
Data leakage isn’t new. We’ve heard all about it. And, yes, it’s inevitable. But that’s exactly why we can’t afford to ignore it. If data leakage isn’t prevented early on it ends up spilling over into production, where it’s not quite so easy to fix.
Data leakage in machine learning is what we call it when you accidentally gave your machine learning model the answers instead of it learning how to predict on its own. It can happen to anyone, whether because incorrect data was fed to the algorithm during training or the prediction was included in your data by mistake. Either way, if your model gets hold of data it wasn’t supposed to see during training, it can become overly optimistic, invalid, or unreliable–and will output bad predictions.
The reality is that almost every data scientist is at risk of data leakage at some point. We all know the obvious common leakages like including the label as one of the features or leaving the test set as part of the train set, but actually, there are many types of data leakage patterns. It may happen when you clean your data, remove outliers, separate off the test data, or during just about any other data processing. The bottom line is that when there’s data leakage, you don’t know how good the model is, and you can’t trust it to be accurate. Needless to say, if left unchecked, data leakage is much harder to fix once your model goes to production.
How to detect data leakage
Many types of data leakage are subtle, but you can ferret them out early with a few proactive strategies.
1. Check whether your results are too good to be true
If you’re seeing results that are 100% accurate, there’s clearly something wrong. But to understand what levels of accuracy should raise a data leakage flag, try to get some sort of benchmark. This might be your current performance or performance based on a very basic modeling process where you’re less likely to make mistakes. Use that baseline to see if your model’s results are in the same ballpark; they should be better but not on a different scale.

If it looks too good to be true it’s probably data leakage
2. See if a single feature stands out as significantly more important than others
It’s always worth running an analysis for feature importance or correlation to understand how different features influence the decision-making process. This analysis is also a good way to capture suspicious leaks. Say your model needs to predict who should receive approval for a loan from the bank. If your analysis shows a single feature–like age–that is being used to formulate 80% of the decision, and all the other features like profession, sex, income, family status, and history make up 20%, it’s time to go back and check for leakage. Feature attribution analysis is also very effective in capturing label leakage or label proxy elements, where the predicted value was part of the features used to build the model.
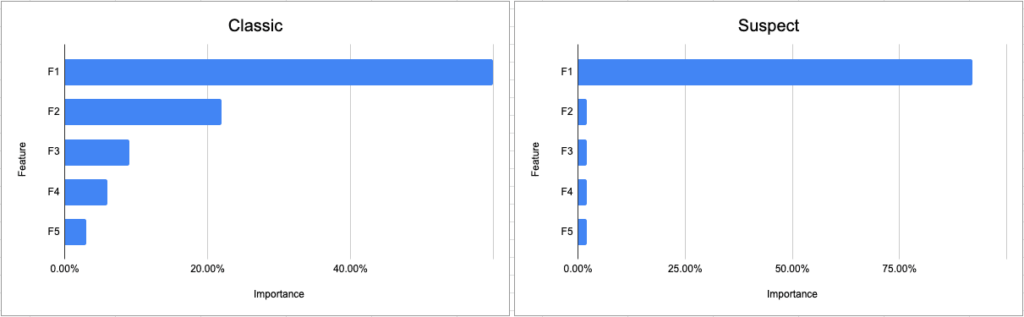
Classic vs suspect feature importance
3. Get a visual to confirm the intuition behind the decision-making
If you’re using a white box algorithm that’s understandable and transparent, try to get a visualization to see how the predictions are being made. For example, if the model uses a decision tree, glance over the pattern to see if it’s odd-looking, counterintuitive, or overloaded in one area as opposed to the others. But not all models are white box and can be followed. For your black-box models, you can use explainability methods like SHAP or LIME. These tools will run sensitivity analysis on your algorithms to explain the output and pinpoint any features that are dominating the prediction. If the predictions seem to be working but are based on things that shouldn’t carry so much weight, take another look and think about running it by a domain expert.
4. Have other practitioners do a peer code review
Having colleagues review your code is standard for software engineering but somehow isn’t a must for data science. Everyone tends to have bugs in their code, so why not in their models? Don’t be shy: organize a data science design review to go over the approach and modeling process, simulate how the algorithm runs, and catch unwanted bugs that might lead to leakage.
5. Vet that the held-out data was separated before data manipulation
When you split a dataset into testing and training, it’s vital that no data is shared between these two sets. After all, the whole idea of the test set is to simulate real-world data that the model has never seen. If you get started with data manipulations and transformations before you separate the held-out data off, there’s a good chance your data will leak. What’s more, if you find out that the hold-out data wasn’t separated at the outset, you should seriously consider starting over. Either way, check the process to see when the data was held out.
Recognizing data leakage in production versus training
These strategies come into play while you’re training your model. Unfortunately, data leakage is still common and tends to ‘somehow’ slide over into production. This fact underlines the importance of a monitoring platform that can detect underperforming models or distribution skew as soon as the model begins working in production.
This blog has been republished by AIIA. To view the original article, please click HERE.
Recent Comments