
By: Atindriyo Sanyal, Vikram Chatterji, Nidhi Vyas, Ben Epstein, Nikita Demir, Anthony Corletti
Abstract
The quality of underlying training data is very crucial for building performant
machine learning models with wider generalizabilty. However, current machine
learning (ML) tools lack streamlined processes for improving the data quality. So,
getting data quality insights and iteratively pruning the errors to obtain a dataset
which is most representative of downstream use cases is still an ad-hoc manual
process. Our work addresses this data tooling gap, required to build improved ML
workflows purely through data-centric techniques. More specifically, we introduce
a systematic framework for (1) finding noisy or mislabelled samples in the dataset
and, (2) identifying the most informative samples, which when included in training
would provide maximal model performance lift. We demonstrate the efficacy of
our framework on public as well as private enterprise datasets of two Fortune 500
companies, and are confident this work will form the basis for ML teams to perform
more intelligent data discovery and pruning.
Introduction
Machine learning is key to mission critical data-driven decisions across an array of applications. The primarygoalofmodeltrainingphaseisimprovingoverallmetricslikeF1andRMSE.Acommondata-centric technique to achieve this goal is adding more samples and features to the dataset. However, there are multiple issues with the over-use of this approach. First, the benefits of strictly increasing dataset sizes is uncertain. Instead, adding lesser but more informative samples to training or cleaning noisy samples from a dataset has provided significant model improvement Axelrod et al. [2015]; Dou et al. [2020]; Xu and Koehn [2017]. Second, training complexity increases exponentially when more features are added to the model viz. ‘curse of dimensionality’. This results in limited generalizability when using a fixed budget to add new samples.
A direct repercussion of such biased models in production is that of ‘model downtimes’, where the model makes frequent incorrect predictions. Debugging and alleviating these downtimes require large hours of manual effort. As the ML footprint of an organization grows, this process becomes increasingly untenable. This is where data-centric ML tooling for automatically detecting and surfacing these errors grows considerably.
Many machine learning teams across industries agree that data quality is the key to produce more robust and generalizable models. Yet, there is a lack of streamlined tools and processes to automate data cleaning workflows (i.e. to prune out noisy samples), and optimizing data labelling for fixed budget scenarios (i.e. to selectively add most informative samples). Instead, the common approach is largerly ad-hoc, leading to enormous waste of human capital during the process of uncovering causes for poor model performance.
The goal of our work is to provide a framework which uses systematic data-centric methods to improve data quality across the ML workflow, thereby improving model performance. The first approach automatically identifies labelling errors in a given dataset. We provide a data-dependent and a data-independent approach to surface these noisy labels. The second approach identifies most informative samples in an unlabelled set, which can be used for training a model to achieve maximalmodelperformancelift. Thisapproachcanimprovemodelrobustnesswithminimallabelling effort/budget. Our work can produce higher quality models, smaller but better quality datasets (saving model training time), quicker but informed dataset labelling (saving annotation cost).
To demonstrate the overall adaptability of our framework, we provide results for text classification on two public and two private enterprise datasets. Our methods achieve significant improvements over baselines, and are a proof-of-concept for practical dataset engineering using data-centric techniques for producing and maintaining high quality models in production.
2 Improving ML Dataset Quality
Data labelling is a laborious and expensive process. Enterprises that have terabytes of unlabelled data often need to optimize for labelling a subset of data that will achieve the largest performance lift. Since it involves significant human intervention, these labels can still be susceptible to many errors1. In this section, we describe two data-centric methodologies employed to identify errors in ground truth data, and a subset of informative samples for maximal performance lift.
