
Just a few years ago, almost nobody was building software to support the surge of new machine learning apps coming into production all over the world. Every cutting-edge tech company, like Google, Lyft, Microsoft, and Amazon rolled their own AI/ML tech stack from scratch.
Fast forward to today and we’ve got a Cambrian explosion of new companies building a massive array of software to democratize AI for the rest of us.
We created the AI Infrastructure Alliance to bring all those companies together. Call us “AIIA” for short, pronounced Ai-Ya, like Eva in Wall-E. We’re bringing them together because we need engineering teams working as one, not trying to solve everything in their own tiny little silos.Enterprises and smaller companies aren’t going to build their own stacks from the ground up.
The biggest companies might try but they’ll soon end up ripping and replacing half of it as commercial software matures. The big tech companies have the might and muscle to invest 500 million to roll their own software and the engineers to do it, with money left over to hire the top data scientists and researchers on the planet.
But for AI apps to become as ubiquitous as the apps on your phone, you need a canonical stack for machine learning that makes it easier for non-tech companies to level up fast.
We need an AI/ML infrastructure stack for the rest of us. Think LAMP stack for AI/ML.
Picture the AIIA as a garden where the stack of tomorrow can grow. Plant a lot of seeds and see what comes up. Nurture what comes up and clear what doesn’t grow tall and strong.
There’s more than 50 companies and communities in the AIIA and almost a billion dollars backing the startups in it. We’re growing every month. We’re projecting to have 200 in the next few years. We’re building a big tent to bring in the entire industry.
But nobody will hit a button and deploy a 50 or 200 product solution stack. We’re not trying to build one stack to rule them all. Think multiple competing stacks.
We believe in the “bazaar” approach as in the cathedral versus the bazaar. Everyone starts off equal but soon the spice stall and the scarf stall and the hat stall form a coalition and start offering 20% off each other’s goods. Soon there are bigger and bigger sections of the bazaar as people figure out how to work together better and better.
Other communities have failed by taking the cathedral approach. They start top down and try to dictate a single standard that works for everyone and pretty soon it doesn’t work for anyone and by the time it comes out, it’s too little too late. Creativity doesn’t come from committee. It comes from a lot of friendly co-opetition.
Making Sense of It All
Beyond the canonical stack, we’re also working to help folks make sense of what all those companies are doing.
Recently Sam Charrington and the folks at TWIML put out a guide covering the ML landscape and a lot of the AIIA companies made the list.
Why do we even need to do that though?
Because there are so many companies now that it’s hard to get a handle on what they do.
That’s why we see people do a three part post on the MLOps space just trying to figure out what the heck everyone’s software does in the first place! The post has some strong, clear thinking, but it still gets a lot of what the individual companies do wrong. That’s no surprise because there are a lot of them and it’s not easy to go deep on each and every one.
I’ve talked at length with the CEOs and CTOs of countless companies about what they do and I still get it jumbled up from time to time. It’s hard to keep everything straight even when you’re looking at the landscape day in and day out.
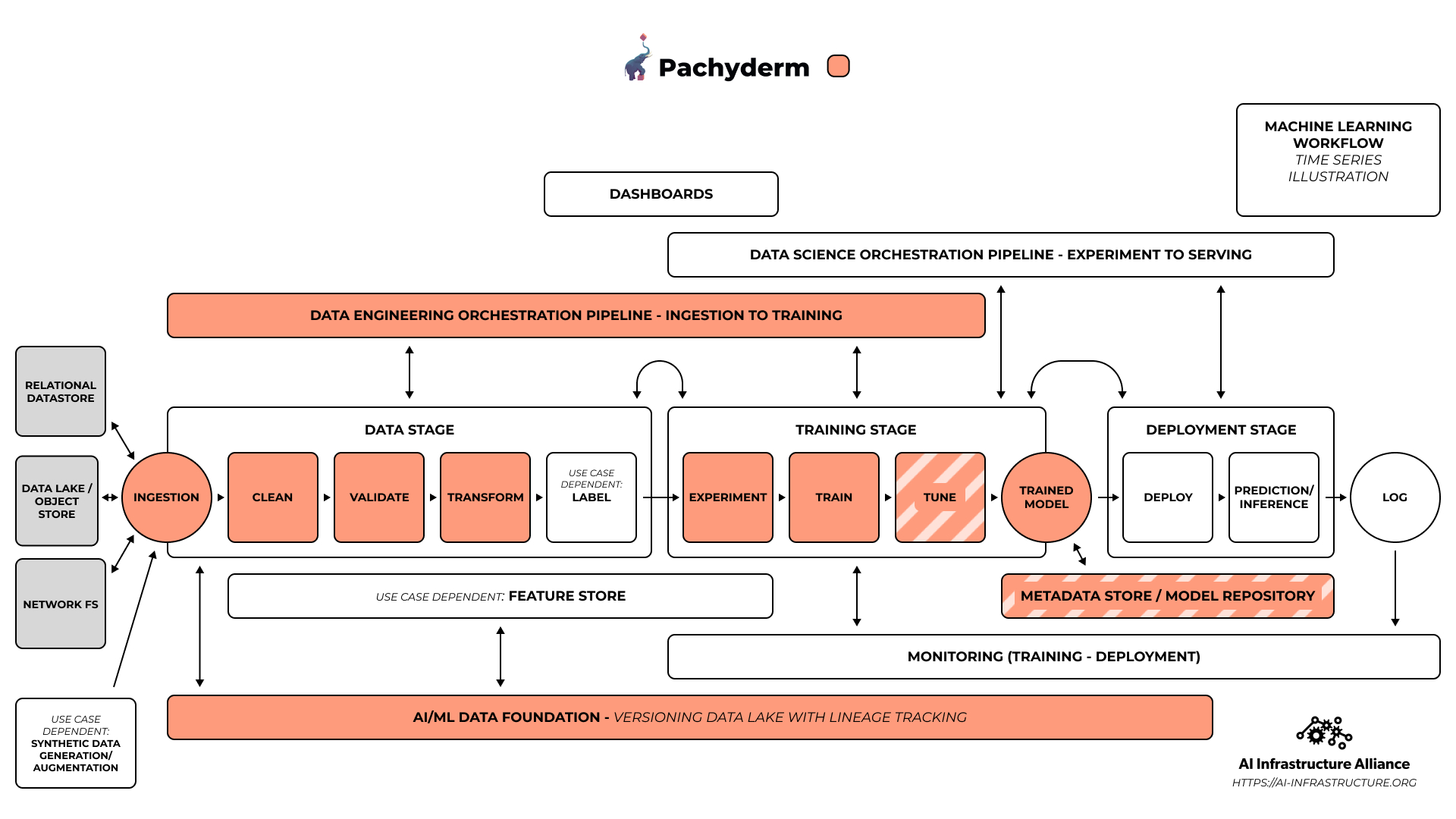
Take Pachyderm, a company I know well since I happen to work there in addition to acting as the Managing Director of the AIIA. In that three part post, Pachyderm got pigeonholed as “data versioning” but we’re also a robust data orchestration engine that takes you from data ingestion through training in the ML lifecycle. We can agnostically run any language or framework in that pipeline, something few other platforms can do. While most pipeline systems run only Python and maybe one other half supported language, we can run Python, Rust, C++, Bash, R, Java, and any framework or library you want, whether that’s Tensorflow, MXNet, Pytorch or the deep learning library you found on the MIT website last week.
