one-click away.
-
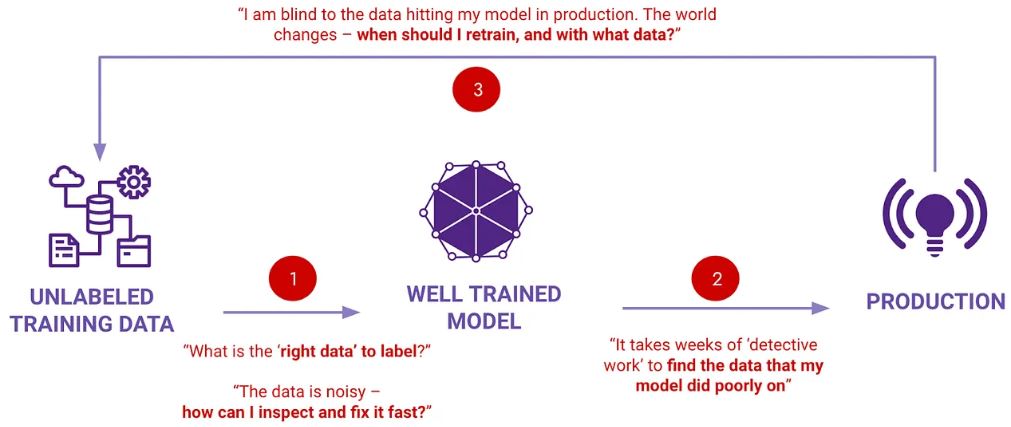
Continuity – there is a ML data flywheel across the workflow (as illustrated in the diagram). ML data intelligence is therefore not a point-in-time activity but a continuous process of data health upkeep.
-
Collaboration – building, deploying and maintaining models takes a village. To avoid data silos being created, there needs to be complete data transparency/shareability around data errors identified and the effect of the action upon them.
-
Scalability – models often can require hundreds, thousands or millions of samples of data to train well. ML data intelligence should scale to these high volumes while maintaining low latencies and a great user experience.
ML data intelligence vs Data Quality
The quality of the data relies on being able to identify noise/errors fast – this could be within the data dump you get from a customer, or from the data the model is getting hit within production. ‘Data quality’ is abstract but critical. It needs constant supervision, analysis and adaptation of the data to ensure it is up and to the right.
Data quality is a byproduct of ML data intelligence, which provides a framework to inspect, analyze and fix the data to ensure high data quality across the ML workflow.
ML data intelligence vs ML Monitoring
When we think of ‘ML monitoring’ there is a bias that conjures tools such as Datadog where incredible dashboards are constantly monitoring and alerting ML teams of model downtimes in production. This has two problems:
-
Model-centricity ignores the data problem: Every ML task has two sides to it. The model itself and the data it is fed. Most monitoring tools focus on the model metrics while providing high-level data-specific monitoring (drift over time, null values, etc). These tools do not enable deep investigation and fixing of the data.
-
Focus on post-production only: ML monitoring is primarily dedicated to models in production. As mentioned in the principles above, ML data intelligence tools should provide data health monitoring across the ML workflow – this does not have to be real-time but does need to enable data science practitioners to create automated data health tests and tweak them over time.
Moreover, while ML monitoring tools focus on the ML Engineer/Program Manager, ML data intelligence tools focus squarely on the data scientist as an assistant for continuous data analysis and fixing.
The future of ML data intelligence
ML data intelligence is a rapidly maturing but still evolving space.
Most job functions over time, as they grow in prominence within an organization, become more data-driven in their decision-making. This has always required a new set of tools to step up and enable the shift.
-
In the early 2000s, sales teams and executives shifted from intuition-driven decision-making to tools such as Tableau for quick data visualization, analysis and sense-making.
-
In the past decade, product orgs started to grow, leading to product managers shifting from intuition-based decisions to using tools such as Amplitude to quantify user behavior.
Similarly, ML teams have become a mainstay for organizations, and now deserve the tools to quickly inspect, fix and track the data they are working with.
This ‘data stack’ in the ML developers toolkit will be powered by innovations in data-centric AI research (academia has a growing focus here), as well as a growing understanding that fixing the data can lead to huge gains in model performance – but to ‘fix’, you need to first ‘understand’ – ML data intelligence will enable both for the data scientist, ushering in the data-driven ML mindset.
To learn more, reach out to me, Vikram Chatterji. I will be happy to discuss how we solve the challenges of ML data Intelligence with Galileo.

Recent Comments