2.1 Identifying Labelling Errors
Model based confidence-certainty metric is a data-dependant approach derived from prior work on Dataset Cartography Swayamdipta et al. [2020], and automatically identifies noisy/mislabelled samples from a dataset. Our variation to prior work combines prediction probability of ground truth and overall prediction distribution across labels to score every sample in the dataset. More precisely, we use model confidence (), where i is the prediction probability of ground truth, and model certainty (), where i is the difference between the prediction probability of argmax and next argmax (i.e. margin distribution) for a sample xi. captures how confident the model is while predicting ground truth and captures how certain the model is while making a prediction. Unlike Swayamdipta et al. [2020], we only use scores from the penultimate epoch of training. For each training sample xi, we first compute i and i and then partition the data into segments of high/low confidence-certainty scores. The 90th percentile of datums from the least confident and most certain score range are marked as noisy/mislabelled.
Model based certainty metric is a data-independent approach derived from prior work on Confident Learning (CI) Northcutt et al. [2021]2, and automatically learns a class-conditional joint distribution (Q) between provided dataset labels (assumed noisy) and the latent labels (assumed uncorrupted), to identify noisy samples. This approach presumes each class may be independently mislabelled as an incorrect class with a probability that is data-independent. At inference, Q is used to compute a model certainty () score for every sample, and the top 90 percentile with highest scores are marked as noisy/mislabelled.
Both approaches described above are highly generalizable across other domains as they require minimal code-injection to the underlying model and the associated loss function is kept unchanged. However, scaling and automating them in real-world applications is still a challenge (refer §4).
2.2 Identifying Most Informative Samples
In production workflows, it is computationally impractical to use traditional active learning strategies that select a single sample at each step, and retrain the model each time. This approach uses prior work of Core-set Sener and Savarese [2018], where given a fixed annotation budget, the goal is to select a batch subset of B samples that would provide maximal model performance lift. More precisely, the geometry of datapoints is used to pick K well-distributed cores, and these cores are then used to pick B samples. The approach optimizes picking a subset that will be competitive for the remaining datapoints. So, given an initial set of samples and their embeddings, core-set selection returns a subset of samples that should be used to expand the training data.
3 Experiments and Results
We validated our framework on text classification using public (Newsgroup203 and Toxicity4) and private enterprise (two Fortune 500 FinTech company) datasets. All datasets are multi-class, except Toxicity dataset which is two-class. We add a top-layer to a pretrained DistilBERT model from Hugging Face for all our experiments5and fine-tune using early-stopping (min delta 0.001 on training accuracy).
A. Identifying Labelling Errors: We manually induce 10% noise by randomly flipping labels in the two public datasets (i.e. setup similar to Swayamdipta et al. [2020]). For private enterprise datasets (which correspond to real-world production data), we re-labelled the samples via MTurk6, and found labelling errors in 5% and 33% of the input data, respectively. We observed that samples in the lower confidence and higher certainty region are further away from decision boundary, and correspond to hard or mislabelled training samples. The model found it difficult to learn from these samples potentially because they are noisy (refer Table 1 for examples).
As shown in Table 2 (left), both methods are very efficient at finding mislabelled samples. Since certainty-metric adopts a data-independent approach, it outperforms confidence-certainty-metric on public datasets where the labels were randomly flipped (and are independent of the underlying samples). Anotherexpectedoutcomewaslowergainsonprivatedatasets,mainlybecauseasystematic human mislabelling error is harder to identify than artificial random noise. Since such errors are more data-dependant, we hypothesize that confidence-certainty-metric will outperform other method.
B. Identifying Informative Samples: We used the Toxicity multilabel dataset and trained a baseline model on 3 sets of 1000 initial seed samples: randomly sampled, selected from the decision boundary, and selected furthest from the decision boundary. Next, we employed three different strategies to label and expand this training data (1) Random sampling where we pick new samples randomly without replacement (2) Certainty based sampling where we use the baseline model to pick the batch of samples with highest certainty scores (3) Core-set based sampling where we use the baseline model to extract embeddings and use core-set recommendation to pick top candidates. Note, for this experiment, we set the annotation budget to 300 samples, so the final bench-marked model is trained on 1300 training samples.