Frankly, it’s partly a problem with Pachyderm’s messaging, which is why we recently upgraded it on the website. Navigating a company’s marketing is a challenge because marketing is, well, marketing. It’s hype and sometimes it gets in the way.
But that’s not the whole story. There’s a bigger problem at work here:
I call it the NASCAR slide.
The NASCAR slide comes to us from marketing. It’s the slide with logos slapped all over it like a NASCAR driver’s uniform.
In machine learning, that slide has completely destroyed people’s ability to actually understand what any of these companies do. You know the one. It’s got the 87 categories of machine learning with the 500 logos that fit neatly in each box.
It started in 2014-2016 with O’Reilly’s State of Machine learning series and it’s been replicating like a virus ever since.

It was relevant when the brilliant Shivon Zilis and her team did it at the time but if you look at that slide now, you’ll see it’s super out of date. These slides age horribly. Most of them are out of date almost the second they hit the press. Here’s a link to one from this year but I could point to a hundred different ones.
The biggest problem is that the categories are way too confining. Most companies’ software does multiple things. The AIIA companies have software that ripples across multiple stages of the AI/ML lifecycle. That will only accelerate as companies grow and take on more of the stack.
Plugging their logo into a neat little box makes no sense whatsoever.
That’s why one of the first big projects of the Alliance is working on blueprints to help people get a better grip on a real world enterprise AI/ML workflow.
Show Me the Blueprints
Take this early time series illustration from our working group as an example. It shows the AI/Ml workflow with boxes that match the amount of time we spend in each stage of the AI/ML dev lifecycle.
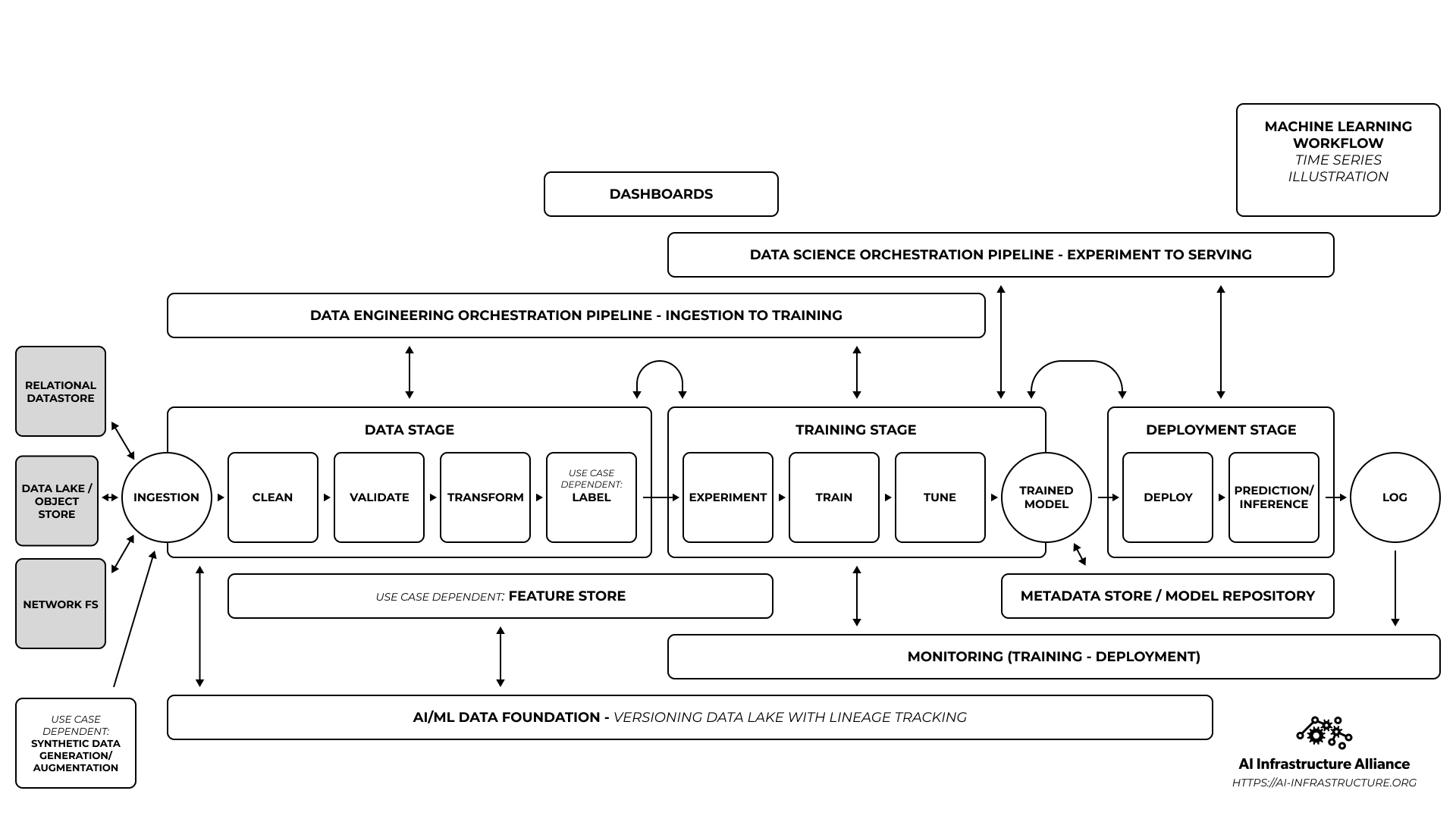
Where does AIIA company ClearML fit into that graphic? The answer is “multiple parts of the workflow,” which is why we’re using color to show how software ripples across the stages of the diagram.
![]()
What about a model serving framework like Seldon? Even they fit into different parts of the workflow, not just serving.