As shown in Table 2 (right), both core-sets and certainty based methods perform better than random sampling. Core-sets outperform certainty when the initial seed samples were selected away from decision boundary (or at random) and did not include important support vectors that determine the overall decision boundary. By the virtue of this method, we are able to select more diverse samples that capture the support (see Figure 1 (right)). More generally, certainty based approaches select multiple samples from the same region (see Figure 1 (middle)) and so the model misses out on insights that a core-set would discover from its broader coverage. Given equal performance lifts between these two methods, core-set provides the benefit of a more diverse selection and thus perhaps a more robust model.
4 ML Data Observability in Production
Identifying informative samples and labelling errors are just two out of many other problems and challenges which fall under the umbrella of ML Data Observability. In practice, implementing these techniques have many challenges, and we discuss one potential solution in this section.
Over the last few years, parts of the ML infrastructure pipeline have been standardized such as feature stores Orr et al. [2021] and model SDKs, which enable engineers to build and maintain ML models with ease. As a result, there has been an explosion of models being trained and deployed for various business applications. Yet, errors in real-time production data is extremely common due to lack of robust data quality solutions. For instance, there is no standard set of libraries that provide theoretical guarantees, and most workflow systems provide tooling for monitoring model level metrics, which is not sufficient for guaranteeing robust models. In addition, present-day approaches to data observability is highly manual and requires significant engineering
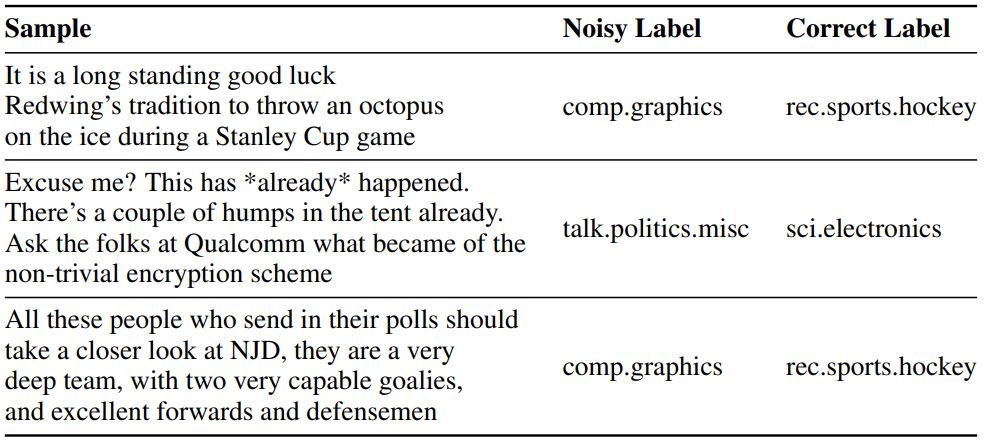
Table 1: Top mislabelled samples picked by confidence-certainty method
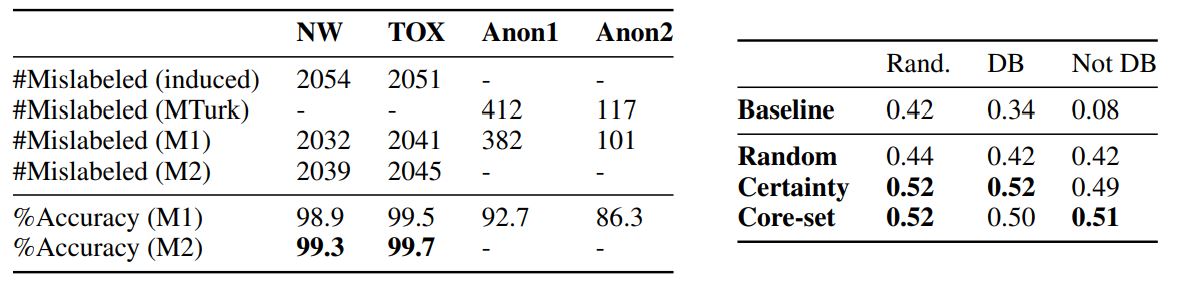
Table 2: Results: (Left) identifying dataset labelling errors (Right) identifying most informative
samples (NW=Newsgroup20, TOX=Toxicity, Anon1 and Anon2 are private enterprise datasets;
M1=confidence-certainty method, M2=certainty method, Rand=Random, DB=Decison Boundary)
An API-first approach could be one way to provide this required tooling for implementing such data centric approaches quickly. Such an approach would provide easy integration with existing bespoke MLinfrastructureworkflows, andallowMLpractitionerstotrainmorerobustmodelsquicklythrough key data-centric insights allowing companies to iterate quickly on improving models and reduce potential bias in data points.