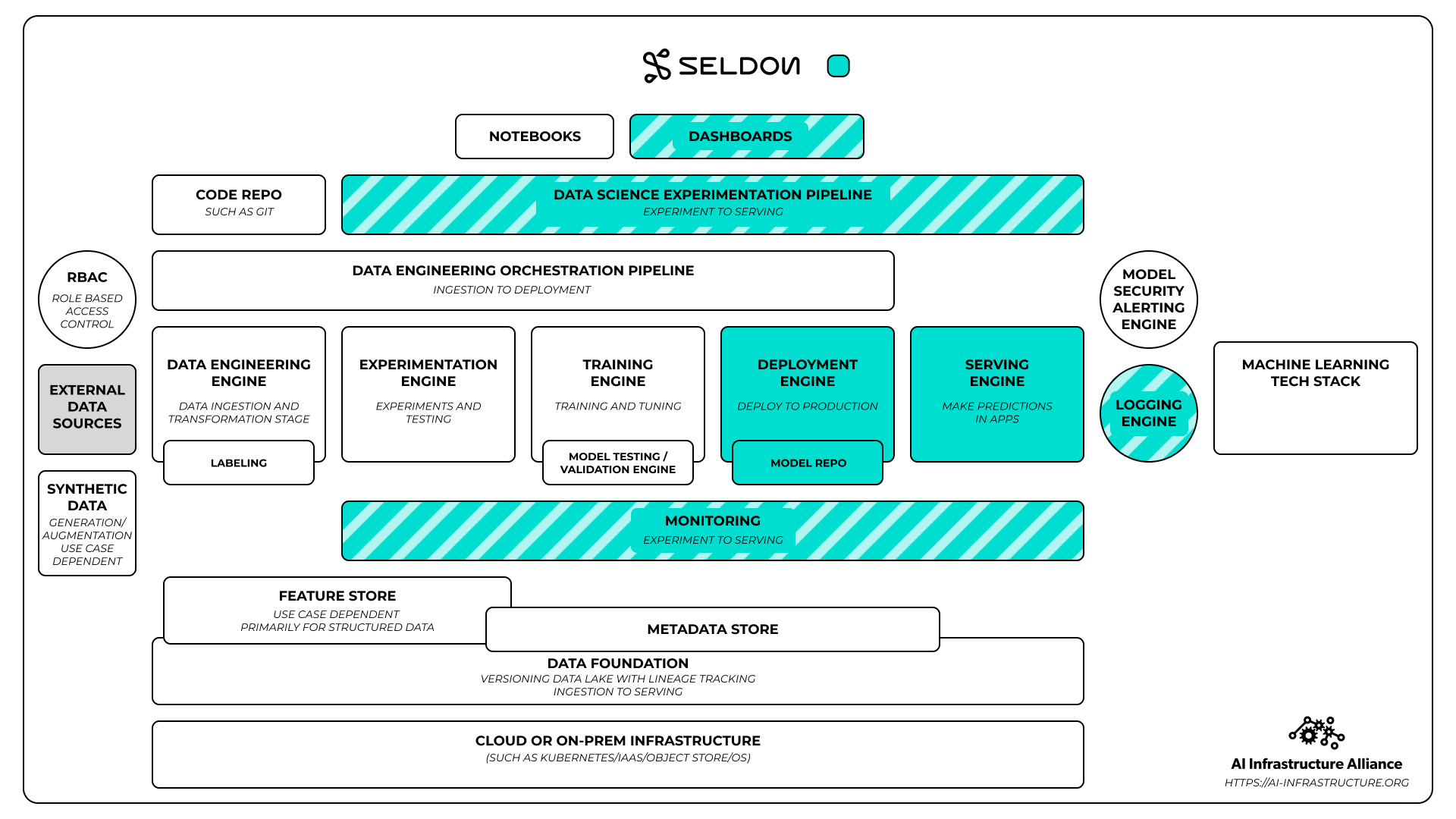
The partial coloring in the Seldon diagram shows where they do parts of what a total unified stack might do. While a full blown monitoring engine might cover experimentation all the way to deployment, a monitoring engine for the production side of the house is still essential.
And what about Pachyderm? If we’re not just data versioning, where do we fit?
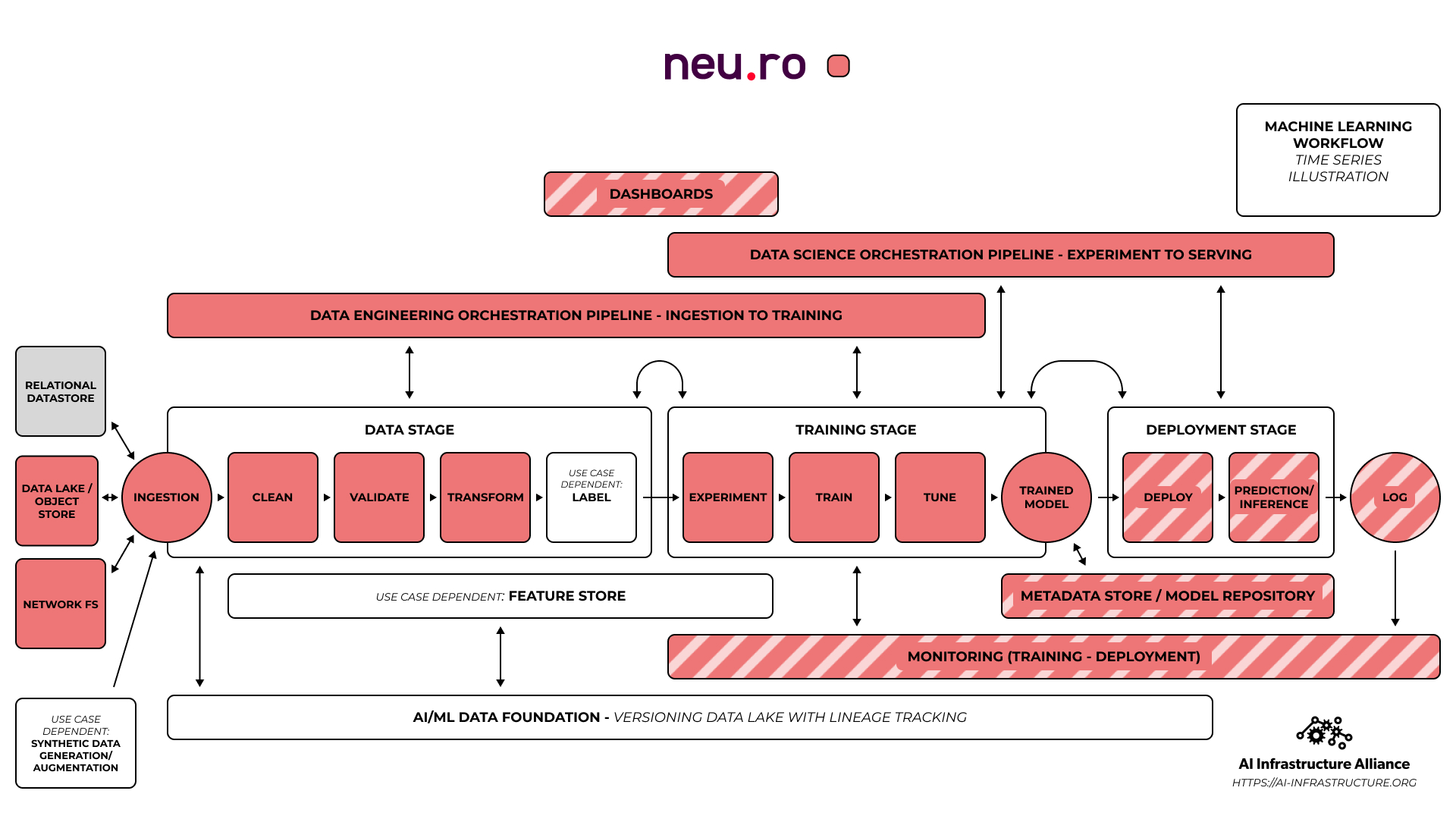
A company like Neu.ro is even more complicated to fit because they act as a glue framework for many different kinds of platforms. Think of them as an orchestrator of orchestrators rather than a software that tries to do everything itself.