For ML organizations to succeed, it’s critical to bake data quality into their ML ecosystems. As models become more pervasive, it becomes harder to know when things go wrong; be it at the model, data or systems level. So, automating data quality using data-centric techniques is key to root-causing and solving these issues, ensuring models run at high quality consistently in production.
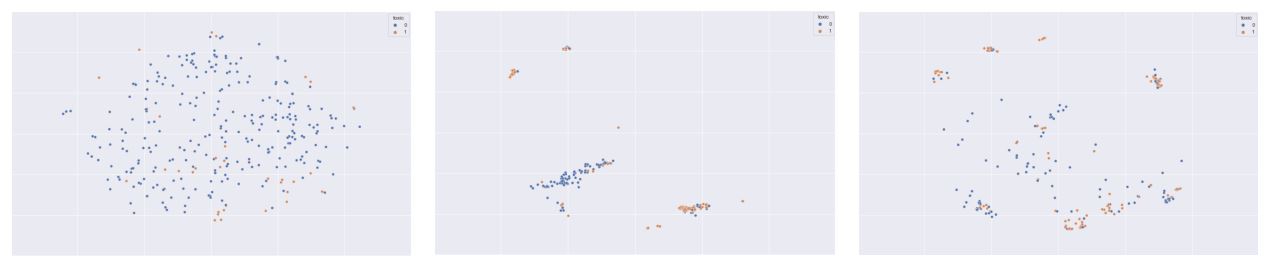
Figure 1: Samples picked by random sampling (Left) certainty sampling (Middle) core-set sampling
(Right) across unlabelled data. Note the unseen cluster core-set captures in the upper-right corner.
Acknowledgments
We acknowledge the support of Stanford AI Lab (SAIL) for their useful feedback and discussions that helped improve this work.
References
Amittai Axelrod, Yogarshi Vyas, Marianna Martindale, and Marine Carpuat. Class-based n-gram language
difference models for data selection. In Proceedings of the 12th International Workshop on Spoken Language
Translation: Papers, Da Nang, Vietnam, December 3-4 2015. URL https://aclanthology.org/2015.
iwslt-papers.9.
Zi-Yi Dou, Antonios Anastasopoulos, and Graham Neubig. Dynamic data selection and weighting for iterative
back-translation, 2020.
Curtis G. Northcutt, Lu Jiang, and Isaac L. Chuang. Confident learning: Estimating uncertainty in dataset labels,
2021.
Laurel Orr, Atindriyo Sanyal, Xiao Ling, Karan Goel, and Megan Leszczynski. Managing ml pipelines: Feature
stores and the coming wave of embedding ecosystems, 2021.
Ozan Sener and Silvio Savarese. Active learning for convolutional neural networks: A core-set approach, 2018.
Swabha Swayamdipta, Roy Schwartz, Nicholas Lourie, Yizhong Wang, Hannaneh Hajishirzi, Noah A. Smith,
and Yejin Choi. Dataset cartography: Mapping and diagnosing datasets with training dynamics, 2020.
Hainan Xu and Philipp Koehn. Zipporah: a fast and scalable data cleaning system for noisy web-crawled parallel
corpora. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing,
pages 2945–2950, Copenhagen, Denmark, September 2017. Association for Computational Linguistics. doi:
10.18653/v1/D17-1319. URL https://aclanthology.org/D17-1319.
This blog has been republished by AIIA. To view the original article, please click HERE.
Recent Comments