 Of course no graphic perfectly captures every nuance of a stack and a workflow. As my friend Jimmy Whitaker likes to say, “all diagrams are wrong, some are useful.”
Of course no graphic perfectly captures every nuance of a stack and a workflow. As my friend Jimmy Whitaker likes to say, “all diagrams are wrong, some are useful.”
We’re looking to make the AIIA diagrams a lot less wrong so everyone can use them as a common visual language in this fast-developing space. Our diagrams are open source so everyone can build on them and modify them to their own needs and we’ll release them on the website when they’re out of beta.
I’ll consider the AIIA a roaring success if we kill the NASCAR slide forever.
The Architecture of Tomorrow
But where are we even getting these architectures? How are we putting them together in the first place?
To start with, we’re looking at what each company in the AIIA does. We’re getting demos from the founders. What are they building and why? What did they bet their futures on? How does it all weave together into a seamless AI fabric?
We’re also studying the architectures from cutting-edge companies, like Lyft’s and Google’s and Uber’s. We’re reading the papers and the blogs that break down the architectures. How is Google’s SEED RL system different from Deep Mind’s Acme RL system?
But we can’t just assume that whatever big tech puts out is fully backed and ready to go for the rest of us. We have to ask questions.
- What works?
- What doesn’t work?
- What makes sense and what doesn’t?
- What’s missing?
We can’t just assume they got it all perfectly correct and fully baked from the jump. The big tech companies are smart but that doesn’t mean they figured it all out on the first try. It took Google ten years before they got to Kubernetes and they built two other solutions along the way, Borg and Omega.
Already we’ve noticed a number of easily missed problems with a lot of the architectures coming out of Google and other big innovators in the space. Take a look at this diagram that people often cite from Google’s MLOps docs:
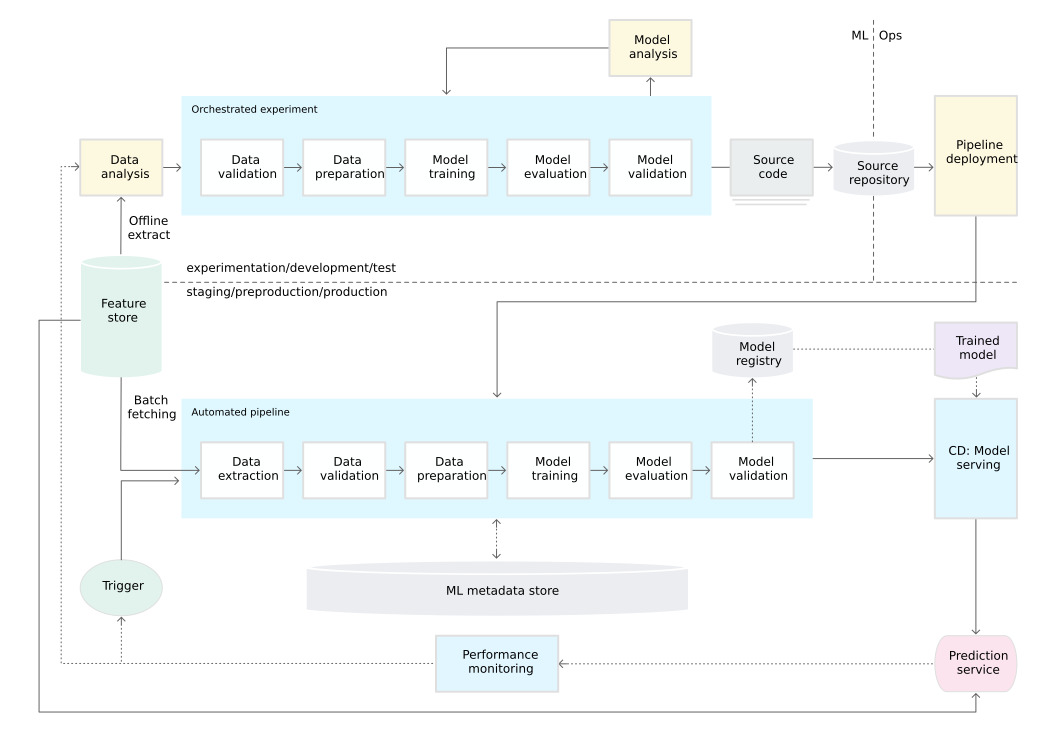
What’s missing?
Data.
Where are they storing the data? What kind of system are they using to access that data? How do they control access and version it?
They don’t include a storage and data versioning layer at all. The diagram picks up at “data extraction” assuming you already have data storage and scaling perfectly handled.
Why?
Because Google has a planetary scale file system that spans data centers and they have unified RBAC to get to that data. They can take that as a given in their stack. You can’t do that if you work at most companies.
Most companies have a mish mash of systems developed over many years, with different RBAC and different standards and formats. Half the work of the data engineer is just trying to navigate that RBAC minefield and get that data into a format data scientists can use to do their work.
Of course, our diagrams make assumptions too. The time series diagram is very linear and AI/ML workflows are often branching, like a DAG, and/or looping, aka the Machine Learning Loop. Our diagram has some curved arrows to show you some of the loop-y nature of machine learning but it’s not a perfect representation.
It’s even a bit of a misnomer to call things “pipelines” in our diagram because it implies that you put something in one end and something comes out the other end finished, like a factory ingesting metal and outputting paperclips. But machine learning models are never really done. There’s a continual learning cycle that happens as new data comes in and the model updates its understanding of the world and the new model gets deployed to production and the old model gets sunsetted.
One of our working group members, Larysa Visengeriyeva, drew this diagram that captures the looping nature of the workflow much better than a linear diagram and we’re working to turn this into a final graphic that matches the rest of the stack.
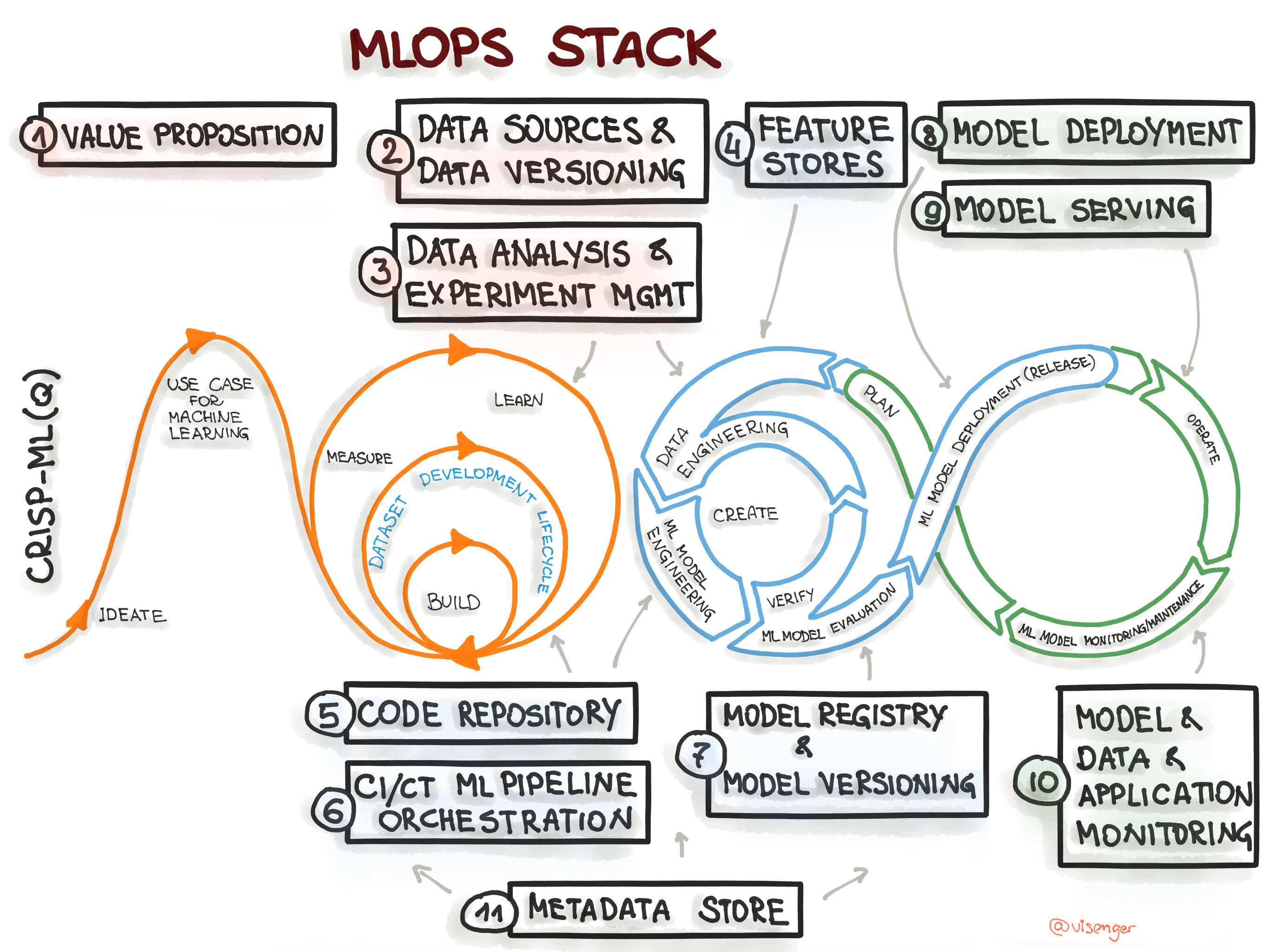
Still, that doesn’t make the time series diagrams wrong. It just shows something different. It’s about focus and where we want to draw attention.
In the next diagram we focus purely on the tech stack itself and not the workflow. This is an early draft of emerging patterns we’re seeing across the 50 members of the AIIA.
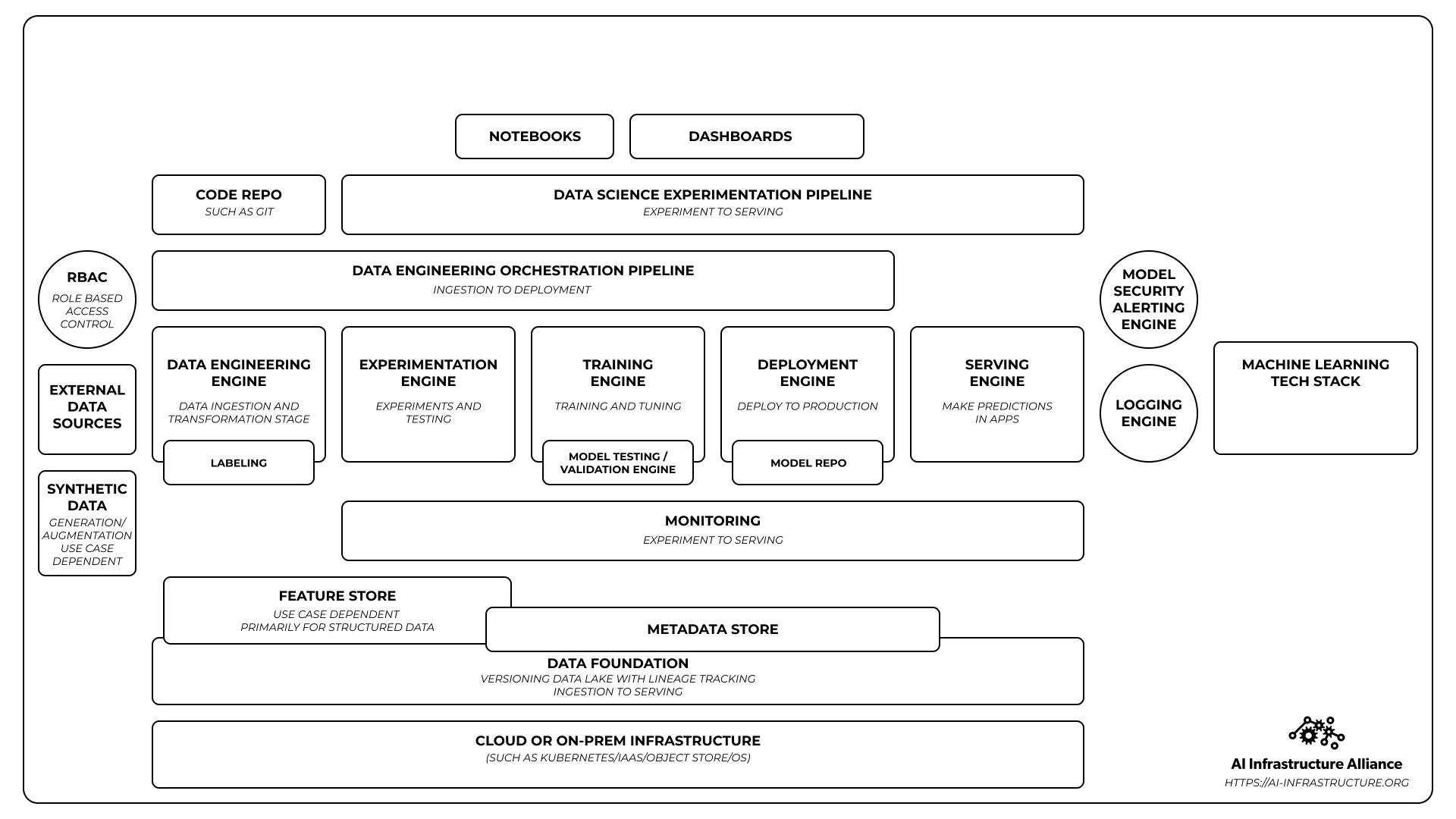
It shows the tech only, not what people are doing across it. Think of it the same way you think of a stack diagram of a web server, database server, and load balancer. It doesn’t show the app on top of it or how the programmer writes code and rolls it out.
It also doesn’t show boxes that you can stuff logos into easily. Just like the time series illustration a company’s software might flow across multiple components of the tech stack.
A company like Comet would surge across multiple layers of this stack like you see in the color coded version below.
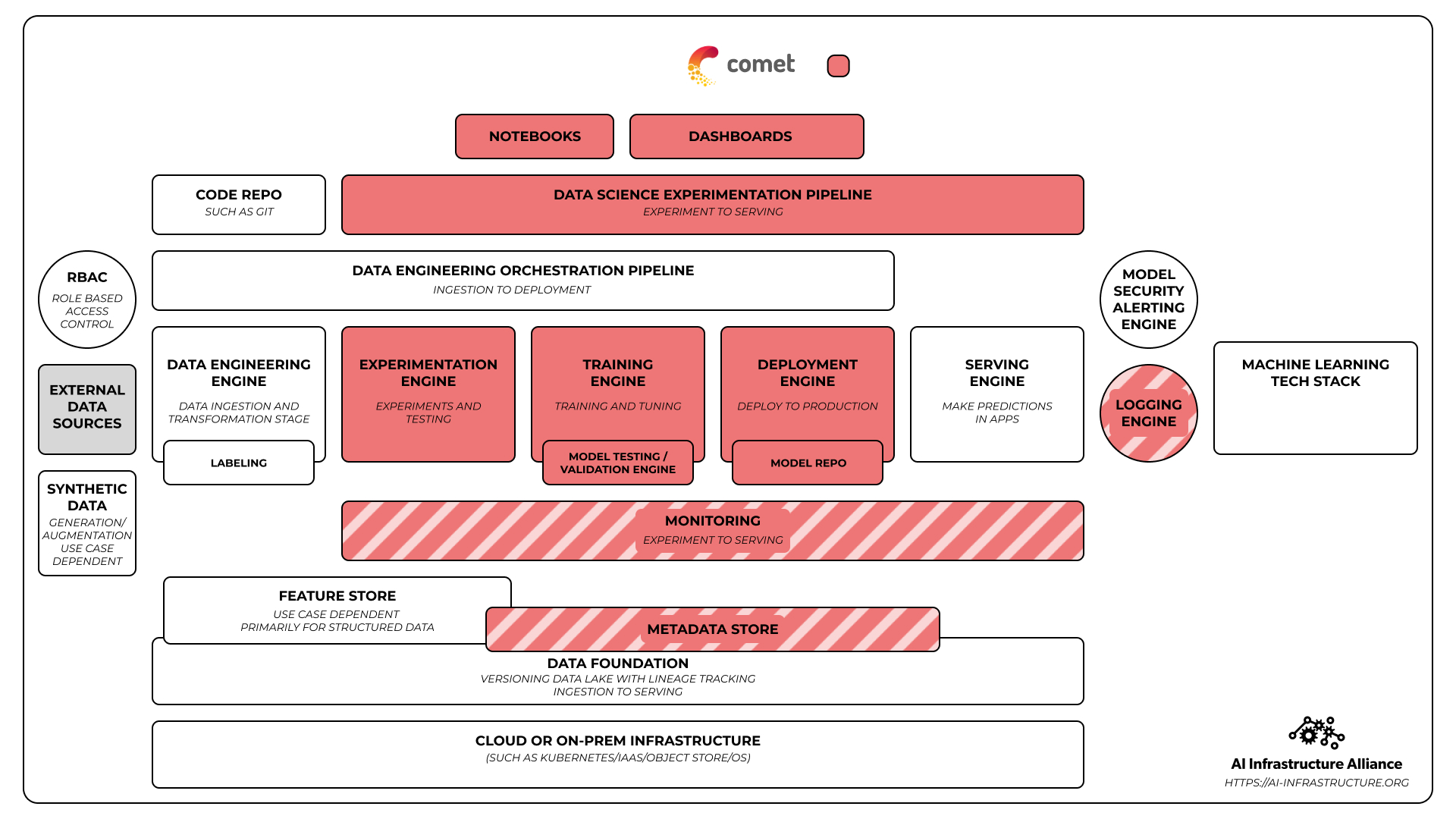 A highly tuned monitoring and explainability engine like Fiddler would concentrate on the monitoring, metadata, logging and alerting sections.
A highly tuned monitoring and explainability engine like Fiddler would concentrate on the monitoring, metadata, logging and alerting sections.
Every company in the AIIA will get their own stack diagram they can work with and color code to their own needs, one they can expand with time as their software evolves. Nobody’s software is set in stone. It’s constantly evolving and changing. It’s not just about fitting into the stack, it’s about evolving the stack to make it more universal and powerful with each passing day.
We’re using color to show how you could combine different software platforms to build a state of the art machine learning stack that works for multiple use cases with ease. The stack below combines Pachyderm, Algorithmia, ClearML and Tecton into a unified stack and it’s even got a clever acronym, the PACT stack.
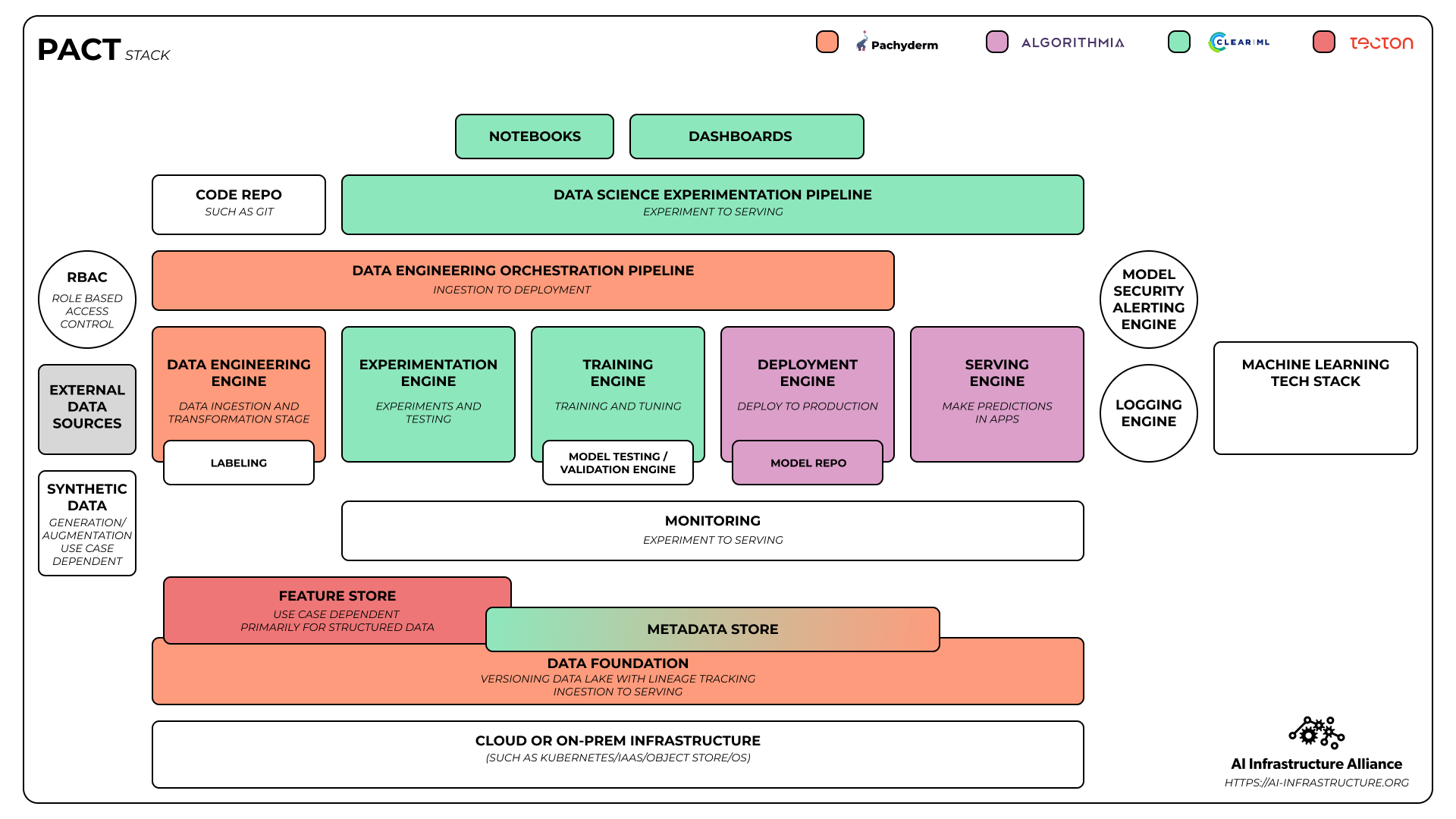
But we’re not worrying too much about clever acronyms for now. Sometimes you add a company and it doesn’t make for a memorable naming convention but it still makes for a powerful stack combination. If we add Fiddler’s state of the art monitoring and explainability to the mix, we have the PACTF stack that covers 90% of what any enterprise needs to run machine learning at scale.
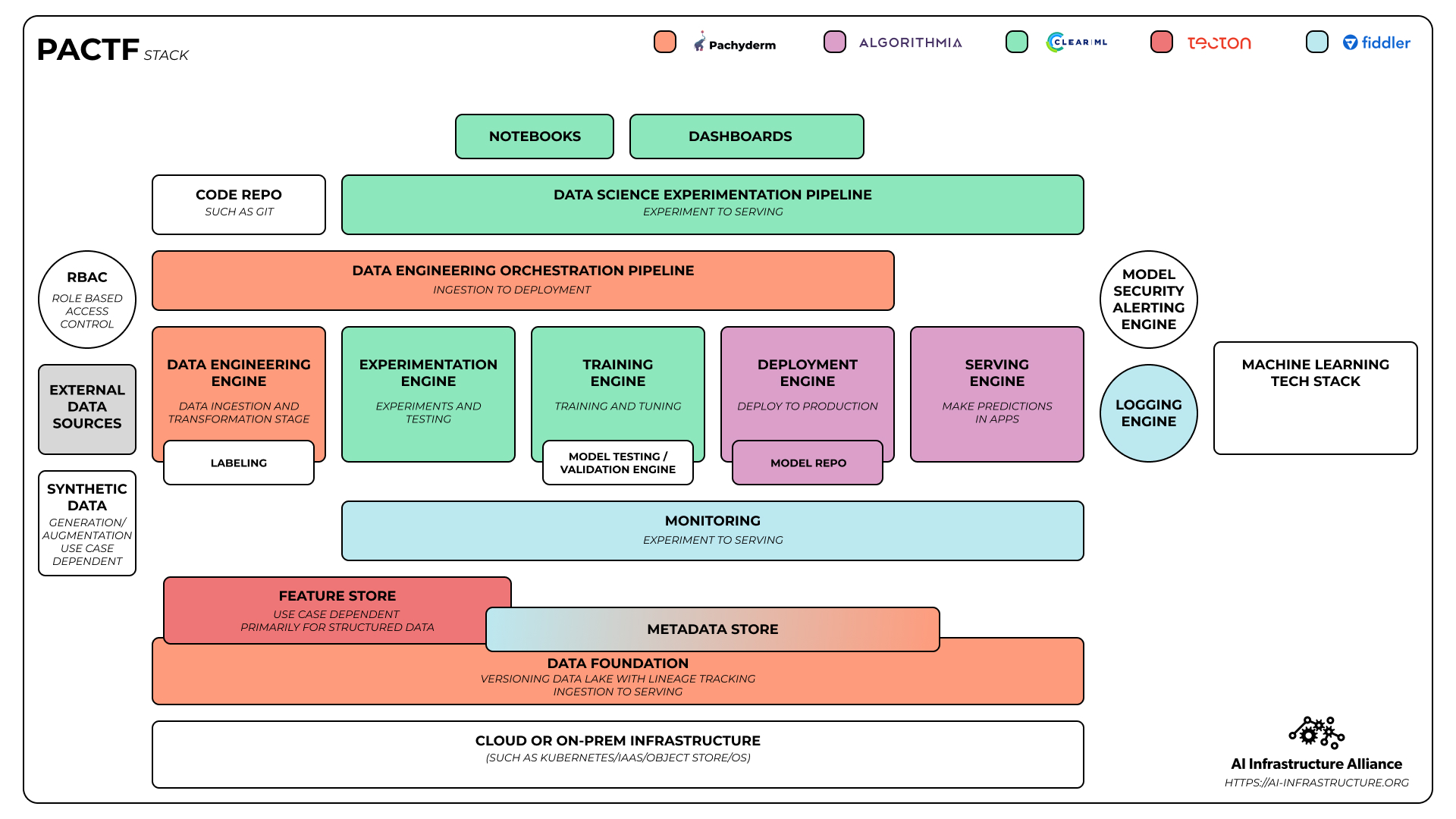
You can combine the companies in a number of ways. Some will take more integration than others but over time, as the AIIA members work more and more closely together, they’ll have better and better endpoints that work together with clean handoffs.
The blueprints and the common visual language are just the first stage of the AIIA. Beyond blueprints and trying to make sense of all the companies out there and what they do, we’re also looking to house technical projects under the AIIA banner.
The Projects of AIIA
When it comes to technical projects we have a different approach to something like the Linux Foundation’s AI and Data, which has sponsored some awesome projects like Horovod and others. We’re laser focused on glue frameworks, deployers, day 2 operations, and interoperability rather than duplicating functionality that our members already deliver.
The AIIA doesn’t need to sponsor another open source feature store. We have more than three feature stories already, like Tecton, which came out of the team’s work at Uber, or Molecula which has multiple patents, and Iguazio‘s which can even store unstructured data. We want the frameworks that weave them all together into a comprehensive system or makes talking to any feature store easier. We don’t need another model deployment project because we have Seldon and Algorithmia. We don’t need more explainability because we have folks like Arize AI and Fiddler.
Several of our members do focus on interoperability as a reason for being, like Neu.ro, and we want more of that on our roster too.
It’s hard to predict which glue framework will actually win the day, so we don’t worry about it. Let time, developers and the market figure it out. Our job is to bring as many of them to the table as possible and get them talking and working together. Collaboration is the key.
Currently, we’re talking with the following projects as potential AIIA projects:
Combinator.ml uses Terraform to quickly spin up multiple solution stacks for testing, experiments and demos. The Combinator team would love to introduce it to your team and have you build a deployer for your solution. Eventually we will host all these on the AIIA website so anyone can demo different platforms in combination with other platforms, something like DagsHub + Superwise + Algorithmia or any combination you can think of now and in the future.
SAME: This project comes to us from Dave Aronchick’s team. It looks to provide a simpler interface to complex projects like KubeFlow, in the way Keras simplified Tensorflow.
MLRun: This one comes to us from the Igauzio team. It looks to abstract the way AI/ML platforms communicate with each other and it’s one of the more advanced we’ve seen so far.
JuJu: Canonical‘s JuJu framework (think of it as a Kubernetes operator of operators) lives outside of AIIA but Canonical’s team is starting to build out a prototype AIIA stack as a pilot, with the hopes of expanding to all our platforms in the coming year.
More will join the fold over the coming year after we’ve finished the hard work of turning the Alliance into a foundation.
The Future and Beyond
In the long run we’re looking to deliver the Kubernetes of ML, something that abstracts away all the concepts and communications between different layers of any kind of complex AI/Ml stack people can dream up.
We want an abstract AI/ML factory that’s plug and play.
You might think that’s something like Kubeflow but Kubeflow is more of a pipelining and orchestration system that’s not really agnostic to the languages and frameworks that run on it. It supports mostly Python. It recently supported R but if the developers have to support every language and framework and library by hand that’s not going to be the orchestration engine we’re looking for in the future.
Even more, we want something that works more the way Kuberenetes itself does. Kubernetes doesn’t know what applications are running but it knows how to run them perfectly. It lets you run any kind of application that you can dream up on top of it. We want the same for AI/ML. The winning structure will let you abstract away various components and build a fast and flexible engine composite structure that works for any kind of AI we can imagine.
The system that everyone uses will be agonistic to the language, the frameworks, and the tools that run on it. If you want to run R, or Rust, or C++, or two different versions of Anaconda, mixed with MXNet and Pytorch and an experimental NLP library you just found, you should be able to do it with ease and without having to wait for the team to support it.
That’s why we’re looking for agnostic orchestration systems, clean API layers, and well-defined communications standards.
What about big, vertically integrated stacks like Amazon SageMaker and Google’s Vertex AI?
We welcome the cloud vendors into the Alliance as the representatives of the global operating system of the world. This is a big tent and we want everyone’s help. Their platforms will always make money and many teams may find that SageMaker is all they need. But in the long run we believe the stack that everyone uses in the future will be open and cross-platform.
Kubernetes didn’t become Kubernetes because it only ran on Google.
There were dozens of other container orchestration frameworks out there but Kubernetes proved to be the most flexible and agonistic and the other ones slowly died off.
Big vertically integrated AI/ML solutions have an early advantage. They have great programmers and they can design a prettier front end. Open systems and frameworks start out a bit uglier and messier. They take time to come together.
But over time those engines eventually outpace the proprietary frameworks and the proprietary vendors end up ripping and replacing their home grown solutions for the open solutions. That’s what happened with VMWare. They originally built their own container orchestration framework but you wouldn’t know it from their website now because they’ve pivoted 180 degrees and fully embraced Kubernetes like everyone else.
When a company’s marketing shifts to make you believe they’ve always been 100% behind a solution they originally tried to destroy, you know you’ve won.
Does anyone really think Amazon’s feature store will win out over FEAST or Tecton or Molecula? We don’t think so and when Amazon rips and replaces their feature store with one of the feature stores in the AIIA we’ll know we’ve really succeeded.
Then we’ll have a new mission. We’ll move “up the stack” to the generation of software that sits on top of the AIIA stack.
When 35 engineers built WhatsApp and reached 400 million people, they built it on the back of pre-baked GUIs and transport layer security standards and messaging protocols and more. Eventually we’ll have to move up the stack too. But when we do, we’ll have solved the first major challenge in this rapidly evolving AI/ML space. We’ll keep evolving as the times change and the needs of our people change.
Machine learning is one of the most powerful technologies on the planet but to unleash its true world changing potential we need a stack everyone can build on. Once we have it, we’ll have gone well beyond the Cambrian explosion of infrastructure software to an explosion of new AI driven applications that touch every industry on Earth.
Join the AIIA and you won’t just ride the winds of change.
You’ll shape them.